基于Atlas 800I A2的RAG端到端实践
发表于 2025/03/13
作者 | 杨一天 张涛
随着DeepSeek在各行业快速应用落地,如何基于DeepSeek构建上层业务应用已成为推动行业进步的关键,开源社区提供了很多可选的应用套件,本文以Dify为例,介绍了从0开始基于DeepSeek蒸馏模型,构建RAG系统的端到端实践。
注:本实践需要提前开通服务器对外端口,需预留6个端口号:
1、MindIE大模型推理服务1个;
2、embedding和rerank模型3个;
3、dify应用服务开通2个。
用户根据实际服务器情况配置IP及端口。举例:MindIE服务开通:40033;embedding和rerank模型开通:40035、40036、40037;dify服务开通:40038和442。
一、什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索技术与生成模型的技术框架,旨在通过外部知识库优化大语言模型的生成结果,提升回答的准确性和上下文相关性。RAG 通过检索外部知识库中的信息(如文档、段落或结构化数据),将检索到的内容与用户查询结合后,输入生成模型,使模型输出的回答既具备生成灵活性,又减少事实性错误。
RAG的核心流程分为检索与生成两部分。
检索:从外部知识库中提取与用户查询相关的内容,例如通过语义相似度匹配或关键词筛选。通常使用embeding模型初步从知识库中筛选出候选内容,再通过reranker模型对粗排结果进行深度分析,优化检索到的上下文内容。
生成:将检索结果与原始问题合并为增强后的提示词,输入llm模型,生成基于外部知识库的回答。
本次实践将使用TEI部署检索服务,提供embeding与reranker 服务化接口,使用Mind IE部署DeepSeek-R1-Distill-Qwen-14B作为大语言模型,最终将两者接入dify,进行统一调用。
二、TEI服务化部署
TEI(Text Embeddings Inference)是由Hugging Face团队开发的开源高性能文本嵌入推理引擎,专为生产环境中的大规模语义计算设计。其核心目标是解决传统深度学习框架(如PyTorch)在部署文本嵌入模型时面临的性能瓶颈,通过Rust语言底层优化和动态批处理技术,实现比原生实现高5-10倍的吞吐量,同时将延迟降低至毫秒级。TEI支持主流的预训练嵌入模型(如BERT、Sentence-BERT、E5等),只需指定Hugging Face模型ID即可快速部署为标准化API服务,无需复杂代码改造。昇腾目前已支持TEI部署。
2.1 权重下载
本文档以bge-m3模型作为embedding模型,bge-reranker-v2-m3作为rerank模型,可以自行从HuggingFace、ModelScope下载,ModelScope下载方式如下:# 安装 ModelScope
pip install modelscope
# 进入权重路径
cd 权重路径
# 创建对应模型文件夹
mkdir bge-m3
mkdir bge-reranker-v2-m3
# 下载完整模型库
modelscope download --model BAAI/bge-m3 --local_dir ./bge-m3
modelscope download --model BAAI/bge-reranker-v2-m3 --local_dir ./bge-reranker-v2-m32.2 环境准备
2.2.1 拉取镜像
首先,我们需要去昇腾社区上下载最新的TEI镜像安装包:| 镜像介绍 | 该镜像基于text embedding inference 适配昇腾NPU卡提供embedding、reranker等服务化接口,接口兼容开源text embedding inference, 该镜像支持embedding和reranker、Sequence Classification等模型,该镜像以普通用户HwHiAiUser用户运行。 |
| 镜像下载 | https://www.hiascend.com/developer/ascendhub/detail/07a016975cc341f3a5ae131f2b52399d |
1. 选择所需镜像,点击“立即下载”:
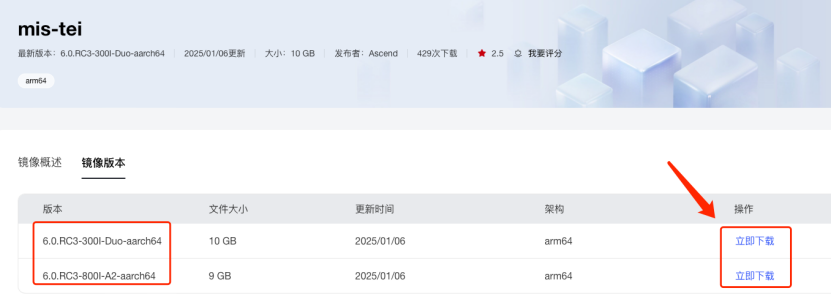
2. 根据弹出的镜像下载指令安装对应的docker镜像, 请确保机器有网络链接:

2.2.2 加载镜像
1. 查看镜像id获取镜像后,运行 `docker images` 指令,可以查看当前下载的TEI镜像。
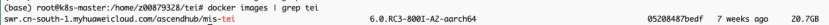
| 镜像名 | swr.cn-south-1.myhuaweicloud.com/ascendhub/mis-tei:6.0.RC3-800I-A2-aarch64 |
| 镜像 ID | 05208487bedf |
