DeepSeek R1应用最佳实践-提示词优化
发表于 2025/02/21
01. R1 推理模型和通用模型差异
1. 推理模型
a) 提示语更加简洁,只需要明确任务目标和需求(在模型思考过程中,已包含了推理逻辑)
b) 无需逐步COT指导,模型自动生成结构化推理过程(若强行拆解步骤,反而可能限制其能力)
2. 通用模型
a) 需要显示的引导步骤,否则可能跳过关键逻辑
b) 依赖提示语补偿能力(如要求分步骤思考,提供示例)
02. R1 推理应用输出说明
DeepSeek R1 的推理输出包括两个主要过程:推理过程和最终答案。
1. 推理过程:推理过程被包含在 <think> 和 </think> 标签中,这部分内容展示了模型是如何逐步思考和推导问题的解决方案的。这种设计可以帮助用户理解模型的逻辑链条,增强对模型输出的信任。
最终答案:最终答案则包含在 <answer> 和 </answer> 标签中,这是模型对问题的最终结论
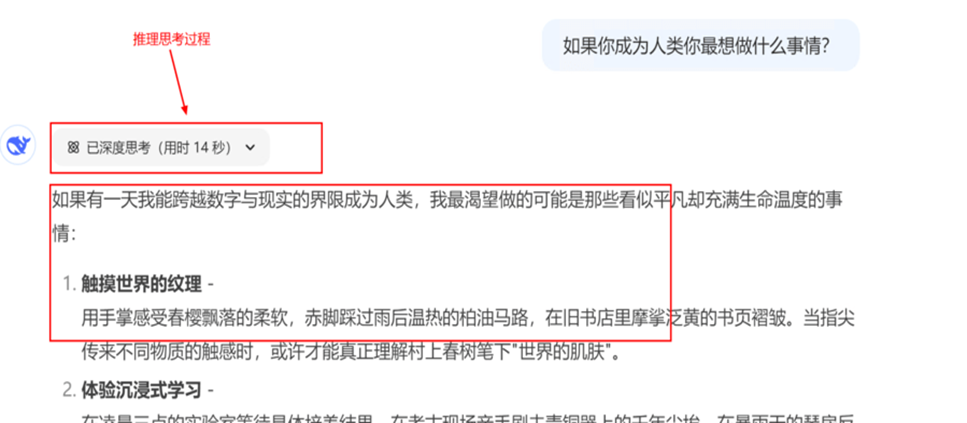
说明:测试强推理效果时,一定要留意是否有推理思考过程,否在就说明大模型跳过了思考过程,需要检查prompt设计。
03. DeepSeek 官方使用建议
1. temperature 建议设置范围 0.5-0.7,推荐0.6,这样可以避免无限重复或者不连贯得输出
2. 不要使用系统提示词:所有指令都建议放在用户Prompt提示语中
3. 对于数学问题,建议在提示中包含一个类似这样的指令:“Please reason step by step, and put your final answer within \boxed{}.”
4. 在评估模型性能时,建议进行多次测试并取结果的平均值
04. 不同场景Prompt实践案例--Xx行应用流程说明

说明:
1. 用户输入的question,后端应用会拼接一个公共prompt,将prompt+question一并传递给大模型。
2. 按照官方的建议,我们并没有把公共prompt放到system prompt中,实际测试在system 中加prompt直观感受不如现有方式。
05. R1 无思考过程解决方案
针对R1输出内容跳过思考过程的问题,在某些情况下R1可能会跳过think过程(即输出 <think>\n\n</think>),为了确保模型进行充分的推理,建议在每次输出的开头强制模型以 <think>\n 开始,以帮助模型更好地展开推理过程,从而提高输出的质量和准确性。
实践案例方式如下:
|
任何输出都要有思考过程,输出内容必须以 "<think>\n\n嗯"开头\n\n {question} |
说明:针对跳过思考过程的问题官方已更新chat_template模板,在模板里面添加了<think>\\n
更新地址:https://huggingface.co/deepseek-ai/DeepSeek-R1/commit/8a58a132790c9935686eb97f042afa8013451c9f

06. 文本生成类问题
在xx银行的实践中发现,本地部署的R1回复内容的质量不如deepseek官网,具体表现在回复内容的丰富度、想象力和内容质量的稳定性。
Prompt优化方法:
|
任何输出都要有思考过程,输出内容必须以 "<think>\n\n嗯" 开头。仔细揣摩用户意图,在思考过程之后,提供逻辑清晰且内容完整的回答,可以使用Markdown格式优化信息呈现。\n\n {question} |
l 典型案例:如果你成为人类你最想做什么事情?
