

序号 |
算子名称 |
|---|---|
1 |
torch_npu._npu_dropout |
2 |
torch_npu.copy_memory_ |
3 |
torch_npu.empty_with_format |
4 |
torch_npu.fast_gelu |
5 |
torch_npu.npu_alloc_float_status |
6 |
torch_npu.npu_anchor_response_flags |
7 |
torch_npu.npu_apply_adam |
8 |
torch_npu.npu_batch_nms |
9 |
torch_npu.npu_bert_apply_adam |
10 |
torch_npu.npu_bmmV2 |
11 |
torch_npu.npu_bounding_box_decode |
12 |
torch_npu.npu_bounding_box_encode |
13 |
torch_npu.npu_broadcast |
14 |
torch_npu.npu_ciou |
15 |
torch_npu.npu_clear_float_status |
16 |
torch_npu.npu_confusion_transpose |
17 |
torch_npu.npu_conv_transpose2d |
18 |
torch_npu.npu_conv2d |
19 |
torch_npu.npu_conv3d |
20 |
torch_npu.npu_convolution |
21 |
torch_npu.npu_convolution_transpose |
22 |
torch_npu.npu_deformable_conv2d |
23 |
torch_npu.npu_diou |
24 |
torch_npu.npu_dtype_cast |
25 |
torch_npu.npu_format_cast |
26 |
torch_npu.npu_format_cast_ |
27 |
torch_npu.npu_get_float_status |
28 |
torch_npu.npu_giou |
29 |
torch_npu.npu_grid_assign_positive |
30 |
torch_npu.npu_gru |
31 |
torch_npu.npu_ifmr |
32 |
torch_npu.npu_indexing |
33 |
torch_npu.npu_iou |
34 |
torch_npu.npu_layer_norm_eval |
35 |
torch_npu.npu_linear |
36 |
torch_npu.npu_lstm |
37 |
torch_npu.npu_masked_fill_range |
38 |
torch_npu.npu_max |
39 |
torch_npu.npu_min |
40 |
torch_npu.npu_nms_rotated |
41 |
torch_npu.npu_nms_v4 |
42 |
torch_npu.npu_nms_with_mask |
43 |
torch_npu.npu_normalize_batch |
44 |
torch_npu.npu_one_hot |
45 |
torch_npu.npu_pad |
46 |
torch_npu.npu_ps_roi_pooling |
47 |
torch_npu.npu_ptiou |
48 |
torch_npu.npu_random_choice_with_mask |
49 |
torch_npu.npu_reshape |
50 |
torch_npu.npu_roi_align |
51 |
torch_npu.npu_rotated_box_decode |
52 |
torch_npu.npu_rotated_box_encode |
53 |
torch_npu.npu_rotated_iou |
54 |
torch_npu.npu_rotated_overlaps |
55 |
torch_npu.npu_scatter |
56 |
torch_npu.npu_sign_bits_pack |
57 |
torch_npu.npu_sign_bits_unpack |
58 |
torch_npu.npu_silu |
59 |
torch_npu.npu_slice |
60 |
torch_npu.npu_softmax_cross_entropy_with_logits |
61 |
torch_npu.npu_sort_v2 |
62 |
torch_npu.npu_stride_add |
63 |
torch_npu.npu_transpose |
64 |
torch_npu.npu_yolo_boxes_encode |
65 |
torch_npu.npu_rotary_mul |
66 |
torch_npu.npu_fused_attention_score |
67 |
torch_npu.npu_scaled_masked_softmax |
68 |
torch_npu.npu_dropout_with_add_softmax |
69 |
torch.npu_multi_head_attention |
70 |
torch_npu. npu_geglu |
71 |
torch_npu.npu_rms_norm |
映射关系
NPU自定义算子参数中存在部分映射关系可参考下表。
参数 |
映射参数 |
说明 |
|---|---|---|
ACL_FORMAT_UNDEFINED |
-1 |
Format参数映射值。 |
ACL_FORMAT_NCHW |
0 |
|
ACL_FORMAT_NHWC |
1 |
|
ACL_FORMAT_ND |
2 |
|
ACL_FORMAT_NC1HWC0 |
3 |
|
ACL_FORMAT_FRACTAL_Z |
4 |
|
ACL_FORMAT_NC1HWC0_C04 |
12 |
|
ACL_FORMAT_HWCN |
16 |
|
ACL_FORMAT_NDHWC |
27 |
|
ACL_FORMAT_FRACTAL_NZ |
29 |
|
ACL_FORMAT_NCDHW |
30 |
|
ACL_FORMAT_NDC1HWC0 |
32 |
|
ACL_FRACTAL_Z_3D |
33 |
详细算子接口说明
torch_npu.npu_apply_adam(beta1_power, beta2_power, lr, beta1, beta2, epsilon, grad, use_locking, use_nesterov, out = (var, m, v))
adam结果计数。
- 参数解释:
- beta1_power (Scalar) - beta1的幂。
- beta2_power (Scalar) - beta2的幂。
- lr (Scalar) - 学习率。
- beta1 (Scalar) - 一阶矩估计值的指数衰减率。
- beta2 (Scalar) - 二阶矩估计值的指数衰减率。
- epsilon (Scalar) - 添加到分母中以提高数值稳定性的项数。
- grad (Tensor) - 梯度。
- use_locking (Bool,可选) - 设置为True时使用lock进行更新操作。
- use_nesterov (Bool,可选) - 设置为True时采用nesterov更新。
- var (Tensor) - 待优化变量。
- m (Tensor) - 变量平均值。
- v (Tensor) - 变量方差。
- 约束条件:
- 示例:
torch_npu.npu_convolution_transpose(input, weight, bias, padding, output_padding, stride, dilation, groups) -> Tensor
在由多个输入平面组成的输入图像上应用一个2D或3D转置卷积算子,有时这个过程也被称为“反卷积”。
- 参数解释:
- input (Tensor) - shape的输入张量,值为 (minibatch, in_channels, iH, iW) 或 (minibatch, in_channels, iT, iH, iW)。
- weight (Tensor) - shape过滤器,值为 (in_channels, out_channels/groups, kH, kW) 或 (in_channels, out_channels/groups, kT, kH, kW)。
- bias (Tensor, 可选) - shape偏差 (out_channels)。
- padding (ListInt) - (dilation * (kernel_size - 1) - padding) 用零来填充输入每个维度的两侧。
- output_padding (ListInt) - 添加到输出shape每个维度一侧的附加尺寸。
- stride (ListInt) - 卷积核步长。
- dilation (ListInt) - 内核元素间距。
- groups (Int) - 对输入进行分组。In_channels可被组数整除。
- 约束条件:
- 示例:
torch_npu.npu_conv_transpose2d(input, weight, bias, padding, output_padding, stride, dilation, groups) -> Tensor
在由多个输入平面组成的输入图像上应用一个2D转置卷积算子,有时这个过程也被称为“反卷积”。
- 参数解释:
- input (Tensor) - shape的输入张量,值为 (minibatch, in_channels, iH, iW)。
- weight (Tensor) - shape过滤器,值为 (in_channels, out_channels/groups, kH, kW)。
- bias (Tensor, 可选) - shape偏差 (out_channels)。
- padding (ListInt) - (dilation * (kernel_size - 1) - padding) 用零来填充输入每个维度的两侧。
- output_padding (ListInt) - 添加到输出shape每个维度一侧的附加尺寸。
- stride (ListInt) - 卷积核步长。
- dilation (ListInt) - 内核元素间距。
- groups (Int) - 对输入进行分组。In_channels可被组数整除。
- 约束条件:
- 示例:
torch_npu.npu_convolution(input, weight, bias, stride, padding, dilation, groups) -> Tensor
在由多个输入平面组成的输入图像上应用一个2D或3D卷积。
- 参数解释:
- input (Tensor) - shape的输入张量,值为 (minibatch, in_channels, iH, iW) 或 (minibatch, in_channels, iT, iH, iW)。
- weight (Tensor) - shape过滤器,值为 (out_channels, in_channels/groups, kH, kW) 或 (out_channels, in_channels/groups, kT, kH, kW)。
- bias (Tensor, 可选) - shape偏差 (out_channels)。
- stride (ListInt) - 卷积核步长。
- padding (ListInt) - 输入两侧的隐式填充。
- dilation (ListInt) - 内核元素间距。
- groups (Int) - 对输入进行分组。In_channels可被组数整除。
- 约束条件:
- 示例:
torch_npu.npu_conv2d(input, weight, bias, stride, padding, dilation, groups) -> Tensor
在由多个输入平面组成的输入图像上应用一个2D卷积。
- 参数解释:
- input (Tensor) - shape的输入张量,值为 (minibatch, in_channels, iH, iW)。
- weight (Tensor) - shape过滤器,值为 (out_channels, in_channels/groups, kH, kW)。
- bias (Tensor, 可选) - shape偏差 (out_channels)。
- stride (ListInt) - 卷积核步长。
- padding (ListInt) - 输入两侧的隐式填充。
- dilation (ListInt) - 内核元素间距。
- groups (Int) - 对输入进行分组。In_channels可被组数整除。
- 约束条件:
- 示例:
torch_npu.npu_conv3d(input, weight, bias, stride, padding, dilation, groups) -> Tensor
在由多个输入平面组成的输入图像上应用一个3D卷积。
- 参数解释:
- input (Tensor) - shape的输入张量,值为 (minibatch, in_channels, iT, iH, iW)。
- weight (Tensor) - shape过滤器,值为 (out_channels, in_channels/groups, kT, kH, kW)。
- bias (Tensor, 可选) - shape偏差 (out_channels)。
- stride (ListInt) - 卷积核步长。
- padding (ListInt) - 输入两侧的隐式填充。
- dilation (ListInt) - 内核元素间距。
- groups (Int) - 对输入进行分组。In_channels可被组数整除。
- 约束条件:
- 示例:
torch_npu.one_(self) -> Tensor
用1填充self张量。
- 参数解释:
- self (Tensor) - 输入张量。
- 约束条件:
- 示例:
>>> x = torch.rand(2, 3).npu() >>> xtensor([[0.6072, 0.9726, 0.3475], [0.3717, 0.6135, 0.6788]], device='npu:0') >>> x.one_()tensor([[1., 1., 1.], [1., 1., 1.]], device='npu:0')
torch_npu.npu_sort_v2(self, dim=-1, descending=False, out=None) -> Tensor
沿给定维度,按无index值对输入张量元素进行升序排序。若dim未设置,则选择输入的最后一个维度。如果descending为True,则元素将按值降序排序。
- 参数解释:
- self (Tensor) - 输入张量。
- dim (Int, 可选,默认值为-1) - 进行排序的维度。
- descending (Bool, 可选,默认值为None) - 排序顺序控制(升序或降序)。
- 约束条件:
- 示例:
>>> x = torch.randn(3, 4).npu() >>> x tensor([[-0.0067, 1.7790, 0.5031, -1.7217], [ 1.1685, -1.0486, -0.2938, 1.3241], [ 0.1880, -2.7447, 1.3976, 0.7380]], device='npu:0') >>> sorted_x = torch_npu.npu_sort_v2(x) >>> sorted_x tensor([[-1.7217, -0.0067, 0.5029, 1.7793], [-1.0488, -0.2937, 1.1689, 1.3242], [-2.7441, 0.1880, 0.7378, 1.3975]], device='npu:0')
torch_npu.npu_format_cast(self, acl_format) -> Tensor
修改NPU张量的格式。
- 参数解释:
- self (Tensor) - 输入张量。
- acl_format (Int) - 目标格式。
- 约束条件:
- 示例:
>>> x = torch.rand(2, 3, 4, 5).npu() >>> torch_npu.get_npu_format(x) 0 >>> x1 = x.npu_format_cast(29) >>> torch_npu.get_npu_format(x1) 29
torch_npu.npu_format_cast_(self, src) -> Tensor
原地修改self张量格式,与src格式保持一致。
- 参数解释:
- self (Tensor) - 输入张量。
- src (Tensor,int) - 目标格式。
- 约束条件:
- 示例:
>>> x = torch.rand(2, 3, 4, 5).npu() >>> torch_npu.get_npu_format(x) 0 >>> torch_npu.get_npu_format(x.npu_format_cast_(29)) 29
torch_npu.npu_transpose(self, perm, require_contiguous=True) -> Tensor
返回原始张量视图,其维度已permute,结果连续。
- 参数解释:
- self (Tensor) - 输入张量。
- perm (ListInt) - 对应维度排列。
- require_contiguous(Bool,默认值为True) - 用户是否显式指定npu_contiguous算子适配需要对输入Tensor做转连续。默认为False,低性能模式。用户明确知道输入Tensor为连续Tensor或转置Tensor时,才能设置为True使用高性能模式。
- 约束条件:
- 示例:
>>> x = torch.randn(2, 3, 5).npu() >>> x.shape torch.Size([2, 3, 5]) >>> x1 = torch_npu.npu_transpose(x, (2, 0, 1)) >>> x1.shape torch.Size([5, 2, 3]) >>> x2 = x.npu_transpose(2, 0, 1) >>> x2.shape torch.Size([5, 2, 3])
torch_npu.npu_broadcast(self, size) -> Tensor
返回self张量的新视图,其单维度扩展,结果连续。
张量也可以扩展更多维度,新的维度添加在最前面。
- 参数解释:
- self (Tensor) - 输入张量。
- size (ListInt) - 对应扩展尺寸。
- 约束条件:
- 示例:
>>> x = torch.tensor([[1], [2], [3]]).npu() >>> x.shape torch.Size([3, 1]) >>> x.npu_broadcast(3, 4) tensor([[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]], device='npu:0')
torch_npu.npu_dtype_cast(input, dtype) -> Tensor
执行张量数据类型(dtype)转换。
- 参数说明:
- input (Tensor) - 输入张量。
- dtype (torch.dtype) - 返回张量的目标数据类型。
- 约束说明:
- 使用示例:
>>> torch_npu.npu_dtype_cast(torch.tensor([0, 0.5, -1.]).npu(), dtype=torch.int) tensor([ 0, 0, -1], device='npu:0', dtype=torch.int32)
torch_npu.empty_with_format(size, dtype, layout, device, pin_memory, acl_format)
返回一个填充未初始化数据的张量。
- 参数说明:
- size (ListInt) - 定义输出张量shape的整数序列。可以是参数数量(可变值),也可以是列表或元组等集合。
- dtype (torch.dtype, 可选,默认值为None) - 返回张量所需数据类型。如果值为None,请使用全局默认值(请参见torch.set_default_tensor_type()).