2. 创建容器启动指令
用 `vim docker_start.sh` 创建容器启动脚本,在脚本中添加以下变量:
# 变量
model_dir=权重路径
image_id=镜像id
embedding_model_id=embedding模型
reranker_model_id=reranker模型
listen_ip=监听ip
embedding_listen_port=embedding服务端口
reranker_listen_port=reranker服务端口
npu_id=使用的npu卡号添加embedding与reranker的服务启动命令到容器的入口脚本中:
# 写入embedding与reranker启动命令
mkdir ./.temp
echo "#!/bin/bash" > ./.temp/run.sh
echo "" >> ./.temp/run.sh
echo "bash start.sh $embedding_model_id $listen_ip $embedding_listen_port > logs/embedding.log 2>&1 &" >> ./.temp/run.sh
echo "sleep 20" >> ./.temp/run.sh
echo "bash start.sh $reranker_model_id $listen_ip $reranker_listen_port > logs/reranker.log 2>&1 &" >> ./.temp/run.sh
echo "wait" >> ./.temp/run.sh
chmod +x ./.temp/run.sh添加容器启动命令:
# 启动容器
docker run -itd --name=tei --net=host --privileged --user root \
-e ASCEND_VISIBLE_DEVICES=$npu_id \
-e HOME=/home/HwHiAiUser \
-v $model_dir:/home/HwHiAiUser/model \
-v ./.temp/run.sh:/home/HwHiAiUser/run.sh \
-v ./logs:/home/HwHiAiUser/logs \
--entrypoint /home/HwHiAiUser/run.sh \
$image_id
rm -rf ./.temp以下为完整示例:
# 变量
model_dir=/mnt/nvme1n1/bge-weights
image_id=05208487bedf
embedding_model_id=BAAI/bge-m3
reranker_model_id=BAAI/bge-reranker-v2-m3
listen_ip=0.0.0.0
embedding_listen_port=12345
reranker_listen_port=54321
npu_id=0
# 写入embedding与reranker启动命令
mkdir ./.temp
echo "#!/bin/bash" > ./.temp/run.sh
echo "" >> ./.temp/run.sh
echo "bash start.sh $embedding_model_id $listen_ip $embedding_listen_port > logs/embedding.log 2>&1 &" >> ./.temp/run.sh
echo "sleep 20" >> ./.temp/run.sh
echo "bash start.sh $reranker_model_id $listen_ip $reranker_listen_port > logs/reranker.log 2>&1 &" >> ./.temp/run.sh
echo "wait" >> ./.temp/run.sh
chmod +x ./.temp/run.sh
# 启动容器
docker run -itd --name=tei --net=host --privileged --user root \
-e ASCEND_VISIBLE_DEVICES=$npu_id \
-e HOME=/home/HwHiAiUser \
-v $model_dir:/home/HwHiAiUser/model \
-v ./.temp/run.sh:/home/HwHiAiUser/run.sh \
-v ./logs:/home/HwHiAiUser/logs \
--entrypoint /home/HwHiAiUser/run.sh \
$image_id
rm -rf ./.temp3. 启动容器并测试
# 启动容器
bash docker_start.sh
# 查看服务状态
tail -f logs/embedding.log
tail -f logs/reranker.log若服务启动完成,会返回如下结果