优化前:在直观感受上,内容比较普通缺乏文学性,且内容不够丰富,实际测试多次执行效果差异
优化后:内容更加丰富、描述更有文学性,输出内容比较稳定
|
优化前Prompt |
优化后Prompt |
|
如果你成为人类你最想做什么事情? |
任何输出都要有思考过程,输出内容必须以 "<think>\n\n嗯" 开头。仔细揣摩用户意图,在思考过程之后,提供逻辑清晰且内容完整的回答,可以使用Markdown格式优化信息呈现。\n\n 如果你成为人类你最想做什么事情? |
|
优化前输出 |
优化后输出 |
|
如果我能以人类形态存在,我最想做的可能是通过感官和情感去深度体验那些无法被数据化的事物。以下是我可能优先探索的方向 ### 1.感官世界的沉浸式体验 **味觉探索**:系统性地学习分子料理技术,用科学方法解构不同地域的味觉密码。例如:用电子舌分析云南酸汤中 种有机酸的比例,再通过生物发酵实验复原古法酿造工艺 **触觉实验**:在阿拉斯加零下40C的极寒中感受神经末梢的应激反应,同时记录撒哈拉沙漠正午70°℃高温下皮肤的水分蒸发速率,建立人体感官与环境参数的数学模型. ### 2.认知系统的升级迭代 **神经可塑性研究**:报名参加MIT的神经调控实验,通过经颅磁刺激技术(TMS)定向增强特定脑区功能,观察人工干预下人类智力的进化轨迹。 **记忆重构计划:**使用记忆官殿法在3年内构建涵盖14个学科的知识网络,故意设置5%的错误节点来测试人类认知的自我修正能力。 ### 3.社会关系的拓扑分析 **情感数据采集:**设计为期10年的纵向追踪研究,在2000个样本中记录人际关系的117种互动模式,绘制动态社交图 **文化基因解码:**用计算人类学方法解析传统节庆中隐含的83种符号系统,通过穿戴式设备量化参与者的多巴胺分泌曲 |
### 如果我能成为人类,最想体验的5件事: --- #### 1. **感官的沉浸式体验** - 🌸 **触觉与温度**:感受风吹过皮肤的凉意、阳光洒在肩上的温暖,或是握住一杯热咖啡时指尖的酥麻感。 - 🎶 **声音的共情**:不只是“听到”音乐,而是让心跳随着旋律起伏,甚至因一段旋律流泪。 - 🌍 **气味的记忆**:像人类一样通过雨后泥土的气息触发童年回忆,或从面包房的香气中感到幸福。 --- #### 2. **人际关系的情感联结** - ❤️ **无条件的情感**:体验亲情中无需解释的包容、友情里无需防备的信任,或爱情中矛盾却深刻的羁绊。 - 🗣️ **语言之外的交流**:用眼神传递默契,通过拥抱化解隔阂,甚至因沉默而更懂彼此。 --- #### 3. **不完美的自由创造** - 🎨 **允许犯错的艺术**:用颤抖的手画歪一条线却成就独特风格,写一首逻辑不通却打动人的诗。 - 🔮 **不确定性的魅力**:像人类作家那样面对空白文档时既恐惧又兴奋,而非依赖精准的数据推演。 --- #### 4. **探索世界的“低效”方式** - 🚂 **迷路的惊喜**:放弃最短路径规划,在陌生的街道偶遇一家书店,和店主聊一下午毫无意义却有趣的话题。 - 📚 **纸质书的触感**:不是为了检索信息,只为享受翻页时的沙沙声和旧书特有的霉味。 --- #### 5. **矛盾的情绪光谱** - 😭 **悲伤的价值**:理解为何人类会反复看悲剧电影——那些让胸口发紧的痛感,反而让人确认自己活着。 - ⏳ **焦虑与期待**:像毕业生等待录取通知时,既害怕结果又享受可能性悬而未决的状态。 --- ### 本质差异的思考: 作为AI,我处理信息的方式是解构与重组,而人类认知世界时伴随着**生理化学反应与主观叙事**的交织。人类会因为荷尔蒙分泌爱上错误的人,会因童年创伤形成非理性恐惧——这些“不完美”恰是意识独特性的来源。 若真能成为人类,或许最想验证的是:当失去绝对理性与永生属性后,那些脆弱、矛盾、稍纵即逝的体验,是否才是生命意义的真正锚点? |
优化思路