- layout (torch.layout, 可选,默认值为torch.strided) - 返回张量所需布局。
- device (torch.device, 可选,默认值为None) - 返回张量的所需设备。
- pin_memory (Bool, 可选,默认值为False) - 如果设置此参数,返回张量将分配在固定内存中。
- acl_format (Int,默认值为2) - 返回张量所需内存格式。
- 约束说明:
- 使用示例:
>>> torch_npu.empty_with_format((2, 3), dtype=torch.float32, device="npu") tensor([[1., 1., 1.], [1., 1., 1.]], device='npu:0')
torch_npu.copy_memory_(dst, src, non_blocking=False) -> Tensor
从src拷贝元素到self张量,并返回self。
- 参数解释:
- dst (Tensor) - 拷贝源张量。
- src (Tensor) - 返回张量所需数据类型。
- non_blocking (Bool,默认值为False) - 如果设置为True且此拷贝位于CPU和NPU之间,则拷贝可能相对于主机异步发生。在其他情况下,此参数没有效果。
- 约束条件:
- 示例:
>>> a=torch.IntTensor([0, 0, -1]).npu() >>> b=torch.IntTensor([1, 1, 1]).npu() >>> a.copy_memory_(b) tensor([1, 1, 1], device='npu:0', dtype=torch.int32)
torch_npu.npu_one_hot(input, num_classes=-1, depth=1, on_value=1, off_value=0) -> Tensor
返回一个one-hot张量。input中index表示的位置采用on_value值,而其他所有位置采用off_value的值。
- 参数解释:
- input (Tensor) - 任何shape的class值。
- num_classes (Int,默认值为-1) - 待填充的轴。
- depth (Int,默认值为1) - one_hot维度的深度。
- on_value (Scalar,默认值为1) - 当indices[j] == i时输出中的填充值。
- off_value (Scalar,默认值为0) - 当indices[j] != i时输出中的填充值。
- 约束条件:
- 示例:
>>> a=torch.IntTensor([5, 3, 2, 1]).npu() >>> b=torch_npu.npu_one_hot(a, depth=5) >>> btensor([[0., 0., 0., 0., 0.], [0., 0., 0., 1., 0.], [0., 0., 1., 0., 0.], [0., 1., 0., 0., 0.]], device='npu:0')
torch_npu.npu_stride_add(x1, x2, offset1, offset2, c1_len) -> Tensor
添加两个张量的partial values,格式为NC1HWC0。
- 参数解释:
- x1 (Tensor) - 5HD张量。
- x2 (Tensor) - 与“x1”类型相同shape相同(C1值除外)的张量。
- offset1 (Scalar) - “x1”中C1的offset value。
- offset2 (Scalar) - “x2”中C1的offset value。
- c1_len (Scalar) - “y”的C1 len。该值必须小于“x1”和“x2”中C1与offset的差值。
- 约束条件:
- 示例:
>>> a=torch.tensor([[[[[1.]]]]]).npu() >>> b=torch_npu.npu_stride_add(a, a, 0, 0, 1) >>> btensor([[[[[2.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]], [[[0.]]]]], device='npu:0')
torch_npu.npu_softmax_cross_entropy_with_logits(features, labels) -> Tensor
计算softmax的交叉熵cost。
- 参数解释:
- features (Tensor) - 张量,一个“batch_size * num_classes”矩阵。
- labels (Tensor) - 与“features”同类型的张量。一个“batch_size * num_classes”矩阵。
- 约束条件:
- 示例:
torch_npu.npu_ps_roi_pooling(x, rois, spatial_scale, group_size, output_dim) -> Tensor
执行Position Sensitive ROI Pooling。
- 参数解释:
- x (Tensor) - 描述特征图的NC1HWC0张量。维度C1必须等于(int(output_dim+15)/C0)) group_size。
- rois (Tensor) - shape为[batch, 5, rois_num]的张量,用于描述ROI。每个ROI由五个元素组成:“batch_id”、“x1”、“y1”、“x2”和“y2”,其中“batch_id”表示输入特征图的index,“x1”、“y1”、“x2”,和“y2”必须大于或等于“0.0”。
- spatial_scale (Float32) - 将输入坐标映射到ROI坐标的缩放系数。
- group_size (Int32) - 指定用于编码position-sensitive评分图的组数。该值必须在(0,128)范围内。
- output_dim (Int32) - 指定输出通道数。必须大于0。
- 约束条件:
- 示例:
>>> roi = torch.tensor([[[1], [2], [3], [4], [5]], [[6], [7], [8], [9], [10]]], dtype = torch.float16).npu() >>> x = torch.tensor([[[[ 1]], [[ 2]], [[ 3]], [[ 4]], [[ 5]], [[ 6]], [[ 7]], [[ 8]]], [[[ 9]], [[10]], [[11]], [[12]], [[13]], [[14]], [[15]], [[16]]]], dtype = torch.float16).npu() >>> out = torch_npu.npu_ps_roi_pooling(x, roi, 0.5, 2, 2) >>> outtensor([[[[0., 0.], [0., 0.]], [[0., 0.], [0., 0.]]], [[[0., 0.], [0., 0.]], [[0., 0.], [0., 0.]]]], device='npu:0', dtype=torch.float16)
torch_npu.npu_roi_align(features, rois, spatial_scale, pooled_height, pooled_width, sample_num, roi_end_mode) -> Tensor
从特征图中获取ROI特征矩阵。自定义FasterRcnn算子。
- 参数解释:
- features (Tensor) - 5HD张量
- rois (Tensor) - ROI位置,shape为(N, 5)的2D张量。“N”表示ROI的数量,“5”表示ROI所在图像的index,分别为“x0”、“y0”、“x1”和“y1”。
- spatial_scale (Float32) - 指定“features”与原始图像的缩放比率。
- pooled_height (Int32) - 指定H维度。
- pooled_width (Int32) - 指定W维度。
- sample_num (Int32,默认值为2) - 指定每次输出的水平和垂直采样频率。若此属性设置为0,则采样频率等于“rois”的向上取整值(一个浮点数)。
- roi_end_mode (Int32,默认值为1)
- 约束条件:
- 示例:
>>> x = torch.FloatTensor([[[[1, 2, 3 , 4, 5, 6], [7, 8, 9, 10, 11, 12], [13, 14, 15, 16, 17, 18], [19, 20, 21, 22, 23, 24], [25, 26, 27, 28, 29, 30], [31, 32, 33, 34, 35, 36]]]]).npu() >>> rois = torch.tensor([[0, -2.0, -2.0, 22.0, 22.0]]).npu() >>> out = torch_npu.npu_roi_align(x, rois, 0.25, 3, 3, 2, 0) >>> out tensor([[[[ 4.5000, 6.5000, 8.5000], [16.5000, 18.5000, 20.5000], [28.5000, 30.5000, 32.5000]]]], device='npu:0')
torch_npu.npu_nms_v4(boxes, scores, max_output_size, iou_threshold, scores_threshold, pad_to_max_output_size=False) -> (Tensor, Tensor)
按分数降序选择标注框的子集。
- 参数解释:
- boxes (Tensor) - shape为[num_boxes, 4]的2D浮点张量。
- scores (Tensor) - shape为[num_boxes]的1D浮点张量,表示每个框(每行框)对应的一个分数。
- max_output_size (Scalar) - 表示non-max suppression下要选择的最大框数的标量。
- iou_threshold (Tensor) - 0D浮点张量,表示框与IoU重叠上限的阈值。
- scores_threshold (Tensor) - 0D浮点张量,表示决定何时删除框的分数阈值。
- pad_to_max_output_size (Bool,默认值为False) - 如果为True,则输出的selected_indices将填充为max_output_size长度。
- 返回值:
- selected_indices (Tensor) - shape为[M]的1D整数张量,表示从boxes张量中选定的index,其中M <= max_output_size。
- valid_outputs (Tensor) - 0D整数张量,表示selected_indices中有效元素的数量,有效元素首先呈现。
- 约束条件:
- 示例:
>>> boxes=torch.randn(100,4).npu() >>> scores=torch.randn(100).npu() >>> boxes.uniform_(0,100) >>> scores.uniform_(0,1) >>> max_output_size = 20 >>> iou_threshold = torch.tensor(0.5).npu() >>> scores_threshold = torch.tensor(0.3).npu() >>> npu_output = torch_npu.npu_nms_v4(boxes, scores, max_output_size, iou_threshold, scores_threshold) >>> npu_output (tensor([57, 65, 25, 45, 43, 12, 52, 91, 23, 78, 53, 11, 24, 62, 22, 67, 9, 94, 54, 92], device='npu:0', dtype=torch.int32), tensor(20, device='npu:0', dtype=torch.int32))
torch_npu.npu_nms_rotated(dets, scores, iou_threshold, scores_threshold=0, max_output_size=-1, mode=0) -> (Tensor, Tensor)
按分数降序选择旋转标注框的子集。
- 参数解释:
- dets (Tensor) - shape为[num_boxes, 5]的2D浮点张量
- scores (Tensor) - shape为[num_boxes]的1D浮点张量,表示每个框(每行框)对应的一个分数。
- iou_threshold (Float) - 表示框与IoU重叠上限阈值的标量。
- scores_threshold (Float,默认值为0) - 表示决定何时删除框的分数阈值的标量。
- max_output_size (Int,默认值为-1) - 标量整数张量,表示非最大抑制下要选择的最大框数。为-1时即不施加任何约束。
- mode (Int,默认值为0) - 指定dets布局类型。如果mode设置为0,则dets的输入值为x、y、w、h和角度。如果mode设置为1,则dets的输入值为x1、y1、x2、y2和角度。
- 返回值:
- selected_index (Tensor) - shape为[M]的1D整数张量,表示从dets张量中选定的index,其中M <= max_output_size。
- selected_num (Tensor) - 0D整数张量,表示selected_indices中有效元素的数量。
- 约束条件:
- 示例:
>>> dets=torch.randn(100,5).npu() >>> scores=torch.randn(100).npu() >>> dets.uniform_(0,100) >>> scores.uniform_(0,1) >>> output1, output2 = torch_npu.npu_nms_rotated(dets, scores, 0.2, 0, -1, 1) >>> output1 tensor([76, 48, 15, 65, 91, 82, 21, 96, 62, 90, 13, 59, 0, 18, 47, 23, 8, 56, 55, 63, 72, 39, 97, 81, 16, 38, 17, 25, 74, 33, 79, 44, 36, 88, 83, 37, 64, 45, 54, 41, 22, 28, 98, 40, 30, 20, 1, 86, 69, 57, 43, 9, 42, 27, 71, 46, 19, 26, 78, 66, 3, 52], device='npu:0', dtype=torch.int32) >>> output2tensor([62], device='npu:0', dtype=torch.int32)
torch_npu.npu_lstm(x, weight, bias, seqMask, h, c, has_biases, num_layers, dropout, train, bidirectional, batch_first, flag_seq, direction)
计算DynamicRNN。
- 参数解释:
- x (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_NZ。
- weight (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_ZN_LSTM。
- bias (Tensor) - 1D张量。数据类型:float16, float32;格式:ND。
- seqMask (Tensor) - 张量。仅支持为FRACTAL_NZ格式的float16和ND格式的int32类型。
- h (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_NZ。
- c (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_NZ。
- has_biases (Bool) - 如果值为True,则存在偏差。
- num_layers (Int) - 循环层数,目前只支持单层。
- dropout (Float) - 如果值为非零,则在除最后一层外的每个LSTM层的输出上引入一个dropout层,丢弃概率等于dropout参数值。目前不支持。
- train (Bool,默认值为True) - 标识训练是否在op进行的bool参数。
- bidirectional (Bool) - 如果值为True,LSTM为双向。当前不支持。
- batch_first (Bool) - 如果值为True,则输入和输出张量将表示为(batch, seq, feature)。当前不支持。
- flag_seq (Bool) - 如果值为True,输入为PackSequnce。当前不支持。
- direction (Bool) - 如果值为True,则方向为“REDIRECTIONAL”,否则为“UNIDIRECTIONAL”。
- 返回值:
- y (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_NZ。
- output_h (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_NZ。
- output_c (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_NZ。
- i (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_NZ。
- j (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_NZ。
- f (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_NZ。
- o (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_NZ。
- tanhct (Tensor) - 4D张量。数据类型:float16, float32;格式:FRACTAL_NZ。
- 约束条件:
- 示例:
torch_npu.npu_iou(bboxes, gtboxes, mode=0) -> Tensor torch_npu.npu_ptiou(bboxes, gtboxes, mode=0) -> Tensor
根据ground-truth和预测区域计算交并比(IoU)或前景交叉比(IoF)。
- 参数解释:
- bboxes (Tensor) - 输入张量。
- gtboxes (Tensor) - 输入张量。
- mode (Int,默认值为0) - 0为IoU模式,1为IoF模式。
- 约束条件:
- 示例:
>>> bboxes = torch.tensor([[0, 0, 10, 10], [10, 10, 20, 20], [32, 32, 38, 42]], dtype=torch.float16).to("npu") >>> gtboxes = torch.tensor([[0, 0, 10, 20], [0, 10, 10, 10], [10, 10, 20, 20]], dtype=torch.float16).to("npu") >>> output_iou = torch_npu.npu_iou(bboxes, gtboxes, 0) >>> output_iou tensor([[0.4985, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000], [0.0000, 0.9961, 0.0000]], device='npu:0', dtype=torch.float16)
torch_npu.npu_pad(input, paddings) -> Tensor
填充张量。
- 参数解释:
- input (Tensor) - 输入张量。
- paddings (ListInt) - 数据类型:int32、int64。
- 约束条件:
- 示例:
>>> input = torch.tensor([[20, 20, 10, 10]], dtype=torch.float16).to("npu") >>> paddings = [1, 1, 1, 1] >>> output = torch_npu.npu_pad(input, paddings) >>> output tensor([[ 0., 0., 0., 0., 0., 0.], [ 0., 20., 20., 10., 10., 0.], [ 0., 0., 0., 0., 0., 0.]], device='npu:0', dtype=torch.float16)
torch_npu.npu_nms_with_mask(input, iou_threshold) -> (Tensor, Tensor, Tensor)
生成值0或1,用于nms算子确定有效位。
- 参数解释:
- input (Tensor) - 输入张量
- iou_threshold (Scalar) - 阈值。如果超过此阈值,则值为1,否则值为0。
- 返回值:
- selected_boxes (Tensor) - shape为[N,5]的2D张量,表示filtered box,包括proposal box和相应的置信度分数。
- selected_idx (Tensor) - shape为[N]的1D张量,表示输入建议框的index。