成功启动后可通过如下命令进行测试:
embedding:
curl 127.0.0.1:12345/embed \
-X POST \
-d '{"inputs":"What is Deep Learning?"}' \
-H 'Content-Type: application/json'结果: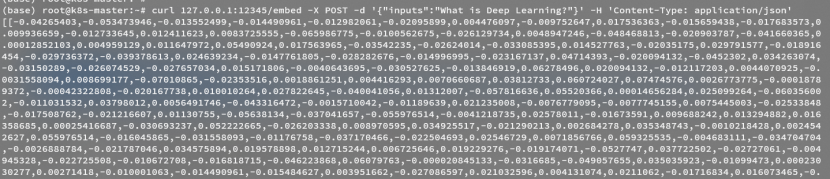
reranker:
curl 127.0.0.1:54321/rerank \
-X POST \
-d '{"query":"What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]}' \
-H 'Content-Type: application/json'结果:
三、MindIE服务化部署
MindIE(Mind Inference Engine,昇腾推理引擎)是华为昇腾针对AI全场景业务的推理加速套件。通过分层开放AI能力,支撑用户多样化的AI业务需求,使能百模千态,释放昇腾硬件设备算力。向上支持多种主流AI框架,向下对接不同类型昇腾AI处理器,提供多层次编程接口,帮助用户快速构建基于昇腾平台的推理业务。3.1权重下载
本文档以DeepSeek-R1-Distill-Qwen-14B模型为例,可以自行从HuggingFace、ModelScope下载,ModelScope下载方式如下:# 安装 ModelScope,若已安装则跳过
pip install modelscope
# 进入权重路径
cd 权重路径
# 创建对应模型文件夹
mkdir DeepSeek-R1-Distill-Qwen-14B
# 下载完整模型库
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-14B --local_dir ./DeepSeek-R1-Distill-Qwen-14B3.2环境准备
3.2.1拉取镜像
首先,我们需要去昇腾社区上申请并获取最新的MindIE镜像安装包:| 镜像介绍 | 该镜像已具备模型运行所需的基础环境,包括:CANN、FrameworkPTAdapter、MindIE与ATB-Models,可实现模型快速上手推理。 注意:为方便使用,该镜像中内置了ATB-Models压缩包,并放置于/opt/package之下,如需使用,可从镜像中获取。 |
| 镜像下载 | https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f |
1. 选择所需镜像,点击“立即下载”(1.0.0及以后版本支持DeepSeekR1蒸馏模型):
2. 根据弹出的镜像下载指令安装docker镜像,请确保机器有网络连接:
3.2.2加载镜像
1. 查看镜像id获取镜像后,运行 `docker images` 指令,可以查看当前下载的TEI镜像。

| 镜像名 | swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie: 2.0.T3-800I-A2-py311-openeuler24.03-lts |
| 镜像 ID | 2ed659651f4f |
2. 创建容器启动指令
用 `vim docker_start.sh` 创建容器启动脚本,在脚本中添加以下指令:
container_name=$1 # 参数1:容器名称
image_id=$2 # 参数2:镜像ID
model_path=$3 # 参数3:权重路径
docker run -it --privileged --name=$container_name --net=host --shm-size=500g\
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /var/log/npu/slog/:/var/log/npu/slog \
-v /var/log/npu/profiling/:/var/log/npu/profiling \
-v /var/log/npu/dump/:/var/log/npu/dump \
-v /var/log/npu/:/usr/slog \
-v /etc/hccn.conf:/etc/hccn.conf \
-v $model_path:/model \
$image_id \
/bin/bash3. 启动容器
export container_name=mindie_2.0.T3
export image_id=2ed659651f4f
export model_path=/home/weights/DeepSeek-R1-Distill-Qwen-14B
bash docker_start.sh $container_name $image_id $model_path3.2.3启动mindie服务化