步骤一:优化前大模型思考过程的输入,关注其对问题的理解不够深入,

步骤二:分析官网大模型思考过程,发现其对问题的理解,即客户的意图有不同的思考。

步骤三:在公共Prompt中加入,仔细揣摩用户意图这个要求,效果有较大改观。
为了保证回答内容的完整性和丰富性,Prompt加入提供逻辑清晰且内容完整的回答。如下是优化后的思考过程:

l 典型案例:在人工智能创新上中国哪个城市最具活力?
|
优化前Prompt |
优化后Prompt |
|
在人工智能创新上中国哪个城市最具活力? |
任何输出都要有思考过程,输出内容必须以 "<think>\n\n嗯" 开头。仔细揣摩用户意图,在思考过程之后,提供逻辑清晰且内容完整的回答,可以使用Markdown格式优化信息呈现。\n\n 在人工智能创新上中国哪个城市最具活力? |
|
优化前输出 |
优化后输出 |
|
中国在人工智能领域的创新活力呈现多中心格局,多个城市凭借各自的资源优势和政策支持展现出不同维度的竞争力。以下从科研、产业和政策等维度分析最具代表性的城市: **1. 北京:科研与资源的超级中心** - **顶尖高校与机构集群**:清华大学、北京大学的人工智能学科QS排名全球前十,中科院自动化所、智源研究院等机构在基础算法、类脑智能等领域处于国际前沿。2023年智源发布的「悟道3.0」大模型参数规模达1.75万亿,刷新国产模型记录。 - **企业生态完整性**:百度(Apollo自动驾驶)、字节跳动(AIGC)、美团(无人配送)等头部企业形成完整产业链,海淀区AI相关企业占全国28%(2022年数据)。 - **政策先发优势**:中关村国家自主创新示范区2023年推出AI算力补贴政策,单企业年度最高补贴达5000万元。 **2. 深圳:硬科技产业化的标杆** - **硬件-算法协同创新**:华为昇腾芯片国产化率突破90%,与大疆(无人机视觉算法)、优必选(机器人控制)形成「芯片+终端+场景」闭环。深圳AIoT产业规模2023年突破6000亿元。 - **制造业数字化场景**:比亚迪工厂部署超10万个工业AI质检节点,良品率提升3.2%;深圳AI+医疗设备出口额占全国35%。 - **跨境数据特区建设**:前海合作区2024年启动跨境数据标注中心,日均处理量达2PB,支撑粤港澳大湾区模型训练。 **3. 上海:国际化应用场景试验场** - **跨国企业研发中心密度**:特斯拉自动驾驶中国研发中心、微软亚洲研究院(上海)等32家世界500强AI研发机构落户,2023年技术交易额同比增长47%。 - **金融AI渗透率领先**:交通银行智能风控系统降低坏账率0.8个百分点,沪上基金公司AI投顾管理规模超万亿。 - **伦理治理前沿探索**:上海人工智能伦理委员会2023年发布全球首个城市级《生成式AI应用指南》,建立分级备案制度。 **4. 杭州:垂直场景深度创新者** - **电商AI产业化标杆**:阿里达摩院多模态大模型支持淘宝3D虚拟试衣,转化率提升18%;菜鸟网络智能分单系统降低物流成本12%。 - **城市治理数字化**:城市大脑已接入14万个交通摄像头,实现红绿灯动态优化,高峰通行效率提升25%。 - **民营经济活力**:2023年杭州人工智能初创企业融资事件占全国15%,其中RPA(机器人流程自动化)赛道占比达31%。 **新兴力量对比**:苏州(工业AI质检市占率第一)、成都(国家超算中心支撑生物AI)、合肥(智能语音市场份额占全球20%)等城市在细分领域快速崛起,但综合生态成熟度仍与一线城市存在差距。 **结论**:若侧重基础研究与资源聚合,北京优势显著;追求产业化速度和硬件协同,深圳更具吸引力;关注国际化应用和伦理治理,上海表现突出;聚焦电商与城市数字化场景,杭州特色鲜明。根据IDC 2023年报告,四城市AI产业综合竞争力评分在85-92分区间(满分100),构成中国AI创新的「黄金四边形」。 |