- selected_mask (Tensor) - shape为[N]的1D张量,判断输出建议框是否有效。
- 约束条件:
- 示例:
>>> input = torch.tensor([[0.0, 1.0, 2.0, 3.0, 0.6], [6.0, 7.0, 8.0, 9.0, 0.4]], dtype=torch.float16).to("npu") >>> iou_threshold = 0.5 >>> output1, output2, output3, = torch_npu.npu_nms_with_mask(input, iou_threshold) >>> output1 tensor([[0.0000, 1.0000, 2.0000, 3.0000, 0.6001], [6.0000, 7.0000, 8.0000, 9.0000, 0.3999]], device='npu:0', dtype=torch.float16) >>> output2 tensor([0, 1], device='npu:0', dtype=torch.int32) >>> output3 tensor([1, 1], device='npu:0', dtype=torch.uint8)
torch_npu.npu_bounding_box_encode(anchor_box, ground_truth_box, means0, means1, means2, means3, stds0, stds1, stds2, stds3) -> Tensor
计算标注框和ground truth真值框之间的坐标变化。自定义FasterRcnn算子。
- 参数解释:
- anchor_box (Tensor) - 输入张量。锚点框。shape为(N,4)数据类型为float32的2D张量。“N”表示标注框的数量,“4”表示“x0”、“x1”、“y0”和“y1”。
- ground_truth_box (Tensor) - 输入张量。真值框。shape为(N,4)数据类型为float32的2D张量。“N”表示标注框的数量,“4”表示“x0”、“x1”、“y0”和“y1”。
- means0 (Float) - index。
- means1 (Float) - index。
- means2 (Float) - index。
- means3 (Float, 默认值为[0,0,0,0]) - index。 "deltas" = "deltas" x "stds" + "means"
- stds0 (Float) - index。
- stds1 (Float) - index。
- stds2 (Float) - index。
- stds3 (Float, 默认值:[1.0,1.0,1.0,1.0]) -index。 "deltas" = "deltas" x "stds" + "means"
- 约束条件:
- 示例:
>>> anchor_box = torch.tensor([[1., 2., 3., 4.], [3.,4., 5., 6.]], dtype = torch.float32).to("npu") >>> ground_truth_box = torch.tensor([[5., 6., 7., 8.], [7.,8., 9., 6.]], dtype = torch.float32).to("npu") >>> output = torch_npu.npu_bounding_box_encode(anchor_box, ground_truth_box, 0, 0, 0, 0, 0.1, 0.1, 0.2, 0.2) >>> outputtensor([[13.3281, 13.3281, 0.0000, 0.0000], [13.3281, 6.6641, 0.0000, -5.4922]], device='npu:0')
torch_npu.npu_bounding_box_decode(rois, deltas, means0, means1, means2, means3, stds0, stds1, stds2, stds3, max_shape, wh_ratio_clip) -> Tensor
根据rois和deltas生成标注框。自定义FasterRcnn算子。
- 参数解释:
- rois (Tensor) - 区域候选网络(RPN)生成的region of interests(ROI)。shape为(N,4)数据类型为float32或float16的2D张量。“N”表示ROI的数量, “4”表示“x0”、“x1”、“y0”和“y1”。
- deltas (Tensor) - RPN生成的ROI和真值框之间的绝对变化。shape为(N,4)数据类型为float32或float16的2D张量。“N”表示错误数,“4”表示“dx”、“dy”、“dw”和“dh”。
- means0 (Float) - index。
- means1 (Float) - index。
- means2 (Float) - index。
- means3 (Float,默认值为[0,0,0,0]) - index。"deltas" = "deltas" x "stds" + "means"
- stds0 (Float) - index。
- stds1 (Float) - index。
- stds2 (Float) - index。
- stds3 (Float, 默认值:[1.0,1.0,1.0,1.0]) - index。"deltas" = "deltas" x "stds" + "means"
- max_shape (ListInt of length 2) - shape[h, w],指定传输到网络的图像大小。用于确保转换后的bbox shape不超过“max_shape”。
- wh_ratio_clip (Float) -“dw”和“dh”的值在(-wh_ratio_clip, wh_ratio_clip)范围内。
- 约束条件:
- 示例:
>>> rois = torch.tensor([[1., 2., 3., 4.], [3.,4., 5., 6.]], dtype = torch.float32).to("npu") >>> deltas = torch.tensor([[5., 6., 7., 8.], [7.,8., 9., 6.]], dtype = torch.float32).to("npu") >>> output = torch_npu.npu_bounding_box_decode(rois, deltas, 0, 0, 0, 0, 1, 1, 1, 1, (10, 10), 0.1) >>> output tensor([[2.5000, 6.5000, 9.0000, 9.0000], [9.0000, 9.0000, 9.0000, 9.0000]], device='npu:0')
torch_npu.npu_gru(input, hx, weight_input, weight_hidden, bias_input, bias_hidden, seq_length, has_biases, num_layers, dropout, train, bidirectional, batch_first) -> (Tensor, Tensor, Tensor, Tensor, Tensor, Tensor)
计算DynamicGRUV2。
- 参数解释:
- input (Tensor) - 数据类型:float16;格式:FRACTAL_NZ。
- hx (Tensor) - 数据类型:float16, float32;格式:FRACTAL_NZ。
- weight_input (Tensor) - 数据类型:float16;格式:FRACTAL_Z。
- weight_hidden (Tensor) - 数据类型:float16;格式:FRACTAL_Z。
- bias_input (Tensor) - 数据类型:float16, float32;格式:ND。
- bias_hidden (Tensor) - 数据类型:float16, float32;格式:ND。
- seq_length (Tensor) - 数据类型:int32;格式:ND。
- has_biases (Bool,默认值为True)
- num_layers (Int)
- dropout (Float)
- train (Bool,默认值为True) - 标识训练是否在op进行的bool参数。
- bidirectional (Bool,默认值为True)
- batch_first (Bool,默认值为True)
- Returns:
- y (Tensor) - 数据类型:float16, float32;格式:FRACTAL_NZ。
- output_h (Tensor) - 数据类型:float16, float32;格式:FRACTAL_NZ。
- update (Tensor) - 数据类型:float16, float32;格式:FRACTAL_NZ。
- reset (Tensor) - 数据类型:float16, float32;格式:FRACTAL_NZ。
- new (Tensor) - 数据类型:float16, float32;格式:FRACTAL_NZ。
- hidden_new (Tensor) - 数据类型:float16, float32;格式:FRACTAL_NZ。
- 约束条件:
- 示例:
torch_npu.npu_random_choice_with_mask(x, count=256, seed=0, seed2=0) -> (Tensor, Tensor)
混洗非零元素的index。
- 参数解释:
- x (Tensor) - 输入张量。
- count (Int,默认值为256) - 输出计数。如果值为0,则输出所有非零元素。
- seed (Int,默认值为0) - 数据类型:int32,int64。
- seed2 (Int,默认值为2) - 数据类型:int32,int64。
- 返回值:
- y (Tensor) - 2D张量, 非零元素的index。
- mask (Tensor) - 1D张量, 确定对应index是否有效。
- 约束条件:
- 示例:
>>> x = torch.tensor([1, 0, 1, 0], dtype=torch.bool).to("npu") >>> result, mask = torch_npu.npu_random_choice_with_mask(x, 2, 1, 0) >>> resulttensor([[0], [2]], device='npu:0', dtype=torch.int32) >>> mask tensor([True, True], device='npu:0')
torch_npu.npu_batch_nms(self, scores, score_threshold, iou_threshold, max_size_per_class, max_total_size, change_coordinate_frame=False, transpose_box=False) -> (Tensor, Tensor, Tensor, Tensor)
根据batch分类计算输入框评分,通过评分排序,删除评分高于阈值(iou_threshold)的框,支持多批多类处理。通过NonMaxSuppression(nms)操作可有效删除冗余的输入框,提高检测精度。NonMaxSuppression:抑制不是极大值的元素,搜索局部的极大值,常用于计算机视觉任务中的检测类模型。
- 参数解释:
- self (Tensor) - 必填值,输入框的tensor,包含batch大小,数据类型Float16,输入示例:[batch_size, num_anchors, q, 4],其中q=1或q=num_classes。
- scores (Tensor) - 必填值,输入tensor,数据类型Float16,输入示例:[batch_size, num_anchors, num_classes]。
- score_threshold (Float32) - 必填值,指定评分过滤器的iou_threshold,用于筛选框,去除得分较低的框,数据类型Float32。
- iou_threshold (Float32) - 必填值,指定nms的iou_threshold,用于设定阈值,去除高于阈值的的框,数据类型Float32。
- max_size_per_class (Int) - 必填值,指定每个类别的最大可选的框数,数据类型Int。
- max_total_size (Int) - 必填值,指定每个batch最大可选的框数,数据类型Int。
- change_coordinate_frame (Bool,默认值为False) -可选值, 是否正则化输出框坐标矩阵,数据类型Bool。
- transpose_box (Bool,默认值为False) - 可选值,确定是否在此op之前插入转置,数据类型Bool。True表示boxes使用4,N排布。 False表示boxes使用过N,4排布。
- 返回值:
- nmsed_boxes (Tensor) - shape为(batch, max_total_size, 4)的3D张量,指定每批次输出的nms框,数据类型Float16。
- nmsed_scores (Tensor) - shape为(batch, max_total_size)的2D张量,指定每批次输出的nms分数,数据类型Float16。
- nmsed_classes (Tensor) - shape为(batch, max_total_size)的2D张量,指定每批次输出的nms类,数据类型Float16。
- nmsed_num (Tensor) - shape为(batch)的1D张量,指定nmsed_boxes的有效数量,数据类型Int32。
- 约束条件:
- 示例:
>>> boxes = torch.randn(8, 2, 4, 4, dtype = torch.float32).to("npu") >>> scores = torch.randn(3, 2, 4, dtype = torch.float32).to("npu") >>> nmsed_boxes, nmsed_scores, nmsed_classes, nmsed_num = torch_npu.npu_batch_nms(boxes, scores, 0.3, 0.5, 3, 4) >>> nmsed_boxes >>> nmsed_scores >>> nmsed_classes >>> nmsed_num
torch_npu.npu_slice(self, offsets, size) -> Tensor
从张量中提取切片。
- 参数解释:
- self (Tensor) - 输入张量。
- offsets (ListInt) - 数据类型:int32,int64。
- size (ListInt) - 数据类型:int32,int64。
- 约束条件:
- 示例:
>>> input = torch.tensor([[1,2,3,4,5], [6,7,8,9,10]], dtype=torch.float16).to("npu") >>> offsets = [0, 0]>>> size = [2, 2] >>> output = torch_npu.npu_slice(input, offsets, size) >>> output tensor([[1., 2.], [6., 7.]], device='npu:0', dtype=torch.float16)
torch_npu._npu_dropout(self, p) -> (Tensor, Tensor)
不使用种子(seed)进行dropout结果计数。与torch.dropout相似,优化NPU设备实现。
- 参数解释:
- self (Tensor) - 输入张量。
- p (Float) - 丢弃概率。
- 约束条件:
- 示例:
>>> input = torch.tensor([1.,2.,3.,4.]).npu() >>> input tensor([1., 2., 3., 4.], device='npu:0') >>> prob = 0.3>>> output, mask = torch_npu._npu_dropout(input, prob) >>> output tensor([0.0000, 2.8571, 0.0000, 0.0000], device='npu:0') >>> mask tensor([ 98, 255, 188, 186, 120, 157, 175, 159, 77, 223, 127, 79, 247, 151, 253, 255], device='npu:0', dtype=torch.uint8)
torch_npu.npu_indexing(self, begin, end, strides, begin_mask=0, end_mask=0, ellipsis_mask=0, new_axis_mask=0, shrink_axis_mask=0) -> Tensor
使用“begin,end,strides”数组对index结果进行计数。
- 参数解释:
- self (Tensor) - 输入张量。
- begin (ListInt) - 待选择的第一个值的index。
- end (ListInt) - 待选择的最后一个值的index。
- strides (ListInt) - index增量。
- begin_mask (Int,默认值为0) - 位掩码(bitmask),其中位“i”为“1”意味着忽略开始值,尽可能使用最大间隔。
- end_mask (Int,默认值为0) - 类似于“begin_mask”。
- ellipsis_mask (Int,默认值为0) - 位掩码,其中位“i”为“1”意味着第“i”个位置实际上是省略号。
- new_axis_mask (Int,默认值为0) - 位掩码,其中位“i”为“1”意味着在第“i”位创建新的1D shape。
- shrink_axis_mask (Int,默认值为0) - 位掩码,其中位“i”意味着第“i”位应缩小维数。
- 约束条件:
- 示例:
>>> input = torch.tensor([[1, 2, 3, 4],[5, 6, 7, 8]], dtype=torch.int32).to("npu") >>> input tensor([[1, 2, 3, 4], [5, 6, 7, 8]], device='npu:0', dtype=torch.int32) >>> output = torch_npu.npu_indexing(input1, [0, 0], [2, 2], [1, 1]) >>> output tensor([[1, 2], [5, 6]], device='npu:0', dtype=torch.int32)
torch_npu.npu_ifmr(Tensor data, Tensor data_min, Tensor data_max, Tensor cumsum, float min_percentile, float max_percentile, float search_start, float search_end, float search_step, bool with_offset) -> (Tensor, Tensor)
使用“begin,end,strides”数组对ifmr结果进行计数。
- 参数解释:
- data (Tensor) - 特征图张量。
- data_min (Tensor) - 特征图最小值的张量。
- data_max (Tensor) - 特征图最大值的张量。
- cumsum (Tensor) - cumsum bin数据张量。
- min_percentile (Float) - 最小初始化百分位数。
- max_percentile (Float) - 最大初始化百分位数。
- search_start (Float) - 搜索起点。
- search_end (Float) - 搜索终点。
- search_step (Float) - 搜索步长。
- with_offset (Bool) - 是否使用offset。
- 返回值:
- scale (Tensor) - 最优尺度。
- offset (Tensor) - 最优offset。
- 约束条件:
- 示例:
>>> input = torch.rand((2,2,3,4),dtype=torch.float32).npu() >>> input tensor([[[[0.4508, 0.6513, 0.4734, 0.1924], [0.0402, 0.5502, 0.0694, 0.9032], [0.4844, 0.5361, 0.9369, 0.7874]], [[0.5157, 0.1863, 0.4574, 0.8033], [0.5986, 0.8090, 0.7605, 0.8252], [0.4264, 0.8952, 0.2279, 0.9746]]], [[[0.0803, 0.7114, 0.8773, 0.2341], [0.6497, 0.0423, 0.8407, 0.9515], [0.1821, 0.5931, 0.7160, 0.4968]], [[0.7977, 0.0899, 0.9572, 0.0146], [0.2804, 0.8569, 0.2292, 0.1118], [0.5747, 0.4064, 0.8370, 0.1611]]]], device='npu:0') >>> min_value = torch.min(input) >>> min_value tensor(0.0146, device='npu:0') >>> max_value = torch.max(input) >>> max_value tensor(0.9746, device='npu:0') >>> hist = torch.histc(input.to('cpu'), bins=128, min=min_value.to('cpu'), max=max_value.to('cpu')) >>> hist tensor([1., 0., 0., 2., 0., 0., 0., 1., 1., 0., 1., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0., 0., 2., 1., 0., 0., 0., 0., 2., 1., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 0., 0., 1., 1., 0., 1., 1., 0., 1., 0., 1., 0., 0., 1., 0., 1., 0., 0., 1., 0., 0., 2., 0., 0., 0., 0., 0., 0., 2., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 1., 0., 0., 0., 1., 1., 2., 0., 0., 1., 1., 1., 0., 1., 0., 0., 1., 0., 1., 1., 0., 0., 0., 1., 0., 1., 1., 0., 1.]) >>> cdf = torch.cumsum(hist,dim=0).int().npu() >>> cdf tensor([ 1, 1, 1, 3, 3, 3, 3, 4, 5, 5, 6, 6, 7, 7, 7, 7, 7, 7, 7, 8, 8, 8, 10, 11, 11, 11, 11, 11, 13, 14, 14, 14, 14, 14, 14, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 16, 16, 17, 17, 17, 17, 18, 19, 19, 20, 21, 21, 22, 22, 23, 23, 23, 24, 24, 25, 25, 25, 26, 26, 26, 28, 28, 28, 28, 28, 28, 28, 30, 30, 30, 30, 30, 30, 30, 30, 31, 32, 32, 32, 32, 32, 32, 33, 33, 33, 33, 34, 35, 37, 37, 37, 38, 39, 40, 40, 41, 41, 41, 42, 42, 43, 44, 44, 44, 44, 45, 45, 46, 47, 47, 48], device='npu:0', dtype=torch.int32) >>> scale, offset = torch_npu.npu_ifmr(input, min_value, max_value, cdf, min_percentile=0.999999, max_percentile=0.999999, search_start=0.7, search_end=1.3, search_step=0.01, with_offset=False) >>> scale tensor(0.0080, device='npu:0') >>> offset tensor(0., device='npu:0')
torch_npu.npu_max(self, dim, keepdim=False) -> (Tensor, Tensor)
使用dim对最大结果进行计数。类似于torch.max, 优化NPU设备实现。
- 参数解释:
- self (Tensor) - 输入张量。
- dim (Int) - 待降低维度。
- keepdim (Bool,默认值为False) - 输出张量是否保留dim。
- 返回值:
- values (Tensor) - 输入张量中的最大值。
- indices (Tensor) - 输入张量中最大值的index。
- 约束条件:
- 示例:
>>> input = torch.randn(2, 2, 2, 2, dtype = torch.float32).npu() >>> input tensor([[[[-1.8135, 0.2078], [-0.6678, 0.7846]], [[ 0.6458, -0.0923], [-0.2124, -1.9112]]], [[[-0.5800, -0.4979], [ 0.2580, 1.1335]], [[ 0.6669, 0.1876], [ 0.1160, -0.1061]]]], device='npu:0') >>> outputs, indices = torch_npu.npu_max(input, 2) >>> outputs tensor([[[-0.6678, 0.7846], [ 0.6458, -0.0923]], [[ 0.2580, 1.1335], [ 0.6669, 0.1876]]], device='npu:0') >>> indices tensor([[[1, 1], [0, 0]], [[1, 1], [0, 0]]], device='npu:0', dtype=torch.int32)
torch_npu.npu_min(self, dim, keepdim=False) -> (Tensor, Tensor)
使用dim对最小结果进行计数。类似于torch.min, 优化NPU设备实现。
- 参数解释:
- self (Tensor) - 输入张量。
- dim (Int) - 待降低维度。
- keepdim (Bool) - 输出张量是否保留dim。
- 返回值:
- values (Tensor) - 输入张量中的最小值。
- indices (Tensor) - 输入张量中最小值的index。
- 约束条件:
- 示例:
>>> input = torch.randn(2, 2, 2, 2, dtype = torch.float32).npu() >>> input tensor([[[[-0.9909, -0.2369], [-0.9569, -0.6223]], [[ 0.1157, -0.3147], [-0.7761, 0.1344]]], [[[ 1.6292, 0.5953], [ 0.6940, -0.6367]], [[-1.2335, 0.2131], [ 1.0748, -0.7046]]]], device='npu:0') >>> outputs, indices = torch_npu.npu_min(input, 2) >>> outputs tensor([[[-0.9909, -0.6223], [-0.7761, -0.3147]], [[ 0.6940, -0.6367], [-1.2335, -0.7046]]], device='npu:0') >>> indices tensor([[[0, 1], [1, 0]], [[1, 1], [0, 1]]], device='npu:0', dtype=torch.int32)
torch_npu.npu_scatter(self, indices, updates, dim) -> Tensor
使用dim对scatter结果进行计数。类似于torch.scatter,优化NPU设备实现。
- 参数解释:
- self (Tensor) - 输入张量。
- indices (Tensor) - 待scatter的元素index,可以为空,也可以与src有相同的维数。当为空时,操作返回“self unchanged”。
- updates (Tensor) - 待scatter的源元素。
- dim (Int) - 要进行index的轴。
- 约束条件:
- 示例:
>>> input = torch.tensor([[1.6279, 0.1226], [0.9041, 1.0980]]).npu() >>> input tensor([[1.6279, 0.1226], [0.9041, 1.0980]], device='npu:0') >>> indices = torch.tensor([0, 1],dtype=torch.int32).npu() >>> indices tensor([0, 1], device='npu:0', dtype=torch.int32) >>> updates = torch.tensor([-1.1993, -1.5247]).npu() >>> updates tensor([-1.1993, -1.5247], device='npu:0') >>> dim = 0 >>> output = torch_npu.npu_scatter(input, indices, updates, dim) >>> output tensor([[-1.1993, 0.1226], [ 0.9041, -1.5247]], device='npu:0')
torch_npu.npu_layer_norm_eval(input, normalized_shape, weight=None, bias=None, eps=1e-05) -> Tensor
对层归一化结果进行计数。与torch.nn.functional.layer_norm相同, 优化NPU设备实现。
- 参数解释:
- input (Tensor) - 输入张量。
- normalized_shape (ListInt) - size为预期输入的输入shape。
- weight (Tensor, 可选,默认值为None) - gamma张量。
- bias (Tensor, 可选默认值为None) - beta张量。
- eps (Float,默认值为1e-5) - 为保证数值稳定性添加到分母中的ε值。
- 约束条件:
- 示例:
>>> input = torch.rand((6, 4), dtype=torch.float32).npu() >>> input tensor([[0.1863, 0.3755, 0.1115, 0.7308], [0.6004, 0.6832, 0.8951, 0.2087], [0.8548, 0.0176, 0.8498, 0.3703], [0.5609, 0.0114, 0.5021, 0.1242], [0.3966, 0.3022, 0.2323, 0.3914], [0.1554, 0.0149, 0.1718, 0.4972]], device='npu:0') >>> normalized_shape = input.size()[1:] >>> normalized_shape torch.Size([4]) >>> weight = torch.Tensor(*normalized_shape).npu() >>> weight tensor([ nan, 6.1223e-41, -8.3159e-20, 9.1834e-41], device='npu:0') >>> bias = torch.Tensor(*normalized_shape).npu() >>> bias tensor([5.6033e-39, 6.1224e-41, 6.1757e-39, 6.1224e-41], device='npu:0') >>> output = torch_npu.npu_layer_norm_eval(input, normalized_shape, weight, bias, 1e-5) >>> output tensor([[ nan, 6.7474e-41, 8.3182e-20, 2.0687e-40], [ nan, 8.2494e-41, -9.9784e-20, -8.2186e-41], [ nan, -2.6695e-41, -7.7173e-20, 2.1353e-41], [ nan, -1.3497e-41, -7.1281e-20, -6.9827e-42], [ nan, 3.5663e-41, 1.2002e-19, 1.4314e-40], [ nan, -6.2792e-42, 1.7902e-20, 2.1050e-40]], device='npu:0')
torch_npu.npu_alloc_float_status(self) -> Tensor
生成一个包含8个0的一维张量。
- 参数解释:
- self (Tensor) - 任何张量。
- 约束条件:
- 示例:
>>> input = torch.randn([1,2,3]).npu() >>> output = torch_npu.npu_alloc_float_status(input) >>> input tensor([[[ 2.2324, 0.2478, -0.1056], [ 1.1273, -0.2573, 1.0558]]], device='npu:0') >>> output tensor([0., 0., 0., 0., 0., 0., 0., 0.], device='npu:0')
torch_npu.npu_get_float_status(self) -> Tensor
计算npu_get_float_status算子函数。
- 参数解释:
- self (Tensor) - 数据内存地址张量,数据类型为float32。
- 约束条件:
- 示例:
>>> x = torch.rand(2).npu() >>> torch_npu.npu_get_float_status(x) tensor([0., 0., 0., 0., 0., 0., 0., 0.], device='npu:0')
torch_npu.npu_clear_float_status(self) -> Tensor
在每个核中设置地址0x40000的值为0。
- 参数解释:
- self (Tensor) - 数据类型为float32的张量。
- 约束条件:
- 示例:
>>> x = torch.rand(2).npu() >>> torch_npu.npu_clear_float_status(x) tensor([0., 0., 0., 0., 0., 0., 0., 0.], device='npu:0')
torch_npu.npu_confusion_transpose(self, perm, shape, transpose_first) -> Tensor
混淆reshape和transpose运算。
- 参数解释:
- self (Tensor) - 数据类型:float16、float32、int8、int16、int32、int64、uint8、uint16、uint32、uint64。
- perm (ListInt) - self张量的维度排列。
- shape (ListInt) - 输入shape。
- transpose_first (Bool) - 如果值为True,首先执行transpose,否则先执行reshape。
- 约束条件:
- 示例:
>>> x = torch.rand(2, 3, 4, 6).npu() >>> x.shape torch.Size([2, 3, 4, 6]) >>> y = torch_npu.npu_confusion_transpose(x, (0, 2, 1, 3), (2, 4, 18), True) >>> y.shape torch.Size([2, 4, 18]) >>> y2 = torch_npu.npu_confusion_transpose(x, (0, 2, 1), (2, 12, 6), False) >>> y2.shape torch.Size([2, 6, 12])
torch_npu.npu_bmmV2(self, mat2, output_sizes) -> Tensor
将矩阵“a”乘以矩阵“b”,生成“a*b”。
- 参数解释:
- self (Tensor) - 2D或更高维度矩阵张量。数据类型:float16、float32、int32。格式:[ND, NHWC, FRACTAL_NZ]。
- mat2 (Tensor) - 2D或更高维度矩阵张量。数据类型:float16、float32、int32。格式:[ND, NHWC, FRACTAL_NZ]。
- output_sizes (ListInt,默认值为[]) - 输出的shape,用于matmul的反向传播。
- 约束条件:
- 示例:
>>> mat1 = torch.randn(10, 3, 4).npu() >>> mat2 = torch.randn(10, 4, 5).npu() >>> res = torch_npu.npu_bmmV2(mat1, mat2, []) >>> res.shape torch.Size([10, 3, 5])
torch_npu.fast_gelu(self) -> Tensor
计算输入张量中fast_gelu的梯度。
- 参数解释:
- self (Tensor) - 数据类型:float16、float32。
- 约束条件:
- 示例:
>>> x = torch.rand(2).npu() >>> x tensor([0.5991, 0.4094], device='npu:0') >>> torch_npu.fast_gelu(x) tensor([0.4403, 0.2733], device='npu:0')
torch_npu.npu_deformable_conv2d(self, weight, offset, bias, kernel_size, stride, padding, dilation=[1,1,1,1], groups=1, deformable_groups=1, modulated=True) -> (Tensor, Tensor)
使用预期输入计算变形卷积输出(deformed convolution output)。
- 参数解释:
- self (Tensor) - 输入图像的4D张量。格式为“NHWC”,数据按以下顺序存储:[batch, in_height, in_width, in_channels]。
- weight (Tensor) - 可学习过滤器的4D张量。数据类型需与self相同。格式为“HWCN”,数据按以下顺序存储:[filter_height, filter_width, in_channels / groups, out_channels]。
- offset (Tensor) - x-y坐标偏移和掩码的4D张量。格式为“NHWC”,数据按以下顺序存储:[batch, out_height, out_width, deformable_groups * filter_height * filter_width * 3]。
- bias (Tensor,可选) - 过滤器输出附加偏置(additive bias)的1D张量,数据按[out_channels]的顺序存储。
- kernel_size (ListInt of length 2) - 内核大小,2个整数的元组/列表。
- stride (ListInt) - 4个整数的列表,表示每个输入维度的滑动窗口步长。维度顺序根据self的数据格式解释。N维和C维必须设置为1。
- padding (ListInt) - 4个整数的列表,表示要添加到输入每侧(顶部、底部、左侧、右侧)的像素数。
- dilations (ListInt,默认值为[1, 1, 1, 1]) - 4个整数的列表,表示输入每个维度的膨胀系数(dilation factor)。维度顺序根据self的数据格式解释。N维和C维必须设置为1。
- groups (Int,默认值为1) - int32类型单整数,表示从输入通道到输出通道的阻塞连接数。In_channels和out_channels需都可被“groups”数整除。
- deformable_groups (Int,默认值为1) - int32类型单整数,表示可变形组分区的数量。In_channels需可被“deformable_groups”数整除。
- modulated (Bool,可选,默认值为True) - 指定DeformableConv2D版本。True表示v2版本, False表示v1版本,目前仅支持v2。
- 约束条件:
- 示例:
>>> x = torch.rand(16, 32, 32, 32).npu() >>> weight = torch.rand(32, 32, 5, 5).npu() >>> offset = torch.rand(16, 75, 32, 32).npu() >>> output, _ = torch_npu.npu_deformable_conv2d(x, weight, offset, None, kernel_size=[5, 5], stride = [1, 1, 1, 1], padding = [2, 2, 2, 2]) >>> output.shape torch.Size([16, 32, 32, 32])
torch_npu.npu_anchor_response_flags(self, featmap_size, stride, num_base_anchors) -> Tensor
在单个特征图中生成锚点的责任标志。
- 参数解释:
- self (Tensor) - 真值框,shape为[batch, 4]的2D张量。
- featmap_size (ListInt of length 2) - 特征图大小。
- strides (ListInt of length 2) - 当前水平的步长。
- num_base_anchors (Int) - base anchors的数量。
- 约束条件:
- 示例:
>>> x = torch.rand(100, 4).npu() >>> y = torch_npu.npu_anchor_response_flags(x, [60, 60], [2, 2], 9) >>> y.shape torch.Size([32400])
torch_npu.npu_yolo_boxes_encode(self, gt_bboxes, stride, performance_mode=False) -> Tensor
根据YOLO的锚点框(anchor box)和真值框(ground-truth box)生成标注框。自定义mmdetection算子。
- 参数解释:
- self (Tensor) - YOLO训练集生成的锚点框。shape为(N, 4)数据类型为float32或float16的2D张量。“N”表示ROI的数量,值“4”表示(tx, ty, tw, th)。
- gt_bboxes (Tensor) - 转换目标,例如真值框。shape为(N, 4)数据类型为float32或float16的2D张量。“N”表示ROI的数量,值“4”表示“dx”、“dy”、“dw”和“dh”。
- strides (Tensor) - 各框比例。shape为(N,)数据类型为int32的1D张量。“N”表示ROI的数量。
- performance_mode (Bool,默认值为False) - 选择性能模式为“high_precision”或“high_performance”。如果值为True,则性能模式为“high_performance”;如果值为False,则性能模式为“high_precision”。当输入数据类型为float32时,选择“high_precision”,输出张量精度将小于0.0001。当输入数据类型为float16时,选择“high_performance”,ops将是最佳性能,但精度将只小于0.005。
- 约束条件:
- 示例:
>>> anchor_boxes = torch.rand(2, 4).npu() >>> gt_bboxes = torch.rand(2, 4).npu() >>> stride = torch.tensor([2, 2], dtype=torch.int32).npu() >>> output = torch_npu.npu_yolo_boxes_encode(anchor_boxes, gt_bboxes, stride, False) >>> output.shape torch.Size([2, 4])
torch_npu.npu_grid_assign_positive(self, overlaps, box_responsible_flags, max_overlaps, argmax_overlaps, gt_max_overlaps, gt_argmax_overlaps, num_gts, pos_iou_thr, min_pos_iou, gt_max_assign_all) -> Tensor
执行position-sensitive的候选区域池化梯度计算。
- 参数解释:
- self (Tensor) - float16或float32类型的张量, shape为(n, )。
- overlaps (Tensor) - 数据类型与assigned_gt_inds相同,表示gt_bboxes和bboxes之间的IoU,shape为(k,n)。
- box_responsible_flags (Tensor) - 支持uint8数据类型。表示框是否responsible的标志。
- max_overlaps (Tensor) - 数据类型与assigned_gt_inds. overlaps.max(axis=0)相同。
- argmax_overlaps (Tensor) - 支持uint32数据类型,overlaps.argmax(axis=0)。
- gt_max_overlaps (Tensor) - 数据类型与assigned_gt_inds. overlaps.max(axis=1)相同。
- gt_argmax_overlaps (Tensor) - 支持uint32数据类型, overlaps.argmax(axis=1)。
- num_gts (Tensor) - 支持uint32数据类型,real k ,shape为 (1, )。
- pos_iou_thr (Float) - 正检测框的IoU阈值。
- min_pos_iou (Float) - 检测框被视为正检测框的最小IoU
- gt_max_assign_all (Bool) - 是否将与某个gt有相同最高重叠的所有检测框分配给该gt。
- 约束条件:
- 示例:
>>> assigned_gt_inds = torch.rand(4).npu() >>> overlaps = torch.rand(2,4).npu() >>> box_responsible_flags = torch.tensor([1, 1, 1, 0], dtype=torch.uint8).npu() >>> max_overlap = torch.rand(4).npu() >>> argmax_overlap = torch.tensor([1, 0, 1, 0], dtype=torch.int32).npu() >>> gt_max_overlaps = torch.rand(2).npu() >>> gt_argmax_overlaps = torch.tensor([1, 0],dtype=torch.int32).npu() >>> output = torch_npu.npu_grid_assign_positive(assigned_gt_inds, overlaps, box_responsible_flags, max_overlap, argmax_overlap, gt_max_overlaps, gt_argmax_overlaps, 128, 0.5, 0., True) >>> output.shape torch.Size([4])
torch_npu.npu_normalize_batch(self, seq_len, normalize_type=0) -> Tensor
执行批量归一化。
- 参数解释:
- self (Tensor) - 支持float32数据类型,shape为(n, c, d)。
- seq_len (Tensor) - 支持Int32数据类型,shape为(n, ), 表示每批次标准化数据量 。
- normalize_type (Int,默认值为0) - 支持 "per_feature"或"all_features"。值为0表示 "per_feature",值为1表示"all_features"。
- 约束条件:
- 示例:
>>> a=np.random.uniform(1,10,(2,3,6)).astype(np.float32) >>> b=np.random.uniform(3,6,(2)).astype(np.int32) >>> x=torch.from_numpy(a).to("npu") >>> seqlen=torch.from_numpy(b).to("npu") >>> out = torch_npu.npu_normalize_batch(x, seqlen, 0) >>> out tensor([[[ 1.1496, -0.6685, -0.4812, 1.7611, -0.5187, 0.7571], [ 1.1445, -0.4393, -0.7051, 1.0474, -0.2646, -0.1582], [ 0.1477, 0.9179, -1.0656, -6.8692, -6.7437, 2.8621]], [[-0.6880, 0.1337, 1.3623, -0.8081, -1.2291, -0.9410], [ 0.3070, 0.5489, -1.4858, 0.6300, 0.6428, 0.0433], [-0.5387, 0.8204, -1.1401, 0.8584, -0.3686, 0.8444]]], device='npu:0')
torch_npu.npu_masked_fill_range(self, start, end, value, axis=-1) -> Tensor
同轴上被range.boxes屏蔽(masked)的填充张量。自定义屏蔽填充范围算子。
- 参数解释:
- self (Tensor) - shape为1D (D,)、2D (N,D)或3D (N,D)的float32/float16/int32/int8 ND张量。
- start (Tensor) - 屏蔽填充开始位置。shape为(num,N)的int32 3D张量。
- end (Tensor) - 屏蔽填充结束位置。shape为(num,N)的int32 3D张量。
- value (Tensor) - 屏蔽填充值。shape为(num,)的float32/float16/int32/int8 2D张量。
- axis (Int,默认值为-1) - 带有int32屏蔽填充的轴。
- 约束条件:
- 示例:
>>> a=torch.rand(4,4).npu() >>> a tensor([[0.9419, 0.4919, 0.2874, 0.6560], [0.6691, 0.6668, 0.0330, 0.1006], [0.3888, 0.7011, 0.7141, 0.7878], [0.0366, 0.9738, 0.4689, 0.0979]], device='npu:0') >>> start = torch.tensor([[0,1,2]], dtype=torch.int32).npu() >>> end = torch.tensor([[1,2,3]], dtype=torch.int32).npu() >>> value = torch.tensor([1], dtype=torch.float).npu() >>> out = torch_npu.npu_masked_fill_range(a, start, end, value, 1) >>> out tensor([[1.0000, 0.4919, 0.2874, 0.6560], [0.6691, 1.0000, 0.0330, 0.1006], [0.3888, 0.7011, 1.0000, 0.7878], [0.0366, 0.9738, 0.4689, 0.0979]], device='npu:0')
torch_npu.npu_linear(input, weight, bias=None) -> Tensor
将矩阵“a”乘以矩阵“b”,生成“a*b”。
- 参数解释:
- input (Tensor) - 2D矩阵张量。数据类型:float32、float16、int32、int8。格式:[ND, NHWC, FRACTAL_NZ]。
- weight (Tensor) - 2D矩阵张量。数据类型:float32、float16、int32、int8。格式:[ND, NHWC, FRACTAL_NZ]。
- bias (Tensor,可选,默认值为None) - 1D张量。数据类型:float32、float16、int32。格式:[ND, NHWC]。
- 约束条件:
- 示例:
>>> x=torch.rand(2,16).npu() >>> w=torch.rand(4,16).npu() >>> b=torch.rand(4).npu() >>> output = torch_npu.npu_linear(x, w, b) >>> output tensor([[3.6335, 4.3713, 2.4440, 2.0081], [5.3273, 6.3089, 3.9601, 3.2410]], device='npu:0')
torch_npu.npu_bert_apply_adam(lr, beta1, beta2, epsilon, grad, max_grad_norm, global_grad_norm, weight_decay, step_size=None, adam_mode=0, *, out=(var,m,v))
adam结果计数。
- 参数解释:
- var (Tensor) - float16或float32类型张量。
- m (Tensor) - 数据类型和shape与exp_avg相同。
- v (Tensor) - 数据类型和shape与exp_avg相同。
- lr (Scalar) - 数据类型与exp_avg相同。
- beta1 (Scalar) - 数据类型与exp_avg相同。
- beta2 (Scalar) - 数据类型与exp_avg相同。
- epsilon (Scalar) - 数据类型与exp_avg相同。
- grad (Tensor) - 数据类型和shape与exp_avg相同。
- max_grad_norm (Scalar) - 数据类型与exp_avg相同。
- global_grad_norm (Scalar) - 数据类型与exp_avg相同。
- weight_decay (Scalar) - 数据类型与exp_avg相同。
- step_size (Tensor,可选,默认值为None) - shape为(1, ),数据类型与exp_avg一致。
- adam_mode (Int,默认值为0) - 选择adam模式。0表示“adam”,1表示“mbert_adam”。
- 关键字参数:
- out (Tensor,可选) - 输出张量。
- 约束条件:
- 示例:
>>> var_in = torch.rand(321538).uniform_(-32., 21.).npu() >>> m_in = torch.zeros(321538).npu() >>> v_in = torch.zeros(321538).npu() >>> grad = torch.rand(321538).uniform_(-0.05, 0.03).npu() >>> max_grad_norm = -1. >>> beta1 = 0.9 >>> beta2 = 0.99 >>> weight_decay = 0. >>> lr = 0. >>> epsilon = 1e-06 >>> global_grad_norm = 0. >>> var_out, m_out, v_out = torch_npu.npu_bert_apply_adam(lr, beta1, beta2, epsilon, grad, max_grad_norm, global_grad_norm, weight_decay, out=(var_in, m_in, v_in)) >>> var_out tensor([ 14.7733, -30.1218, -1.3647, ..., -16.6840, 7.1518, 8.4872], device='npu:0')
torch_npu.npu_giou(self, gtboxes, trans=False, is_cross=False, mode=0) -> Tensor
首先计算两个框的最小封闭面积和IoU,然后计算封闭区域中不属于两个框的封闭面积的比例,最后从IoU中减去这个比例,得到GIoU。
- 参数解释:
- self (Tensor) - 标注框,shape为(N, 4) 数据类型为float16或float32的2D张量。“N”表示标注框的数量,值“4”表示[x1, y1, x2, y2]或[x, y, w, h]。
- gtboxes (Tensor) - 真值框,shape为(M, 4) 数据类型为float16或float32的2D张量。“M”表示真值框的数量,值“4”表示[x1, y1, x2, y2]或[x, y, w, h]。
- trans (Bool,默认值为False) - 值为True代表“xywh”,值为False代表“xyxy”。
- is_cross (Bool,默认值为False) - 控制输出shape是[M, N]还是[1,N]。如果值为True,则输出shape为[M,N]。如果为False,则输出shape为[1,N]。
- mode (Int,默认值为0) - 计算模式,取值为0或1。0表示IoU,1表示IoF。
- 约束条件:
- 示例:
>>> a=np.random.uniform(0,1,(4,10)).astype(np.float16) >>> b=np.random.uniform(0,1,(4,10)).astype(np.float16) >>> box1=torch.from_numpy(a).to("npu") >>> box2=torch.from_numpy(a).to("npu") >>> output = torch_npu.npu_giou(box1, box2, trans=True, is_cross=False, mode=0) >>> output tensor([[1.], [1.], [1.], [1.], [1.], [1.], [1.], [1.], [1.], [1.]], device='npu:0', dtype=torch.float16)
torch_npu.npu_silu(self) -> Tensor
计算self的Swish。
- 参数解释:
- self (Tensor) - 数据类型:float16、float32
- 约束条件:
- 示例:
>>> a=torch.rand(2,8).npu() >>> output = torch_npu.npu_silu(a) >>> output tensor([[0.4397, 0.7178, 0.5190, 0.2654, 0.2230, 0.2674, 0.6051, 0.3522], [0.4679, 0.1764, 0.6650, 0.3175, 0.0530, 0.4787, 0.5621, 0.4026]], device='npu:0')
torch_npu.npu_reshape(self, shape, bool can_refresh=False) -> Tensor
reshape张量。仅更改张量shape,其数据不变。
- 参数解释:
- self (Tensor) - 输入张量。
- shape (ListInt) - 定义输出张量的shape。
- can_refresh (Bool,默认值为False) - 是否就地刷新reshape。
- 约束条件:
- 示例:
>>> a=torch.rand(2,8).npu() >>> out=torch_npu.npu_reshape(a,(4,4)) >>> out tensor([[0.6657, 0.9857, 0.7614, 0.4368], [0.3761, 0.4397, 0.8609, 0.5544], [0.7002, 0.3063, 0.9279, 0.5085], [0.1009, 0.7133, 0.8118, 0.6193]], device='npu:0')
torch_npu.npu_rotated_overlaps(self, query_boxes, trans=False) -> Tensor
计算旋转框的重叠面积。
- 参数解释:
- self (Tensor) -梯度增量数据,shape为(B, 5, N)数据类型为float32的3D张量。
- query_boxes (Tensor) - 标注框,shape为(B, 5, K) 数据类型为float32的3D张量。
- trans (Bool,默认值为False) - 值为True表示“xyxyt”,值为False表示“xywht”。
- 约束条件:
- 示例:
>>> a=np.random.uniform(0,1,(1,3,5)).astype(np.float16) >>> b=np.random.uniform(0,1,(1,2,5)).astype(np.float16) >>> box1=torch.from_numpy(a).to("npu") >>> box2=torch.from_numpy(a).to("npu") >>> output = torch_npu.npu_rotated_overlaps(box1, box2, trans=False) >>> output tensor([[[0.0000, 0.1562, 0.0000], [0.1562, 0.3713, 0.0611], [0.0000, 0.0611, 0.0000]]], device='npu:0', dtype=torch.float16)
torch_npu.npu_rotated_iou(self, query_boxes, trans=False, mode=0, is_cross=True,v_threshold=0.0, e_threshold=0.0) -> Tensor
计算旋转框的IoU。
- 参数解释:
- self (Tensor) - 梯度增量数据,shape为(B, 5, N)数据类型为float32的3D张量。
- query_boxes (Tensor) - 标注框,shape为(B, 5, K) 数据类型为float32的3D张量。
- trans (Bool,默认值为False) - 值为True表示“xyxyt”,值为False表示“xywht”。
- is_cross (Bool,默认值为True) - 值为True时表示交叉计算,为False时表示一对一计算。
- mode (Int,默认值为0) - 计算模式,取值为0或1。0表示IoU,1表示IoF。
- v_threshold (Float,可选,默认值为0.0) - provide condition relaxation for intersection calculation.
- e_threshold (Float,可选,默认值为0.0) - provide condition relaxation for intersection calculation.