1. 更改模型config.json文件权限chmod 640 /model/config.json2. 更改服务化配置文件
进入服务化路径,并打开服务化配置文件
cd /usr/local/Ascend/mindie/latest/mindie-service/
vim conf/config.json修改以下参数,更多参数请参考MindIE官网(配置参数说明-MindIE Server https://www.hiascend.com/document/detail/zh/mindie/100/mindieservice/servicedev/mindie_service0285.html )
# "ServerConfig":
"ipAddress" : $服务器ip
"httpsEnabled" : false
# "BackendConfig"
"npuDeviceIds" : [[0,1]]
"maxSeqLen" : 32768
"maxInputTokenLen": 16384
"modelName" : "deepseek-qwen"
"modelWeightPath" : "/model"
"worldSize": 2
# "ScheduleConfig"
"maxPrefillTokens" : 16384
"maxIterTimes" : 163843. 启动服务化
cd /usr/local/Ascend/mindie/latest/mindie-service/
./bin/mindieservice_daemon
显示 “Daemon start success! ”代表成功拉起服务化

注:若希望后台运行,可使用命令“nohup ./bin/mindieservice_daemon 2>&1 &”后台启动,之后使用“tail -f nohup.out”命令查看mindie service的状态。
4. 发送请求进行测试
开启另外一个窗口,连接服务器,并进入容器,发送以下指令(若使用后台启动,则可以直接在当前窗口发送请求指令):
curl -H "Accept: application/json" \
-H "Content-type: application/json" \
-X POST -d '{
"model": "qwen",
"messages": [{"role": "user", "content": "请介绍一下什么是蒸馏模型"}],
"max_tokens": 32768,
"stream": false
}' http://127.0.0.1:1025/v1/chat/completions请求结果:

四、Dify
4.1工具介绍
Dify 是一款开源的大语言模型(LLM)应用开发平台,通过 低代码/无代码 的模块化设计降低生成式 AI 应用的开发门槛,支持集成 OpenAI、Claude3 等主流模型及自托管模型(如 Ollama)。其核心功能包括 后端即服务(BaaS)、可视化 Prompt 编排 和 LLMOps 工具链,可灵活构建智能客服、文本生成等场景。平台内置 RAG 引擎 实现知识库检索增强生成,并通过 Agent 框架 支持复杂任务分解与工具调用(如搜索、绘图),结合 Workflow 工作流 实现多步骤业务逻辑自动化。4.2dify安装
具体可参考官方手册:https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/docker-compose4.2.1前置条件
| 硬件与软件 | cpu | ram | docker | compose |
| 要求(版本) | >= 2 Core | >= 4 GiB | 19.03 or later | 1.28 or later |
4.2.2安装
1. 拉取github仓库以0.15.3版本为例:
git clone https://github.com/langgenius/dify.git --branch 0.15.32. 启动dify
进入docker目录
cd dify/docker复制环境配置文件
cp .env.example .envvim打开.env文件更改端口号
vim .env将NGINX_PORT与NGINX_PORT_EXPOSE更改为未使用的端口。
默认使用80端口,若无冲突则无需更改。


启动容器
docker compose up -d首次启动时,docker会自动从云端仓库拉取镜像。但由于网络因素,国内通常无法正常从默认docker源进行拉取。请自行更改/etc/docker/daemon.json配置文件,添加国内镜像源(请自行搜索)。
vim /etc/docker/daemon.json/etc/docker/daemon.json
{
"default-runtime": "ascend",
"registry-mirrors":[
...