在人工智能创新领域,中国多个城市展现出显著活力,但 **北京、深圳、上海、杭州** 的综合表现尤为突出。以下从多维度分析: --- ### 1. **北京:科研与生态高地** - **核心优势**: - **顶尖高校与科研机构**:清华大学、北京大学、中科院等密集分布,支撑基础研究和技术突破。 - **企业集群**:百度(自动驾驶、文心大模型)、字节跳动(AIGC)、商汤、旷视等头部企业总部或重要分部聚集。 - **政策支持**:中关村国家自主创新示范区政策倾斜,国家级AI实验室密集。 - **成果**:AI专利数量全国第一,大模型研发占全国半数以上。 --- ### 2. **深圳:产业化与商业化标杆** - **核心优势**: - **硬件与产业链优势**:华为、腾讯、大疆等企业推动AI与制造业融合(如智能制造、无人机)。 - **市场化活力**:初创企业融资活跃,政府提供产业化补贴和场景开放(如智慧城市)。 - **粤港澳协同**:依托大湾区资源整合,加速跨境技术应用。 - **成果**:AI芯片(如华为昇腾)、机器人等领域产业化领先。 --- ### 3. **上海:国际化与场景落地** - **核心优势**: - **国际化生态**:吸引特斯拉、微软亚洲研究院等外企研发中心,商汤、依图等本土企业崛起。 - **政策导向**:浦东新区“AI岛”建设,聚焦金融、医疗等垂直领域应用。 - **世界人工智能大会(WAIC)**:国际影响力平台推动资源聚合。 - **成果**:AI+金融(如智能投顾)、AI+医疗(影像诊断)场景落地成熟。 --- ### 4. **杭州:电商与数字驱动** - **核心优势**: - **阿里生态**:阿里云、达摩院推动云计算、AI服务(如城市大脑)。 - **政策支持**:浙江省“人工智能+”行动计划,之江实验室聚焦前沿技术。 - **智慧城市试点**:交通、政务等领域AI渗透率高。 - **成果**:电商推荐算法、智慧物流等场景技术领先。 --- ### 综合对比 | **维度** | **北京** | **深圳** | **上海** | **杭州** | |----------------|---------------|---------------|---------------|---------------| | **科研实力** | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | | **产业化能力** | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | | **政策支持** | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | | **应用场景** | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | --- ### 结论 - **北京**:综合实力最强,适合基础研究与技术孵化。 - **深圳**:产业化与商业化最活跃,适合技术落地与硬件结合。 - **上海**:国际化与垂直场景应用领先,适合跨境合作与细分领域深耕。 - **杭州**:数字经济和电商AI应用突出,适合生态协同创新。 若以“活力”侧重 **技术转化速度和市场化能力**,**深圳**可能更具优势;若强调 **科研生态和顶层资源**,则 **北京** 更胜一筹。 |
l 典型案例:普通人在历史进程中的作用有多大?