- 约束条件:
- 示例:
>>> a=np.random.uniform(0,1,(2,2,5)).astype(np.float16) >>> b=np.random.uniform(0,1,(2,3,5)).astype(np.float16) >>> box1=torch.from_numpy(a).to("npu") >>> box2=torch.from_numpy(a).to("npu") >>> output = torch_npu.npu_rotated_iou(box1, box2, trans=False, mode=0, is_cross=True) >>> output tensor([[[3.3325e-01, 1.0162e-01], [1.0162e-01, 1.0000e+00]], [[0.0000e+00, 0.0000e+00], [0.0000e+00, 5.9605e-08]]], device='npu:0', dtype=torch.float16)
torch_npu.npu_rotated_box_encode(anchor_box, gt_bboxes, weight) -> Tensor
旋转标注框编码。
- 参数解释:
- anchor_box (Tensor) - shape为(B,5,N)的3D输入张量,表示锚点框。“B”表示批处理大小数量,“N”表示标注框数量,值“5”表示“x0”、“x1”、“y0”、“y1”和“angle”。
- gt_bboxes (Tensor) - shape为(B,5,N)数据类型为float32 (float16)的3D张量。
- weight (Tensor,默认值为[1.0, 1.0, 1.0, 1.0, 1.0]) - “x0”、“x1”、“y0”、“y1”和“angle”的浮点列表。
- 约束条件:
- 示例:
>>> anchor_boxes = torch.tensor([[[30.69], [32.6], [45.94], [59.88], [-44.53]]], dtype=torch.float16).to("npu") >>> gt_bboxes = torch.tensor([[[30.44], [18.72], [33.22], [45.56], [8.5]]], dtype=torch.float16).to("npu") >>> weight = torch.tensor([1., 1., 1., 1., 1.], dtype=torch.float16).npu() >>> out = torch_npu.npu_rotated_box_encode(anchor_boxes, gt_bboxes, weight) >>> out tensor([[[-0.4253], [-0.5166], [-1.7021], [-0.0162], [ 1.1328]]], device='npu:0', dtype=torch.float16)
torch_npu.npu_rotated_box_decode(anchor_boxes, deltas, weight) -> Tensor
旋转标注框编码。
- 参数解释:
- anchor_box (Tensor) - shape为(B,5,N)的3D输入张量,表示锚点框。“B”表示批处理大小数量,“N”表示标注框数量,值“5”表示“x0”、“x1”、“y0”、“y1”和“angle”。
- deltas (Tensor) - shape为(B,5,N)数据类型为float32 (float16)的3D张量。
- weight (Tensor,默认值为[1.0, 1.0, 1.0, 1.0, 1.0]) - “x0”、“x1”、“y0”、“y1”和“angle”的浮点列表。
- 约束条件:
- 示例:
>>> anchor_boxes = torch.tensor([[[4.137],[33.72],[29.4], [54.06], [41.28]]], dtype=torch.float16).to("npu") >>> deltas = torch.tensor([[[0.0244], [-1.992], [0.2109], [0.315], [-37.25]]], dtype=torch.float16).to("npu") >>> weight = torch.tensor([1., 1., 1., 1., 1.], dtype=torch.float16).npu() >>> out = torch_npu.npu_rotated_box_decode(anchor_boxes, deltas, weight) >>> out tensor([[[ 1.7861], [-10.5781], [ 33.0000], [ 17.2969], [-88.4375]]], device='npu:0', dtype=torch.float16)
torch_npu.npu_ciou(Tensor self, Tensor gtboxes, bool trans=False, bool is_cross=True, int mode=0, bool atan_sub_flag=False) -> Tensor
应用基于NPU的CIoU操作。在DIoU的基础上增加了penalty item,并propose CIoU。
- 注释:
到目前为止,CIoU向后只支持当前版本中的trans==True、is_cross==False、mode==0('iou')。如果需要反向传播,确保参数正确。
- 参数:
- boxes1 (Tensor):格式为xywh、shape为(4, n)的预测检测框。
- boxes2 (Tensor):相应的gt检测框,shape为(4, n)。
- trans (Bool,默认值为False):是否有偏移。
- is_cross (Bool,默认值为True):box1和box2之间是否有交叉操作。
- mode (Int,默认值为0):选择CIoU的计算方式。0表示IoU,1表示IoF。
- atan_sub_flag (Bool,默认值为False):是否将正向的第二个值传递给反向。
- 返回值:
- 示例:
>>> box1 = torch.randn(4, 32).npu() >>> box1.requires_grad = True >>> box2 = torch.randn(4, 32).npu() >>> box2.requires_grad = True >>> ciou = torch_npu.contrib.function.npu_ciou(box1, box2) >>> l = ciou.sum() >>> l.backward()
torch_npu.npu_diou(Tensor self, Tensor gtboxes, bool trans=False, bool is_cross=False, int mode=0) -> Tensor
应用基于NPU的DIoU操作。考虑到目标之间距离,以及距离和范围的重叠率,不同目标或边界需趋于稳定。
- 注释:
到目前为止,DIoU向后只支持当前版本中的trans==True、is_cross==False、mode==0('iou')。如果需要反向传播,确保参数正确。
- 参数:
- boxes1 (Tensor) - 格式为xywh、shape为(4, n)的预测检测框。
- boxes2 (Tensor) - 相应的gt检测框,shape为(4, n)。
- trans (Bool,默认值为False) - 是否有偏移。
- is_cross (Bool,默认值为False) - box1和box2之间是否有交叉操作。
- mode (Int,默认值为0) - 选择DIoU的计算方式。0表示IoU,1表示IoF。
- 返回值:
- 示例:
>>> box1 = torch.randn(4, 32).npu() >>> box1.requires_grad = True >>> box2 = torch.randn(4, 32).npu() >>> box2.requires_grad = True >>> diou = torch_npu.contrib.function.npu_diou(box1, box2) >>> l = diou.sum() >>> l.backward()
torch_npu.npu_sign_bits_pack(Tensor self, int size) -> Tensor
将float类型1位Adam打包为uint8。
- 参数:
- x(Tensor) - 1D float张量。
- size(Int) - reshape时输出张量的第一个维度。
- 约束条件:
Size可被float打包的输出整除。如果x的size可被8整除,则输出的size为(size of x)/8;否则,输出的size为(size of x // 8) + 1。将在小端位置添加-1浮点值以填充可整除性。Atlas 训练系列产品支持float32和float16类型输入。Atlas 推理系列产品(Ascend 310P处理器)支持float32和float16类型输入。Atlas 200/300/500 推理产品仅支持float16类型输入。
- 示例:
>>>a = torch.tensor([5,4,3,2,0,-1,-2, 4,3,2,1,0,-1,-2],dtype=torch.float32).npu() >>>b = torch_npu.sign_bits_pack(a, 2) >>>b >>>tensor([[159],[15]], device='npu:0') >>>(binary form of 159 is ob10011111, corresponds to 4, -2, -1, 0, 2, 3, 4, 5 respectively)
torch_npu.npu_sign_bits_unpack(x, dtype, size) -> Tensor
将uint8类型1位Adam拆包为float。
- 参数:
- x(Tensor) - 1D uint8张量。
- dtype(torch.dtype) - 值为1设置输出类型为float16,值为0设置输出类型为float32。
- size(Int) - reshape时输出张量的第一个维度。
- 约束条件:
- 示例:
>>>a = torch.tensor([159, 15], dtype=torch.uint8).npu() >>>b = torch_npu.npu_sign_bits_unpack(a, 0, 2) >>>b >>>tensor([[1., 1., 1., 1., 1., -1., -1., 1.], >>>[1., 1., 1., 1., -1., -1., -1., -1.]], device='npu:0') (binary form of 159 is ob00001111)
torch_npu.npu_rotary_mul(Tensor x, Tensor r1, Tensor r2): -> Tensor
x1, x2 = torch.chunk(x, 2, -1) x_new = torch.cat((-x2, x1), dim=-1) output = r1 * x + r2 * x_new
- 参数:
- Tensor x:4维张量,shape为(B, N, S, D)。
- Tensor r1:4维张量cos角度,shape为(X, X, X, D),支持除最后一轴外任意轴广播。
- Tensor r2:4维张量sin角度,shape为(X, X, X, D), 支持除最后一轴外任意轴广播。
- 约束条件:
- 示例:
>>>x = torch.rand(2, 2, 5, 128).npu() >>>tensor([[[[0.8594, 0.4914, 0.9075, ..., 0.2126, 0.6520, 0.2206], [0.5515, 0.3353, 0.6568, ..., 0.3686, 0.1457, 0.8528], [0.0504, 0.2687, 0.4036, ..., 0.3032, 0.8262, 0.6302], [0.0537, 0.5141, 0.7016, ..., 0.4948, 0.9778, 0.8535], [0.3602, 0.7874, 0.9913, ..., 0.1474, 0.3422, 0.6830]], [[0.4641, 0.6254, 0.7415, ..., 0.1834, 0.1067, 0.7171], [0.8084, 0.7570, 0.4728, ..., 0.4603, 0.4991, 0.1723], [0.0483, 0.6931, 0.0935, ..., 0.7522, 0.0054, 0.1736], [0.6196, 0.1028, 0.7076, ..., 0.2745, 0.9943, 0.6971], [0.3267, 0.3748, 0.1232, ..., 0.0507, 0.4302, 0.6249]]], [[[0.2783, 0.8262, 0.6014, ..., 0.8040, 0.7986, 0.2831], [0.6035, 0.2955, 0.7711, ..., 0.7464, 0.3739, 0.6637], [0.6282, 0.7243, 0.5445, ..., 0.3755, 0.0533, 0.9468], [0.5179, 0.3967, 0.6558, ..., 0.0267, 0.5549, 0.9707], [0.4388, 0.7458, 0.2065, ..., 0.6080, 0.4242, 0.8879]], [[0.3428, 0.6976, 0.0970, ..., 0.9552, 0.3663, 0.2139], [0.2019, 0.2452, 0.1142, ..., 0.3651, 0.6993, 0.5257], [0.9636, 0.1691, 0.4807, ..., 0.9137, 0.3510, 0.0905], [0.0177, 0.9496, 0.1560, ..., 0.7437, 0.9043, 0.0131], [0.9699, 0.5352, 0.9763, ..., 0.1850, 0.2056, 0.0368]]]], device='npu:0') >>>r1 = torch.rand(1, 2, 1, 128).npu() tensor([[[[0.8433, 0.5262, 0.2608, 0.8501, 0.7187, 0.6944, 0.0193, 0.1507, 0.0450, 0.2257, 0.4679, 0.8309, 0.4740, 0.8715, 0.7443, 0.3354, 0.5533, 0.9151, 0.4215, 0.4631, 0.9076, 0.3093, 0.0270, 0.7681, 0.1800, 0.0847, 0.6965, 0.2059, 0.8806, 0.3987, 0.8446, 0.6225, 0.1375, 0.8765, 0.5965, 0.3092, 0.0193, 0.9220, 0.4997, 0.8170, 0.8575, 0.5525, 0.8528, 0.7262, 0.4026, 0.5704, 0.0390, 0.9240, 0.9780, 0.3927, 0.7343, 0.3922, 0.5004, 0.8561, 0.6021, 0.6530, 0.6565, 0.9988, 0.4238, 0.0092, 0.5131, 0.5257, 0.1649, 0.0272, 0.9103, 0.2476, 0.7573, 0.8500, 0.9348, 0.4306, 0.3612, 0.5378, 0.7141, 0.3559, 0.6620, 0.3335, 0.4000, 0.2479, 0.3490, 0.7000, 0.5321, 0.3485, 0.9162, 0.9207, 0.3262, 0.7929, 0.1258, 0.6689, 0.1023, 0.1938, 0.3887, 0.6893, 0.0849, 0.3700, 0.5747, 0.9674, 0.4520, 0.5313, 0.0377, 0.1202, 0.9326, 0.0442, 0.4651, 0.7036, 0.3994, 0.9332, 0.5104, 0.0930, 0.4481, 0.8753, 0.5597, 0.6068, 0.9895, 0.5833, 0.6771, 0.4255, 0.4513, 0.6330, 0.9070, 0.3103, 0.0609, 0.8202, 0.6031, 0.3628, 0.1118, 0.2747, 0.4521, 0.8347]], [[0.6759, 0.8744, 0.3595, 0.2361, 0.4899, 0.3769, 0.6809, 0.0101, 0.0730, 0.0576, 0.5242, 0.5510, 0.9780, 0.4704, 0.9607, 0.1699, 0.3613, 0.6096, 0.0246, 0.6088, 0.4984, 0.9788, 0.2026, 0.1484, 0.3086, 0.9697, 0.8166, 0.9566, 0.9874, 0.4547, 0.5250, 0.2041, 0.7784, 0.4269, 0.0110, 0.6878, 0.6575, 0.3382, 0.1889, 0.8344, 0.9608, 0.6153, 0.4812, 0.0547, 0.2978, 0.3610, 0.5285, 0.6162, 0.2123, 0.1364, 0.6027, 0.7450, 0.2485, 0.2149, 0.7849, 0.8886, 0.0514, 0.9511, 0.4865, 0.8380, 0.6947, 0.2378, 0.5839, 0.8434, 0.0871, 0.4179, 0.1669, 0.8703, 0.1946, 0.0302, 0.9516, 0.1208, 0.5780, 0.6859, 0.2405, 0.5083, 0.3872, 0.7649, 0.1329, 0.0252, 0.2404, 0.5456, 0.7009, 0.6524, 0.7623, 0.5965, 0.0437, 0.4080, 0.8390, 0.4172, 0.4781, 0.2405, 0.1502, 0.2020, 0.4192, 0.8185, 0.0899, 0.1961, 0.7368, 0.4798, 0.4303, 0.9281, 0.5410, 0.0620, 0.8945, 0.3589, 0.5637, 0.4875, 0.1523, 0.9478, 0.9040, 0.3410, 0.3591, 0.2702, 0.5949, 0.3337, 0.3578, 0.8890, 0.6608, 0.6578, 0.4953, 0.7975, 0.2891, 0.9552, 0.0092, 0.1293, 0.2362, 0.7821]]]], device='npu:0') >>>r2 = torch.rand(1, 2, 1, 128).npu() tensor([[[[6.4270e-01, 1.3050e-01, 9.6509e-01, 1.4090e-01, 1.8660e-01, 8.7512e-01, 3.8567e-01, 4.1776e-01, 9.7718e-01, 5.6305e-01, 6.3091e-01, 4.6385e-01, 1.8142e-01, 3.7779e-01, 3.8012e-01, 8.1807e-01, 3.3292e-01, 5.8488e-01, 5.8188e-01, 5.7776e-01, 5.1828e-01, 9.6087e-01, 7.2219e-01, 8.5045e-02, 3.6623e-01, 3.3758e-01, 7.9666e-01, 6.9932e-01, 9.9202e-01, 2.5493e-01, 2.3017e-01, 7.9396e-01, 5.0109e-01, 6.5580e-01, 3.2200e-01, 7.8023e-01, 4.4098e-01, 1.0576e-01, 8.0548e-01, 2.2453e-01, 1.4705e-01, 8.7682e-02, 4.7264e-01, 8.9034e-02, 8.5720e-01, 4.7576e-01, 2.8438e-01, 8.6523e-01, 8.1707e-02, 3.0075e-01, 4.9069e-01, 9.7404e-01, 9.3865e-01, 5.7160e-01, 1.6332e-01, 4.3868e-01, 5.8658e-01, 5.3993e-01, 3.8271e-02, 9.9662e-01, 2.2892e-01, 7.8558e-01, 9.4502e-01, 9.7633e-01, 1.7877e-01, 2.6446e-02, 2.3411e-01, 6.7531e-01, 1.5023e-01, 4.4280e-02, 1.4457e-01, 3.6683e-01, 4.3424e-01, 7.4145e-01, 8.2433e-01, 6.8660e-01, 6.7477e-01, 5.5000e-02, 5.1344e-01, 9.3115e-01, 3.8280e-01, 9.2177e-01, 4.5470e-01, 2.5540e-01, 4.6632e-01, 8.3960e-01, 4.4320e-01, 1.0808e-01, 7.5544e-01, 4.6372e-01, 1.4322e-01, 1.9141e-01, 5.5918e-02, 7.0804e-01, 1.8789e-01, 9.4276e-01, 9.1742e-01, 9.1980e-01, 6.2728e-01, 4.1787e-01, 7.9545e-01, 9.0569e-01, 7.9123e-01, 9.7596e-01, 7.2507e-01, 2.3772e-01, 8.2560e-01, 5.9359e-01, 7.1134e-01, 5.1029e-01, 6.1601e-01, 2.9094e-01, 3.4174e-01, 9.0532e-01, 5.0960e-01, 3.4441e-01, 7.0498e-01, 4.2729e-01, 7.6714e-01, 6.3755e-01, 8.4604e-01, 5.9109e-01, 7.9137e-01, 7.5149e-01, 2.2092e-01, 9.5235e-01, 3.6915e-01, 6.4961e-01]], [[8.7862e-01, 1.1325e-01, 2.4575e-01, 9.7429e-01, 1.9362e-01, 8.2297e-01, 3.5184e-02, 5.2755e-01, 