],
"runtimes": {
"ascend": {
"path": "/usr/local/Ascend/Ascend-Docker-Runtime/ascend-docker-runtime",
"runtimeArgs": []
}
}
}运行结束后,会得到以下输出,代表容器已全部拉起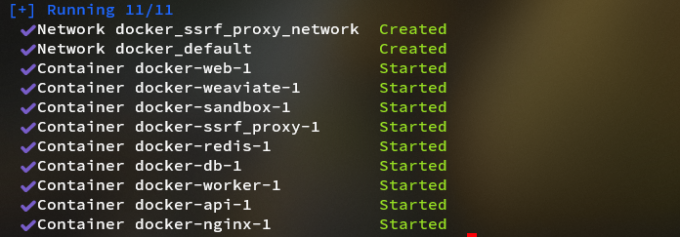
检查容器是否正常运行
docker compose ps可看到所有容器的运行状态与占用端口。应该看到包含3个业务服务(api / worker / web)以及6个基础组件(weaviate / db / redis / nginx / ssrf_proxy / sandbox)在内的总共9个容器,且STATUS均为Up。
4.3 dify使用
4.3.1配置dify
1. 登录dify网页在浏览器内输入“服务器ip:端口号”该端口号为在启动dify时更改的nginx port,若无更改,则使用默认的80端口登录。
2. 设置账号