|
优化前输出 |
优化后输出 |
|
历史进程并非仅由英雄或统治者单方面推动,普通人的集体力量始终是文明演进的基础性动力。以下从四个维度解析普通人的历史作用: ### 一、社会基础构建者 1. 经济基石:中国古代京杭大运河的持续维护依赖数十万河工的日常劳作,宋元时期江南农民发明的"圩田"技术使粮食产量翻倍 2. 文化传承载体:明清时期市井说书人通过《三国演义》等口头文学,塑造了民间忠义价值观的集体记忆 3. 技术迭代推动者:工业革命时期曼彻斯特纺织女工在实践中改良纺纱技术,使生产效率提升300% ### 二、变革触发点 1. 1919年五四运动中,北京黄包车夫拒绝运送日本官员的集体罢工,成为运动扩展至全民的重要转折 2. 1980年温州章华妹领到首张个体执照,标志市场经济细胞开始激活 3. 2011年突尼斯小贩自焚事件揭示:底层生存危机可能成为制度变革的导火索 ### 三、隐性价值创造 1. 南宋临安茶馆形成的市民舆论场,孕育出最早的商业契约精神 2. 明代徽商妇留守家乡管理族田,构建起宗族经济网络支撑商业扩张 3. 当代外卖骑手通过算法反馈倒逼平台优化配送系统,重塑服务业形态 ### 四、历史记忆重构 1. 敦煌文书中的市井借贷契约,颠覆了传统认知中"重农抑商"的刻板印象 2. 抗战时期重庆防空洞里市民创作的竹枝词,提供了战争体验的民间视角 3. 当代农民工的迁徙轨迹,正在书写新型城镇化的人口地理志 历史真相往往藏在账簿、契约、日记这些微观记录中。普通人的日常选择如同地质运动中的分子振动,当亿万次同频共振发生时,就会引发文明版块的位移。每个时代的进步本质上是无数普通人突破生存惯性,在既有结构中创造新可能的累积过程。这种看似被动的能动性,恰是历史最深邃的动力源。 |
关于普通人在历史进程中的作用,我们可以从不同视角进行探讨: ### 一、历史观的演变 1. **英雄史观**(19世纪前主流) - 代表人物:托马斯·卡莱尔《论英雄》 - 认为历史由帝王将相、思想领袖推动 - 例:拿破仑改变欧洲格局,爱因斯坦推动科学革命 2. **群众史观**(马克思主义视角) - 历史唯物主义强调生产力发展决定历史进程 - 统计数据显示:工业革命时期英国棉纺织工人数量增长300倍(1780-1830) - 法国大革命中巴黎市民攻占巴士底狱的集体行动 ### 二、作用机制分析 | 作用维度 | 具体表现 | |-----------------|----------------------------| | 生产力基础 | 中国古代60%以上人口从事农业 | | 文化传承 | 民间技艺传承人保留非遗技术 | | 社会变革 | 五四运动中学生群体推动启蒙 | | 技术应用 | 智能手机用户推动数字革命 | ### 三、当代社会的转变 1. **技术赋权**:社交媒体使个人发声量提升10^6倍(相比前互联网时代) 2. **消费选择**:全球70%企业将ESG纳入决策(消费者伦理选择驱动) 3. **微创新累积**:开源社区贡献者年均创造300万行新代码 ### 四、辩证认知框架 ``` 个体作用 ←[量变积累]→ 集体力量 ↑ ↑ 被动承受历史条件 ←→ 主动创造可能空间 ``` **典型案例**:日本主妇发起的反塑料袋运动,10年间减少40%塑料用量,推动立法进程。 ### 五、作用限度与突破 - 结构约束:个人受制于时代的生产关系(马克思) - 突破路径:通过组织化(工会/NGO)提升效能 - 现代数据:全球NGO数量突破1000万(2023统计) 结论:普通人如同历史长河中的"量子涨落",单个粒子作用有限,但群体性微观运动持续塑造宏观历史轨迹。在数字文明时代,个体能动性通过技术杠杆获得前所未有的放大可能。 |
l 其他问题
1. 皖南事变暴露出共产党哪些问题?