7.6429e-01, 2.4700e-01, 6.2860e-01, 2.4555e-01, 4.4557e-01, 7.0955e-03, 2.0326e-01, 8.6354e-02, 3.5959e-01, 3.4059e-01, 8.6852e-01, 1.3858e-01, 6.8500e-01, 1.3601e-01, 7.3152e-01, 8.3474e-01, 2.7017e-01, 9.8078e-01, 6.1084e-01, 1.6540e-01, 4.3081e-01, 8.5738e-01, 4.1890e-01, 6.6872e-01, 3.1698e-01, 4.2576e-02, 1.5236e-01, 2.0526e-01, 1.9493e-01, 6.6122e-03, 1.8332e-01, 5.6981e-01, 5.4090e-01, 6.0783e-01, 5.8742e-01, 9.1761e-04, 2.0904e-01, 6.6419e-01, 9.9559e-01, 5.8233e-01, 6.8562e-01, 8.6456e-01, 9.9931e-01, 3.5637e-01, 2.4642e-01, 2.3428e-02, 6.9037e-01, 1.7560e-01, 1.8703e-01, 3.5244e-01, 6.3031e-01, 1.8450e-01, 9.2194e-01, 9.3016e-02, 9.0488e-01, 2.4294e-02, 5.1122e-01, 5.0793e-01, 7.9585e-01, 7.9594e-02, 5.2137e-01, 9.8359e-01, 7.5022e-01, 4.1925e-01, 3.3284e-01, 4.7939e-01, 9.9081e-01, 3.3931e-01, 2.6461e-01, 5.3063e-01, 1.0328e-01, 8.0720e-01, 9.9480e-01, 3.0833e-01, 5.6780e-01, 3.9551e-01, 6.7176e-01, 4.8049e-01, 1.5653e-01, 1.7595e-02, 6.6493e-02, 5.1989e-01, 8.2691e-01, 7.3295e-01, 5.7169e-01, 4.9911e-01, 1.0260e-01, 5.2307e-01, 7.4247e-01, 1.1682e-01, 5.8123e-01, 7.3496e-02, 6.4274e-02, 2.4704e-01, 6.0424e-02, 2.6161e-01, 7.7966e-01, 7.1244e-01, 2.2077e-01, 5.0723e-01, 9.6665e-01, 6.0933e-01, 8.1332e-01, 3.0749e-01, 2.1297e-02, 3.6734e-01, 9.2542e-01, 1.3554e-01, 9.7240e-01, 4.4344e-01, 4.2534e-01, 4.6205e-01, 6.1811e-01, 5.8800e-01, 5.4673e-01, 1.2535e-01, 2.9959e-01, 4.4890e-01, 2.7185e-01, 5.0243e-01]]]], device='npu:0') >>>out = torch_npu.npu_rotary_mul(x, r1, r2) tensor([[[[ 0.1142, 0.1891, -0.4689, ..., 0.5704, 0.5375, 0.6079], [ 0.2264, 0.1155, -0.7678, ..., 0.9857, 0.3382, 0.9441], [-0.1902, 0.1329, -0.3613, ..., 0.9793, 0.5628, 0.8669], [-0.3349, 0.1532, 0.1124, ..., 0.3125, 0.6741, 1.1248], [-0.0473, 0.2978, -0.6940, ..., 0.2753, 0.2604, 1.0379]], [[ 0.0136, 0.4723, 0.1371, ..., 0.1081, 0.2462, 0.6316], [ 0.0769, 0.6558, -0.0734, ..., 0.2714, 0.2221, 0.2195], [-0.3755, 0.5364, -0.1131, ..., 0.3105, 0.1225, 0.6166], [ 0.3535, 0.0164, 0.0095, ..., 0.1361, 0.2570, 0.5811], [-0.2992, 0.2981, 0.0242, ..., 0.2881, 0.2367, 0.9582]]], [[[ 0.1699, 0.3589, -0.7443, ..., 0.4751, 0.7291, 0.2717], [ 0.3657, 0.0397, 0.1818, ..., 0.9113, 0.4130, 0.8279], [-0.0657, 0.2528, -0.6658, ..., 0.8184, 0.2057, 1.2864], [-0.1058, 0.1859, -0.0998, ..., 0.0662, 0.5590, 1.0525], [ 0.2651, 0.3719, -0.8170, ..., 0.2789, 0.3916, 1.0407]], [[-0.5998, 0.5740, -0.0154, ..., 0.1746, 0.1982, 0.6338], [ 0.0766, 0.1790, -0.1490, ..., 0.4387, 0.2592, 0.4924], [ 0.4765, 0.0485, -0.0226, ..., 0.2219, 0.3445, 0.2265], [-0.1006, 0.8073, -0.1540, ..., 0.1045, 0.2633, 0.2194], [ 0.0157, 0.3997, 0.3131, ..., 0.0538, 0.0647, 0.4821]]]], device='npu:0')
torch_npu.npu_fused_attention_score(Tensor query_layer, Tensor key_layer, Tensor value_layer, Tensor attention_mask, Scalar scale, float keep_prob, bool query_transpose=False, bool key_transpose=False, bool bmm_score_transpose_a=False, bool bmm_score_transpose_b=False, bool value_transpose=False, bool dx_transpose=False) -> Tensor
- 参数:
- query_layer:Tensor类型,仅支持float16。
- key_layer:Tensor类型,仅支持float16。
- value_layer:Tensor类型,仅支持float16 。
- attention_mask:Tensor类型,仅支持float16 。
- scale:缩放系数,浮点数标量 。
- keep_prob:不做dropout的概率,0-1之间,浮点数。
- query_transpose:query是否做转置,bool类型,默认为False 。
- key_transpose:key是否做转置,bool类型,默认为False 。
- bmm_score_transpose_a:bmm计算中左矩阵是否做转置,bool类型,默认为False。
- bmm_score_transpose_b:bmm计算中右矩阵是否做转置,bool类型,默认为False。
- value_transpose:value是否做转置,bool类型,默认为False。
- dx_transpose:反向计算时dx是否做转置,bool类型,默认为False。
- 约束条件:
- 示例:
>>> import torch >>> import torch_npu >>> query_layer = torch_npu.npu_format_cast(torch.rand(24, 16, 512, 64).npu() , 29).half() >>> query_layer = torch_npu.npu_format_cast(torch.rand(24, 16, 512, 64).npu(), 29).half() >>> key_layer = torch_npu.npu_format_cast(torch.rand(24, 16, 512, 64).npu(), 29).half() >>> value_layer = torch_npu.npu_format_cast(torch.rand(24, 16, 512, 64).npu(), 29).half() >>> attention_mask = torch_npu.npu_format_cast(torch.rand(24, 16, 512, 512).npu(), 29).half() >>> scale = 0.125 >>> keep_prob = 0.5 >>> context_layer = torch_npu.npu_fused_attention_score(query_layer, key_layer, value_layer, attention_mask, scale, keep_prob) >>> print(context_layer) tensor([[0.5063, 0.4900, 0.4951, ..., 0.5493, 0.5249, 0.5400], [0.4844, 0.4724, 0.4927, ..., 0.5176, 0.4702, 0.4790], [0.4683, 0.4771, 0.5054, ..., 0.4917, 0.4614, 0.4739], ..., [0.5137, 0.5010, 0.5078, ..., 0.4656, 0.4592, 0.5034], [0.5425, 0.5732, 0.5347, ..., 0.5054, 0.5024, 0.4924],
torch_npu.npu_scaled_masked_softmax(x, mask, scale=1.0, fixed_triu_mask=False) -> Tensor
计算输入张量x缩放并按照mask遮蔽后的Softmax结果。
- 参数解释:
- x(Tensor)- 输入的logits。支持数据类型:float16、float32、bfloat16。支持格式:[ND,FRACTAL_NZ]。
- mask(Tensor)- 输入的掩码。支持数据类型:bool。支持格式:[ND,FRACTAL_NZ]。
- scale(float,默认值为1.0)- x的缩放系数。
- fixed_triu_mask(bool,默认值为False)- 是否使用自动生成的上三角bool掩码。
- 约束条件:
- 当前输入x的shape,只支持转为[NCHW]格式后,H和W轴长度大于等于32、小于等于4096、且能被32整除的场景。
- 输入mask的shape,必须能被broadcast成x的shape。
- 示例:
>>> import torch >>> import torch_npu >>> >>> x = torch.rand(4, 4, 2048, 2048).npu() >>> mask = torch.rand(1, 1, 2048, 2048).npu() >>> out = torch_npu.npu_scaled_masked_softmax(x, mask, 1.0, False) >>> out.shape torch.size([4, 4, 2048, 2048])
torch_npu.npu_dropout_with_add_softmax(Tensor self, Tensor x1, Scalar alpha, float prob, int dim) -> (Tensor, Tensor, Tensor)
实现axpy_v2、softmax_v2、drop_out_domask_v3功能。即:
y=x1+ self *alpha
Softmax(xi)= exp(xi)/∑jexp(xj)
output = 根据mask舍弃x中的元素,留下来的元素乘(1/prob)
- 参数解释:
- Tensor self:4维张量,shape为(N, C, H, W)。
- Tensor x1:4维张量,shape为(N, C, H, W)。
- 约束条件:
- self和x1的shape相同;
- H和W是[128, 256, 384, 512]其中之一;
- (N * C)%32结果为0;
- dim为-1。
- 示例:
self = torch.rand(16, 16, 128, 128).npu() tensor([[[[7.2556e-02, 3.0909e-01, 7.9734e-01, ..., 6.1179e-01, 6.2624e-03, 8.5186e-01], [8.9196e-02, 3.3319e-01, 4.0780e-01, ..., 1.9144e-01, 2.2701e-01, 6.4018e-01], [4.7275e-01, 7.4895e-01, 4.6215e-01, ..., 9.3753e-01, 6.6048e-02, 8.1877e-02], ..., [7.9366e-01, 5.1516e-01, 5.6594e-01, ..., 1.6457e-01, 1.0640e-01, 3.4322e-03], [1.5743e-02, 1.2893e-01, 5.8990e-01, ..., 4.1721e-01, 8.7816e-02, 6.8886e-01], [4.2980e-01, 5.5447e-01, 3.1894e-01, ..., 9.2638e-01, 9.9324e-01, 4.6225e-01]], [[6.2426e-01, 4.5948e-01, 1.0837e-01, ..., 8.9386e-01, 3.6932e-01, 1.2406e-01], [9.1823e-01, 6.2311e-01, 5.1474e-01, ..., 2.1042e-01, 6.5943e-01, 3.1797e-01], [5.2891e-01, 2.0183e-01, 2.1452e-01, ..., 9.1638e-01, 6.4109e-01, 9.4484e-01], ..., [3.7783e-02, 1.3218e-01, 3.1192e-01, ..., 2.4931e-01, 4.8809e-01, 9.6085e-01], [3.3197e-01, 9.1186e-02, 2.4839e-01, ..., 2.1156e-03, 6.4952e-01, 8.5996e-01], [1.7941e-01, 5.1532e-01, 7.8133e-01, ..., 3.5526e-01, 5.3576e-01, 6.0538e-01]], [[2.6743e-01, 7.4942e-01, 1.9146e-01, ..., 4.9179e-01, 6.3319e-01, 9.9269e-01], [1.5163e-01, 3.7388e-01, 8.0604e-02, ..., 8.1193e-01, 1.7922e-01, 8.6578e-01], [8.2558e-01, 9.5139e-01, 2.1313e-01, ..., 2.1722e-01, 2.8402e-01, 8.8888e-01], ..., [1.8222e-01, 2.7645e-01, 6.7305e-01, ..., 6.8003e-01, 4.0917e-01, 7.6655e-01], [3.1234e-01, 7.8519e-01, 8.8509e-01, ..., 7.2574e-01, 9.6134e-01, 2.2267e-01], [4.9233e-01, 8.8407e-01, 7.4390e-01, ..., 5.2253e-02, 5.5150e-02, 4.4108e-02]], ..., [[4.3370e-01, 2.1176e-01, 4.7512e-01, ..., 5.7611e-01, 3.2619e-01, 1.1523e-01], [6.1469e-01, 7.4528e-01, 7.9559e-02, ..., 9.7112e-01, 1.8391e-01, 8.9883e-01], [8.6677e-02, 3.5051e-02, 1.6875e-01, ..., 3.9833e-01, 6.7967e-01, 4.7062e-01], ..., [7.1648e-01, 1.8378e-01, 5.3054e-01, ..., 8.4282e-01, 9.1972e-01, 7.0031e-01], [5.9876e-01, 6.7868e-01, 6.4128e-01, ..., 4.9516e-02, 7.2571e-01, 5.8792e-01], [7.6723e-01, 6.9527e-01, 9.3573e-01, ..., 6.3490e-02, 6.6129e-01, 2.4517e-01]], [[5.0158e-01, 8.2565e-01, 7.5532e-01, ..., 6.9342e-01, 3.3244e-01, 5.3913e-01], [2.3347e-01, 9.7822e-02, 1.5009e-01, ..., 5.5090e-01, 9.1813e-01, 7.9857e-01], [7.2416e-02, 5.9086e-01, 1.2243e-01, ..., 7.8511e-01, 2.4803e-01, 5.3717e-01], ..., [7.4899e-01, 1.5467e-02, 4.9711e-01, ..., 2.2938e-02, 1.6099e-01, 3.1928e-01], [3.9111e-01, 1.2422e-01, 6.1795e-02, ..., 8.4212e-01, 6.1346e-01, 1.0957e-01], [3.6311e-02, 8.9652e-01, 7.7428e-01, ..., 9.2212e-01, 4.9290e-01, 4.5609e-01]], [[2.2052e-01, 4.4260e-01, 8.8627e-01, ..., 9.2381e-01, 7.7046e-01, 9.2057e-01], [5.5775e-01, 8.8951e-01, 7.9238e-01, ..., 3.9209e-01, 9.6636e-01, 8.1876e-01], [3.4709e-01, 7.8678e-01, 1.4396e-01, ..., 7.9073e-01, 3.9021e-01, 8.5285e-01], ..., [1.4238e-01, 9.8432e-01, 2.7802e-01, ..., 5.1720e-01, 1.6290e-01, 8.2036e-01], [2.0184e-01, 1.0635e-01, 1.9612e-01, ..., 9.7101e-01, 9.6679e-01, 7.0811e-01], [5.8240e-01, 3.1642e-01, 9.6549e-01, ..., 5.1130e-02, 5.6725e-01, 3.5238e-01]]]], device='npu:0') x1 = torch.rand(16, 16, 128, 128).npu() tensor([[[[2.4353e-01, 8.5665e-01, 5.3571e-01, ..., 5.9101e-01, 4.0872e-01, 6.3873e-01], [1.4489e-01, 8.7982e-01, 3.3114e-01, ..., 2.5155e-01, 8.4987e-01, 8.7096e-01], [6.5837e-02, 2.2677e-02, 7.2063e-01, ..., 2.3542e-01, 9.3041e-01, 8.9596e-01], ..., [5.1450e-01, 7.9412e-01, 8.9288e-01, ..., 3.3639e-01, 5.6086e-01, 4.8770e-02], [4.7557e-01, 1.4793e-01, 4.9800e-01, ..., 3.9479e-01, 5.6052e-01, 9.8271e-01], [7.4438e-01, 7.5646e-01, 2.7942e-02, ..., 3.0381e-01, 4.3703e-01, 1.4037e-02]], [[4.0232e-01, 9.4407e-01, 6.4969e-01, ..., 3.4524e-01, 8.2647e-01, 5.4792e-01], [1.1801e-01, 1.8281e-01, 6.1723e-01, ..., 1.9393e-01, 4.5877e-01, 8.9990e-01], [2.6244e-01, 6.9614e-01, 3.6008e-01, ..., 5.0258e-01, 8.1919e-01, 4.6943e-01], ..., [7.4710e-01, 5.8911e-01, 1.5292e-01, ..., 6.6590e-01, 4.0754e-01, 3.6944e-01], [9.0501e-01, 2.7943e-01, 3.7068e-01, ..., 1.5053e-01, 7.3413e-01, 7.9626e-01], [9.5200e-01, 7.8327e-01, 3.4033e-01, ..., 8.0892e-01, 4.0480e-01, 3.8717e-01]], [[7.5938e-01, 2.9089e-01, 5.9916e-01, ..., 6.2526e-01, 3.9670e-01, 3.3548e-01], [7.0733e-01, 8.1400e-01, 4.9259e-01, ..., 1.6607e-02, 6.5331e-01, 7.3150e-02], [5.2770e-01, 7.8141e-01, 4.1904e-01, ..., 3.8917e-01, 4.1405e-01, 9.9596e-01], ..., [4.8669e-01, 9.9948e-01, 1.2023e-01, ..., 7.0420e-01, 2.8522e-01, 6.6192e-01], [4.9718e-01, 7.5792e-01, 6.6748e-01, ..., 9.7302e-01, 3.3443e-01, 3.6536e-01], [7.7033e-01, 6.0550e-01, 8.2024e-01, ..., 2.9711e-01, 1.9410e-01, 6.6304e-01]], ..., [[1.0284e-01, 