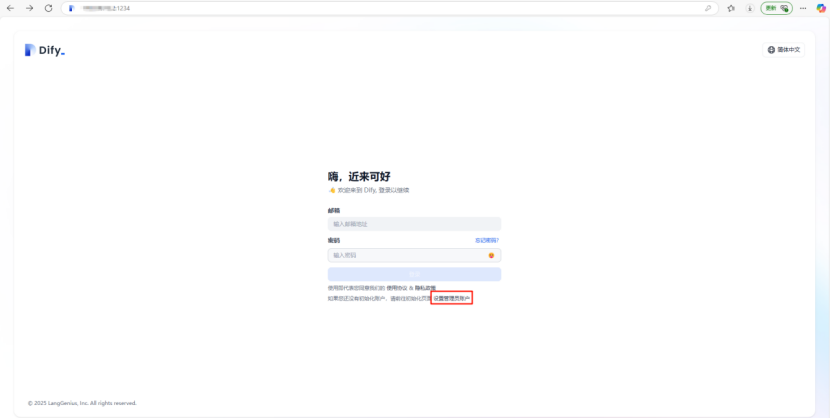
首次登陆请设置管理员账号。邮箱无需设置真实邮箱,可随意进行设置,只需符合邮箱规范。例如:test@huawei.com。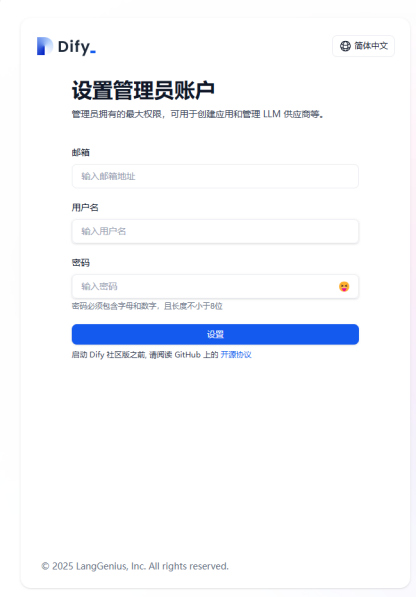
之后使用设置的账号登录
3. 配置模型
llm模型:
点击右上角用户头像,进入设置。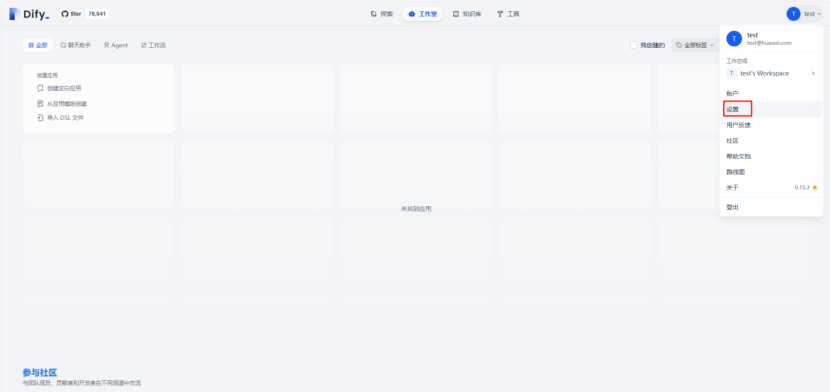
选择模型供应商中的OpenAI-API-compatible模块。点击添加模型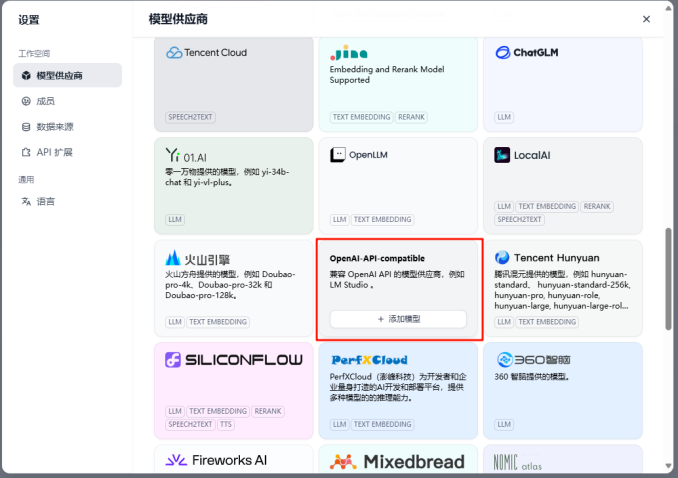
模型类型选择“LLM”,“模型名称”与Mind IE服务化配置文件“config.json”中的“modelName”保持一致,“API endpoint URL”填写“http://$服务器ip:$mindie端口/v1”,其中Mind IE端口在Mind IE服务化配置文件“config.json”中设置,默认为1025。“模型上下文长度”与“最大 token 上限”按需填写。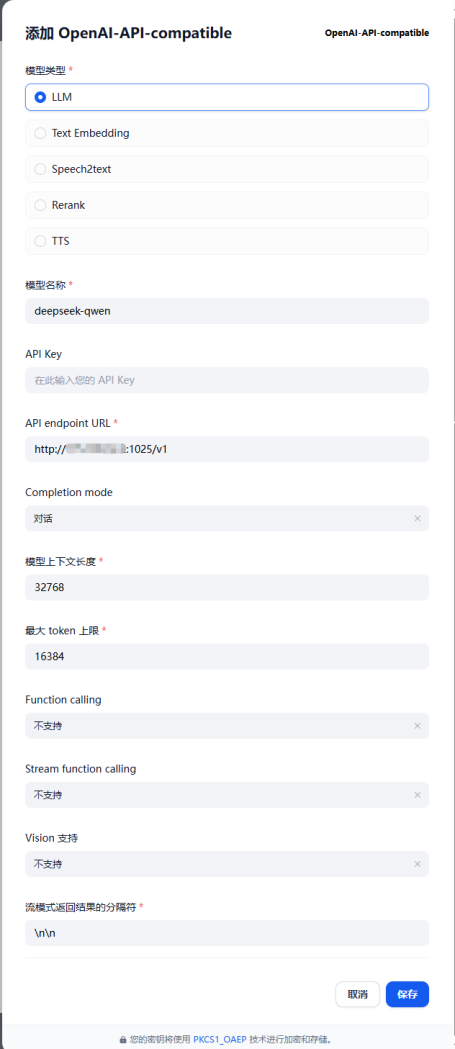
