DeepSeek应用最佳实践之蒸馏模型
发表于 2025/02/24
DeepSeek-R1蒸馏模型
DeepSeek-R1蒸馏模型是通过蒸馏技术,从大型DeepSeek-R1模型中提取知识,创建的更小、更高效的版本。蒸馏过程将大型模型(教师模型)的推理能力转移到较小的模型(学生模型),使其在推理任务中实现有竞争力的性能,同时提高计算效率,便于部署。
DeepSeek 团队基于 Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5-14B, Qwen2.5-32B, Llama-3.1-8B, and Llama-3.3-70B-Instruct 作为基础模型,通过使用DeepSeek-R1生成的80万个推理数据样本,对这些基础模型进行微调,从而生成出新的蒸馏模型。蒸馏过程包括对推理数据的监督微调(SFT),但不包括额外的强化学习(RL)阶段,这使得该过程对于较小的模型来说更高效、更容易实现。并且,这些蒸馏模型的运行方式与基础模型的运行方式/结构相同,无额外的推理适配需求。
经过蒸馏的模型在推理基准测试中取得了令人印象深刻的结果,部分结果优于GPT-4o和Claude-3.5-Sonnet等较大的模型, 比如 DeepSeek-R1-Distill-Qwen-32B在AIME 2024上达到72.6%的Pass@1, 在MATH-500上达到94.3%的Pass@1,表现明显优于其他开源模型。
模型权重下载
| 模型 | 基础模型下载 | 蒸馏模型下载 |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | https://huggingface.co/Qwen/Qwen2.5-Math-1.5B | https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B |
| DeepSeek-R1-Distill-Qwen-7B | https://huggingface.co/Qwen/Qwen2.5-Math-7B | https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B |
| DeepSeek-R1-Distill-Llama-8B | https://huggingface.co/meta-llama/Llama-3.1-8B | https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B |
| DeepSeek-R1-Distill-Qwen-14B | https://huggingface.co/Qwen/Qwen2.5-14B | https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B |
| DeepSeek-R1-Distill-Qwen-32B | https://huggingface.co/Qwen/Qwen2.5-32B | https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B |
| DeepSeek-R1-Distill-Llama-70B | https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct | https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B |
MindIE 部署方式
01 环境配置(2.0.T3)
首先,我们需要去昇腾社区上申请并获取最新的MindIE镜像安装包:
| 镜像介绍 | https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f |
| 镜像申请/下载 | https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f |
1、拉取镜像
1)选择所需镜像,点击“立即下载”(1.0.0及以后版本支持DeepSeekR1蒸馏模型):

2)根据弹出的镜像下载指令安装docker镜像,请确保机器有网络连接:

2、加载镜像
1)获取镜像后,运行 `docker images` 指令可以查看当前下载的 mindie 镜像。

|
镜像名 |
swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie: 2.0.T3-800I-A2-py311-openeuler24.03-lts |
|
镜像ID |
2ed659651f4f |
2)创建容器启动指令
用 `vim docker_start.sh` 创建容器启动脚本,在脚本中添加以下指令:
container_name=$1 # 参数1:容器名称 image_id=$2 # 参数2:镜像ID model_path=$3 # 参数3:权重路径 docker run -it --privileged --name=$container_name --net=host --shm-size=500g\ --device=/dev/davinci_manager \ --device=/dev/devmm_svm \ --device=/dev/hisi_hdc \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver \ -v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \ -v /usr/local/sbin/:/usr/local/sbin/ \ -v /var/log/npu/slog/:/var/log/npu/slog \ -v /var/log/npu/profiling/:/var/log/npu/profiling \ -v /var/log/npu/dump/:/var/log/npu/dump \ -v /var/log/npu/:/usr/slog \ -v /etc/hccn.conf:/etc/hccn.conf \ -v $model_path:/model \ $image_id \ /bin/bash
启动容器:
export container_name=mindie_2.0.T3 export image_id=2ed659651f4f export model_path=/home/weights/DeepSeek-R1-Distill-Qwen-14B bash docker_start.sh $container_name $image_id $model_path
02 纯模型测试
docker exec -it $container_name bash
2、配置容器环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh # 配置 cann 环境变量 source /usr/local/Ascend/mindie/set_env.sh # 配置 mindie 环境变量 source /usr/local/Ascend/nnal/atb/set_env.sh # 配置 atb 算子加速库环境变量 source /usr/local/Ascend/atb-models/set_env.sh # 配置 atb-models 代码仓环境变量
3、纯模型运行示例
进入模型仓代码文件路径:
cd /usr/local/Ascend/atb-models/
模型代码仓库的目录结构如下:
./atb-models/ |- atb_llm/ # 模型仓 |_ examples/ # 模型运行示例 |_ lib/ # 相关运行所需文件 |_ requirements/ # 包含每个模型相关的依赖文件 |_ tests/ # 模型测试 |_ README.md # 代码仓介绍文档 |_ set_env.sh # 环境变量设置 |_ version.info # 版本信息 |_ atb_llm-0.0.1-py3-none-any.whl # 模型仓的whl包形式
由于此次使用的模型为 DeepSeek-R1-Distill-Qwen-14B,基模为Qwen2.5,因此我们纯模型示例可以基于原Qwen的模型运行示例进行验证,运行以下指令。
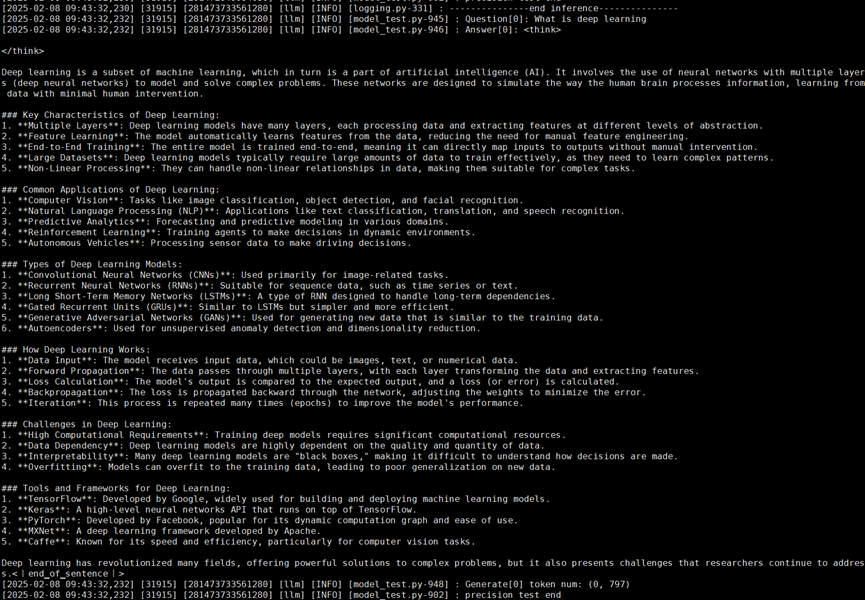
bash atb-models/tests/modeltest/run.sh pa_bf16 precision_single [[256,1024]] \ '["What is deep learning"]' [1] qwen chat /model 2
注:当前使用的是纯模型的modeltest测试功能,参数较多,详情可参考其指导文档 `atb-models/tests/modeltest/README.md`
运行结果:
03 服务化测试
1、更改服务化配置文件将模型权重 config.json 权限设置为 640。
chmod 640 /model/config.json
进入服务化路径,并打开服务化配置文件:
cd /usr/local/Ascend/mindie/latest/mindie-service/ vim conf/config.json
修改以下参数,更多参数请参考MindIE官网(配置参数说明-MindIE Server https://www.hiascend.com/document/detail/zh/mindie/100/mindieservice/servicedev/mindie_service0285.html)
# "ServerConfig": "httpsEnabled" : false # "BackendConfig" "npuDeviceIds" : [[0,1]] "maxSeqLen": 32768 "maxInputTokenLen": 32768 "modelName" : "qwen" "modelWeightPath" : "/model" "worldSize": 2 # "ScheduleConfig" "maxIterTimes" : 32768
启动服务化。
/usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon
2、发送请求
开启另外一个窗口,连接服务器,并进入容器,发送以下指令:
curl -H "Accept: application/json" \ -H "Content-type: application/json" \ -X POST -d '{ "model": "qwen", "messages": [{"role": "user", "content": "请介绍一下什么是蒸馏模型"}], "max_tokens": 32768, "stream": false }' http://127.0.0.1:1025/v1/chat/completions
请求结果:

本页内容