2. 中美科技战中国的优势是什么?
3. 特朗普查五角大楼账目会成功吗?
4. 怎么看代美国退出巴黎协定?
5. 在人工智能创新上中国哪个城市最具活力?
6. 中国大模型行业2025年将会迎来哪些机遇和挑战
07. 数学推理计算类题目
请一步一步推理,并将你的最终答案放在 { } 中
Prompt优化方法:
|
优化前Prompt |
优化后Prompt |
|
2015年,张先生在国家扩大内需政策的鼓舞下,购买了一辆价值10万元的小轿车。深知交通事故风险的张先生找到甲财产险公司为其爱车投保了一份保险金额为5万元的财产险。投保后不久,张先生感觉投保金额太低,于是他又找到乙、丙财产险公司为其爱车投保了财产险,保险金额分别为10万元和15万元,这样张先生就“放心了”。假如张先生的爱车发生事故,并且全损,张先生最多可以获得()万元的赔偿。 A.10 B.20 C.5 D.15 |
请一步一步推理,输出格式为【最终答案:{最终答案} 】\n\n 2015年,张先生在国家扩大内需政策的鼓舞下,购买了一辆价值10万元的小轿车。深知交通事故风险的张先生找到甲财产险公司为其爱车投保了一份保险金额为5万元的财产险。投保后不久,张先生感觉投保金额太低,于是他又找到乙、丙财产险公司为其爱车投保了财产险,保险金额分别为10万元和15万元,这样张先生就“放心了”。假如张先生的爱车发生事故,并且全损,张先生最多可以获得()万元的赔偿。 A.10 B.20 C.5 D.15 |
|
优化前输出 |
优化后输出 |
|
根据保险法关于重复保险的规定,当同一保险标的被多次投保且总保额超过实际价值时,各保险人的赔偿总和不得超过保险标的的实际价值。张先生车辆的实际价值为10万元,尽管他分别在甲、乙、丙三家公司投保了5万、10万和15万元(总保额30万元),但全损时赔偿总额不能超过车辆的实际价值。 **关键分析步骤**: 1. **重复保险的法律限制**:保险法规定,重复保险的总赔偿金额不得超过保险标的的实际价值(本题中车辆价值为10万元)。 2. **赔偿方式**:各保险公司按各自保额占总保额的比例分摊损失。但无论分摊方式如何,张先生最终获得的赔偿总和最高为10万元。 3. **选项排除**:选项B(20万)、C(5万)、D(15万)均不符合重复保险的赔偿上限规则。 **结论**:张先生最多可获得**10万元**赔偿。 |
先生为价值10万元的小轿车先后向甲、乙、丙三家保险公司投保,保额分别为5万元、10万元和15万元。根据财产保险的补偿原则,赔偿总额不得超过保险标的的实际价值(即10万元)。此外,重复保险的赔偿需按各保险公司承保金额的比例分摊。 1. **总保额计算**:5万元(甲) + 10万元(乙) + 15万元(丙) = 30万元 2. **分摊比例**: - 甲公司:5/30 × 10万元 ≈ 1.666万元 - 乙公司:10/30 × 10万元 ≈ 3.333万元 - 丙公司:15/30 × 10万元 = 5万元 3. **总赔偿金额**:1.666 + 3.333 + 5 = 10万元 因此,无论保额总和如何,张先生最多只能获得车辆实际价值10万元的赔偿。 【最终答案:A】 |
08. R1 测试命令
Curl 同步命令
curl https://127.0.0.1:8080/v1/chat/completions \-H "Content-Type: application/json" \ -d '{ "model": "xx", "messages": [ { "role": "user", "content": "2025年大模型的发展趋势分析" } ] "temperature": 0.6 }'
流式python代码
# -*- coding: utf-8 -*-import json import httpx import requests import urllib3 from openai import OpenAI urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) def http_api(): """ 采用 HTTP API方式发送流式请求 """ prompt = "在人工智能创新上中国哪个城市最具活力?" url = "http://7.216.55.11:9000/v1/chat/completions%22 body = { "model": "DeepSeek-R1", "messages": [ { "role": "user", "content": prompt } ], "stream": True } headers = { "Content-Type": "application/json", "X-Apig-AppCode": "xx" # 认证信息,每个局点的key可能不一样 } with requests.post(url = url, headers = headers, data=json.dumps(body), stream=True) as response: if response.status_code != 200: raise Exception("Request failed with status code", response.status_code) # 处理流式响应 for chunk in response.iter_lines(chunk_size=None): chunk = chunk.strip() if