Embedding模型:
选择模型供应商中的Text Embedding Inference模块。点击添加模型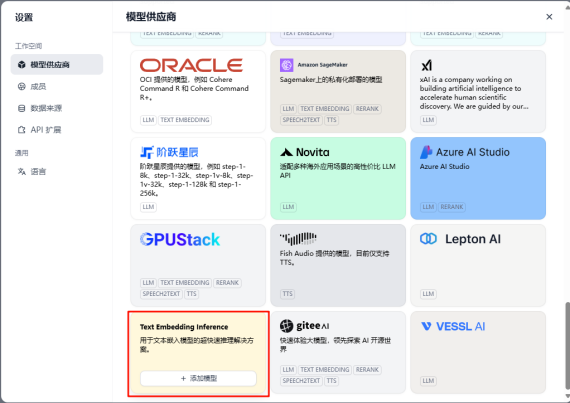
“模型类型”选择“Text Embedding”,“模型名称”为“bge-m3”,“服务器URL”为“http://$服务器ip:$embedding端口”,其中embedding端口在2.2.2节中设置,为“12345”。“API Key”可随意填写。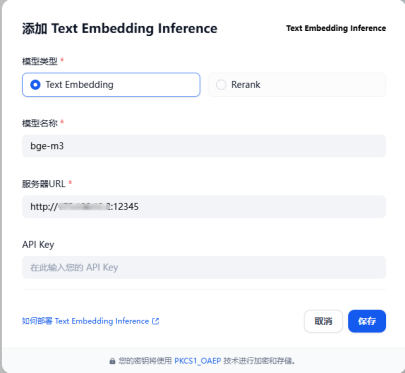
Reranker模型:
继续在Text Embedding Inference中添加模型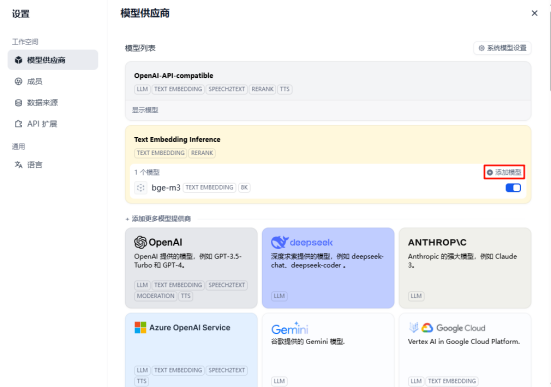
“模型类型”选择“Rerank”,“模型名称”为“bge-reranker-v2-m3”,“服务器URL”为“http://$服务器ip:$rerank端口”,其中rerank端口在2.2.2节中设置,为“54321”。“API Key”可随意填写。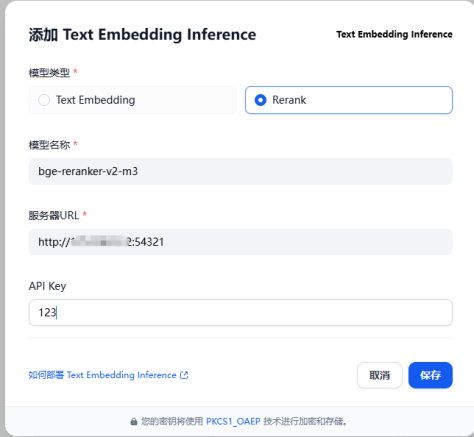
4. 知识库配置
创建知识库
设置分段
embedding模型选择bge-m3,rerank模型选择bge-reranker-v2-m3。其余分段类型,分段长度,检索方式等可自行尝试,寻找最优方案。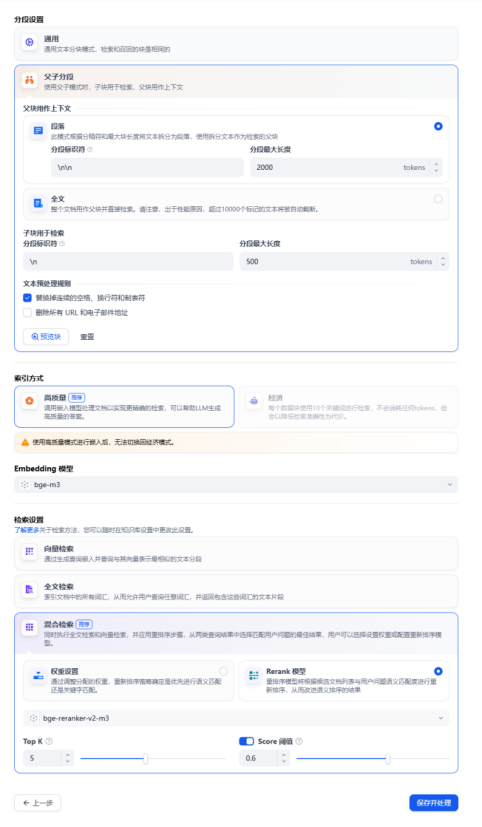
等待嵌入处理完成,根据文档大小,分段方式与长度耗时不等。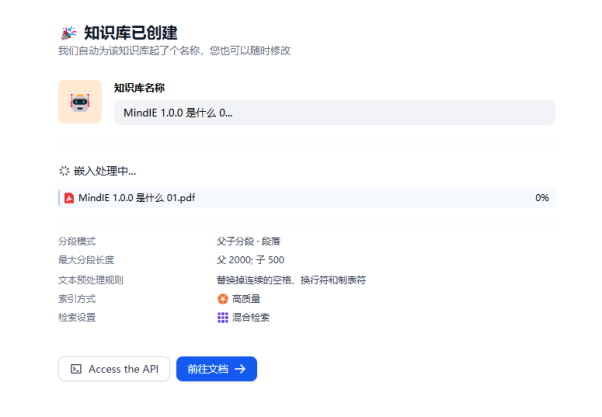
创建应用
回到工作室,创建空白应用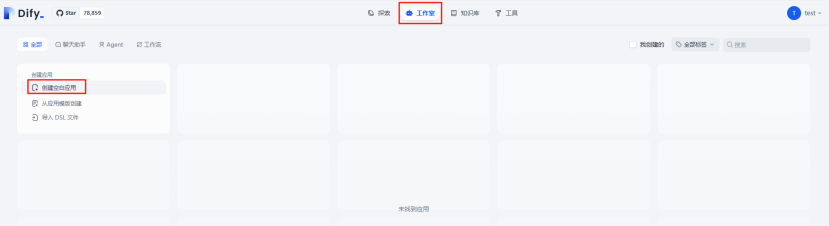
创建聊天助手,进行测试。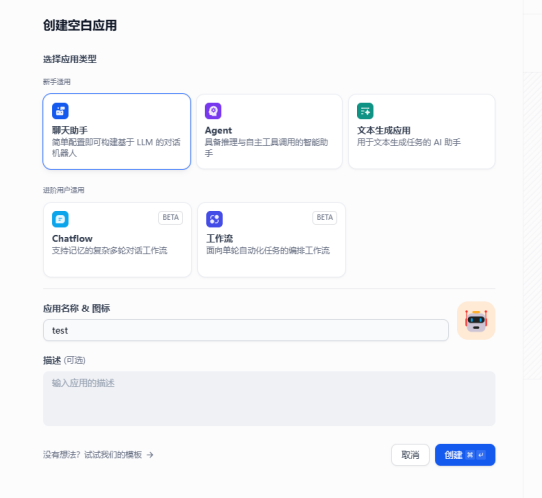
点击添加上下文,选择知识库进行添加。
问答测试