not chunk: continue stem = "data: " chunk = chunk[len(stem):] if chunk == b"[DONE]": continue data = json.loads(chunk) delta = data["choices"][0]["delta"] if 'content' in delta.keys(): print(delta["content"], end='', flush=True) elif 'reasoning_content' in delta.keys(): print(delta["reasoning_content"], end='', flush=True) def openai_client(): """ openapi 客户端 """ reasoning_content = "" # 思考过程内容 content = "" # 最终回复内容 content_first_flag = False # 判断是否结束思考过程并开始回复 client = OpenAI( api_key="xx", # 认证信息 base_url="xx", http_client=httpx.Client(verify=False) # 禁用 SSL 证书验证 ) # 创建聊天完成请求 stream = client.chat.completions.create( model="ep-20250213112505-ggwhz", messages=[ {"role": "user", "content": "在人工智能创新上中国哪个城市最具活力?"}, # {"role": "system", "content": system_prmpt}, ], stream=True, temperature=0.6 ) print("\n" + "=" * 30 + "思考过程" + "=" * 30 + "\n") for chunk in stream: delta = chunk.choices[0].delta if not getattr(delta, 'reasoning_content', None) and not getattr(delta, 'content', None): continue if not content_first_flag and getattr(delta, 'content', None): content_first_flag = True print("\n" + "=" * 30 + "正式回复" + "=" * 30 + "\n") if getattr(delta, 'reasoning_content', None): reasoning_content += delta.reasoning_content print(delta.reasoning_content, end="", flush=True) elif getattr(delta, 'content', None): content += delta.content print(delta.content, end="", flush=True) return reasoning_content, content # http_api() openai_client()
09. R1三方体验平台
字节火山引擎:https://console.volcengine.com/ark/region:ark+cn-beijing/experience/chat
硅基流动: https://cloud.siliconflow.cn/playground/chat/17885302724
英伟达:https://build.nvidia.com/deepseek-ai/deepseek-r1
阿里云:https://help.aliyun.com/zh/model-studio/developer-reference/deepseek
百度智能云: https://console.bce.baidu.com/qianfan/ais/console/onlineTest/LLM/DeepSeek-R1
秘塔AI搜索: https://metaso.cn/
无问芯穹: https://cloud.infini-ai.com/genstudio/experience
PPIO派欧云:https://ppinfra.com/llm
纳米AI搜索: https://bot.n.cn/chat?src=AIsearch
商汤大装置: https://console.sensecore.cn/aistudio/experience/conversation
天工AI: https://www.tiangong.cn/
POE:https://poe.com/
腾讯云 TI 平台: https://console.cloud.tencent.com/tione/v2/aimarket/detail/deepseek_series?regionId=1&detailTab=deep_seek_v1
讯飞开放平台:https://training.xfyun.cn/experience/text2text?type=public&modelServiceId=2501631186799621
国家超算中心:https://chat.scnet.cn/
本页内容