6.5712e-01, 6.0831e-01, ..., 6.2622e-01, 2.0355e-01, 9.4250e-01], [4.9053e-01, 2.0148e-01, 2.4974e-01, ..., 9.2521e-01, 1.9919e-01, 4.4700e-01], [7.6515e-01, 8.7755e-01, 1.3500e-01, ..., 8.2136e-01, 2.0848e-01, 5.6432e-01], ..., [3.3618e-01, 1.8585e-01, 5.3475e-01, ..., 4.9333e-01, 9.1018e-01, 9.5052e-01], [2.1400e-01, 1.7407e-01, 5.8925e-01, ..., 7.5722e-01, 2.9850e-01, 3.9298e-01], [6.3625e-01, 1.7168e-01, 2.9183e-01, ..., 9.9674e-01, 2.1718e-01, 5.2626e-01]], [[1.8651e-01, 2.5385e-01, 2.0384e-01, ..., 3.4462e-01, 8.4150e-01, 4.7431e-01], [2.4992e-01, 1.1788e-01, 1.9730e-01, ..., 4.3722e-02, 7.8943e-01, 9.9097e-01], [1.4493e-02, 6.4856e-01, 8.3344e-01, ..., 8.6623e-01, 1.5456e-01, 7.8423e-01], ..., [6.1458e-01, 4.4260e-01, 7.4133e-01, ..., 2.5126e-01, 2.7251e-01, 6.9784e-01], [2.2419e-01, 3.4159e-01, 2.3232e-01, ..., 8.2850e-01, 8.2644e-02, 4.8390e-01], [1.0171e-01, 8.7662e-01, 2.0457e-01, ..., 7.6868e-01, 7.6592e-01, 3.1254e-01]], [[1.8866e-01, 1.5755e-01, 3.1025e-02, ..., 6.5044e-01, 7.8293e-01, 9.8030e-01], [3.7703e-01, 5.3198e-01, 1.8633e-01, ..., 4.7398e-01, 8.3618e-01, 8.7283e-01], [5.7119e-01, 4.3620e-01, 8.2536e-01, ..., 2.5390e-01, 5.6144e-01, 4.4044e-01], ..., [1.3243e-01, 6.2002e-02, 7.5278e-01, ..., 7.5907e-01, 4.2472e-01, 1.7624e-01], [4.7985e-01, 7.9769e-01, 8.1433e-01, ..., 7.3780e-01, 2.2877e-02, 4.8816e-01], [4.5100e-01, 9.9698e-02, 7.0776e-01, ..., 9.8046e-01, 2.2372e-01, 8.6304e-01]]]], device='npu:0') _, _, out = torch_npu.npu_dropout_with_add_softmax(self, x1, 2, 0.9, -1) tensor([[[[0.0000, 0.0639, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0632, 0.0000, ..., 0.0000, 0.0000, 0.0000], ..., [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0794, ..., 0.0000, 0.0000, 0.1571], [0.0000, 0.0000, 0.0000, ..., 0.1270, 0.0000, 0.0000]], [[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.1030, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], ..., [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]], [[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.2134, 0.0000, ..., 0.0000, 0.0000, 0.0000], ..., [0.0342, 0.0000, 0.0633, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.1578, 0.1334, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]], ..., [[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.2316, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], ..., [0.0000, 0.0237, 0.0000, ..., 0.0000, 0.2128, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.1421, 0.0000, 0.0000, ..., 0.0499, 0.0000, 0.0000]], [[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], ..., [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0218, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]], [[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.1461, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], ..., [0.0000, 0.1130, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.1976, ..., 0.0000, 0.0000, 0.0000]]]], device='npu:0')
- func: npu_multi_head_attention(Tensor query, Tensor key, Tensor value, Tensor query_weight, Tensor key_weight, Tensor value_weight, Tensor attn_mask, Tensor out_proj_weight, Tensor? query_bias, Tensor? key_bias, Tensor? value_bias, Tensor? out_proj_bias, Tensor? dropout_mask, int attn_head_num, int attn_dim_per_head, int src_len, int tgt_len, float dropout_prob, bool softmax_use_float) -> (Tensor, Tensor, Tensor, Tensor, Tensor, Tensor, Tensor, Tensor)
impl_ns: acl_op
实现Transformer模块中的MultiHeadAttention计算逻辑。
- 输入参数:
- query: Tensor类型,仅支持float16
- key: Tensor类型,仅支持float16
- value: Tensor类型,仅支持float16
- query_weight: Tensor类型,仅支持float16
- key_weight: Tensor类型,仅支持float16
- value_weight: Tensor类型,仅支持float16
- attn_mask: Tensor类型,仅支持float16
- out_proj_weight: Tensor类型,仅支持float16
- query_bias: Tensor类型,仅支持float16
- key_bias: Tensor类型,仅支持float16
- value_bias: Tensor类型,仅支持float16
- out_proj _bias: Tensor类型,仅支持float16
- dropout_mask_input: Tensor类型,仅支持float16
- attn_head_num: Attention Head numbers, Int型
- attn_dim_per_head:Attention dim of a Head , Int型
- src_len:source length, Int型
- tgt_len:target length, Int型
- keep_prob:dropout keep probability, Float型
- softmax_use_float:SoftMax Use Float32 to keep precision, Bool型
- 输出参数:
- y: Tensor类型,仅支持float16
- dropout_mask: Tensor类型,仅支持float16
- query_res: Tensor类型,仅支持float16
- key_res: Tensor类型,仅支持float16
- value_res: Tensor类型,仅支持float16
- attn_scores: Tensor类型,仅支持float16
- attn_res: Tensor类型,仅支持float16
- context: Tensor类型,仅支持float16
- 约束条件:
Attr attn_dim_per_head:需16对齐
Attr src_len:需16对齐
tgt_len:需16对齐
- 示例:
import torch import torch_npu import numpy as np batch = 8 attn_head_num = 16 attn_dim_per_head = 64 src_len = 64 tgt_len = 64 dropout_prob = 0.0 softmax_use_float = True weight_col = attn_head_num * attn_dim_per_head query = torch.from_numpy(np.random.uniform(-1, 1, (batch * tgt_len, weight_col)).astype("float16")).npu() key = torch.from_numpy(np.random.uniform(-1, 1, (batch * src_len, weight_col)).astype("float16")).npu() value = torch.from_numpy(np.random.uniform(-1, 1, (batch * tgt_len, weight_col)).astype("float16")).npu() query_weight = torch.from_numpy(np.random.uniform(-1, 1, (weight_col, weight_col)).astype("float16")).npu() key_weight = torch.from_numpy(np.random.uniform(-1, 1, (weight_col, weight_col)).astype("float16")).npu() value_weight = torch.from_numpy(np.random.uniform(-1, 1, (weight_col, weight_col)).astype("float16")).npu() out_proj_weight = torch.from_numpy(np.random.uniform(-1, 1, (weight_col, weight_col)).astype("float16")).npu() attn_mask = torch.from_numpy(np.random.uniform(-1, 1, (batch, attn_head_num, tgt_len, src_len)).astype("float16")).npu() query_bias = torch.from_numpy(np.random.uniform(-1, 1, (weight_col,)).astype("float16")).npu() key_bias = torch.from_numpy(np.random.uniform(-1, 1, (weight_col,)).astype("float16")).npu() value_bias = torch.from_numpy(np.random.uniform(-1, 1, (weight_col,)).astype("float16")).npu() out_proj_bias = torch.from_numpy(np.random.uniform(-1, 1, (weight_col,)).astype("float16")).npu() dropout_mask_input = torch.from_numpy(np.random.uniform(-1, 1, (weight_col,)).astype("float16")).npu() npu_result, npu_dropout_mask, npu_query_res, npu_key_res, npu_value_res, npu_attn_scores, npu_attn_res, npu_context = torch_npu.npu_multi_head_attention (query, key, value, query_weight, key_weight, value_weight, attn_mask, out_proj_weight, query_bias, key_bias, value_bias, out_proj_bias, dropout_mask_input, attn_head_num, attn_dim_per_head, src_len, tgt_len, dropout_prob, softmax_use_float) print(npu_result) tensor([[ 623.5000, 75.5000, 307.0000, ..., 25.3125, -418.7500, 35.9688], [-254.2500, -165.6250, 176.2500, ..., 87.3750, 78.0000, 65.2500], [ 233.2500, 207.3750, 324.7500, ..., 38.6250, -264.2500, 153.7500], ..., [-110.2500, -92.5000, -74.0625, ..., -68.0625, 195.6250, -157.6250], [ 300.0000, -184.6250, -6.0039, ..., -15.7969, -299.0000, -93.1875], [ -2.5996, 36.8750, 100.0625, ..., 112.7500, 202.0000, -166.3750]], device='npu:0', dtype=torch.float16)
torch_npu. npu_geglu(Tensor self, int dim=-1, int approximate=1) -> (Tensor, Tensor)
对输入Tensor完成GeGlu运算。
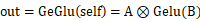
其中,A和B是对输入self沿指定轴平均切分,dim默认值为-1
- 参数解释:
- Tensor self:待进行GeGlu计算的入参,npu device侧的aclTensor,数据类型支持FLOAT32、FLOAT16、BFLOAT16(Atlas A2 训练系列产品支持),支持非连续的Tensor,数据格式支持ND。
- int dim:可选入参,设定的slice轴,数据类型支持INT64。
- int approximate:可选入参,GeGlu计算使用的激活函数索引,0表示使用none,1表示使用tanh,数据类型支持INT64。
- out:GeGlu计算的出参,npu device侧的aclTensor,数据类型必须和self一致,支持非连续的Tensor,数据格式支持ND。
- outGelu:GeGlu计算的出参,npu device侧的aclTensor,数据类型必须和self一致,支持非连续的Tensor,数据格式支持ND。
- 约束条件:
out、outGelu在dim维的size等于self在dim维size的1/2。
当self.dim()==0时,dim的取值在[-1, 0]范围内;当self.dim()>0时,取值在[-self.dim(), self.dim()-1]范围内。
- 示例:
data_x = np.random.uniform(-2, 2, [24,9216,2560]).astype(np.float16) x_npu = torch.from_numpy(data_x).npu() x_npu: tensor([[[ 0.8750, 0.4766, -0.3535, ..., -1.4619, 0.3542, -1.8389], [ 0.9424, -0.0291, 0.9482, ..., 0.5640, -1.2959, 1.7666], [-0.4958, -0.6787, 0.0179, ..., 0.4365, -0.8311, -1.7676], ..., [-1.1611, 1.4766, -1.1934, ..., -0.5913, 1.1553, -0.4626], [ 0.4873, -1.8105, 0.5723, ..., 1.3193, -0.1558, -1.6191], [ 1.6816, -1.2080, -1.6953, ..., -1.3096, 0.4158, -1.2168]], [[ 1.4287, -1.9863, 1.4053, ..., -1.7676, -1.6709, -1.1582], [-1.3281, -1.9043, 0.7725, ..., -1.5596, 0.1632, -1.0732], [ 1.0254, -1.6650, 0.1318, ..., -0.8159, -0.7134, -0.4536], ..., [ 0.0327, -0.6206, -0.1492, ..., -1.2559, 0.3777, -1.2822], [-1.1904, 1.1260, -1.3369, ..., -1.4814, 0.4463, 1.0205], [-0.1192, 1.7783, 0.1040, ..., 1.0010, 1.5342, -0.5728]], [[-0.3296, 0.5703, 0.6338, ..., 0.2131, 1.1113, 0.9854], [ 1.4336, -1.7568, 1.8164, ..., -1.2012, -1.8721, 0.6904], [ 0.6934, 0.3743, -0.9448, ..., -0.9946, -1.6494, -1.3564], ..., [ 1.1855, -0.9663, -0.8252, ..., 0.2285, -1.5684, -0.4277], [ 1.1260, 1.2871, 1.2754, ..., -0.5171, -1.1064, 0.9624], [-1.4639, -0.0661, -1.7178, ..., 1.2656, -1.9023, -1.1641]], ..., [[-1.8350, 1.0625, 1.6172, ..., 1.4160, 1.2490, 1.9775], [-0.5615, -1.9990, -0.5996, ..., -1.9404, 0.5068, -0.9829], [-1.0771, -1.5537, -1.5654, ..., 0.4678, -1.5215, -1.7920], ..., [-1.3389, -0.3228, -1.1514, ..., 0.8882, -1.9971, 1.2432], [-1.5439, -1.8154, -1.9238, ..., 0.2556, 0.2131, -1.7471], [-1.1074, 1.0391, 0.1556, ..., 1.1689, 0.6470, 0.2463]], [[ 1.2617, -0.8911, 1.9160, ..., -0.3027, 1.7764, 0.3381], [-1.4160, 1.6201, -0.5396, ..., 1.8271, 1.3086, -1.8770], [ 1.8252, 1.3779, -0.3535, ..., -1.5215, -1.4727, -1.0420], ..., [-1.4600, -1.7617, -0.7754, ..., 0.4697, -0.4734, -0.3838], [ 1.8506, -0.3945, -0.0142, ..., -1.3447, -0.6587, 0.5728], [ 1.1523, -1.8027, 0.4731, ..., 0.5464, 1.4014, -1.8594]], [[-0.1467, -0.5752, 0.3298, ..., -1.9902, -1.8281, 1.8506], [ 0.2473, 1.0693, -1.8184, ..., 1.9277, 1.6543, 1.0088], [ 0.0804, -0.7939, 1.3486, ..., -1.1543, -0.4053, -0.0055], ..., [ 0.3672, 0.3274, -0.3369, ..., 1.4951, -1.9580, -0.7847], [ 1.3525, -0.4780, -0.5000, ..., -0.1610, -1.9209, 1.5498], [ 0.4905, -1.7832, 0.4243, ..., 0.9492, 0.3335, 0.9565]]], device='npu:0', dtype=torch.float16) y_npu, y_gelu_npu = torch_npu.npu_geglu(x_npu, dim=-1, approximate=1) y_npu: tensor([[[-9.2590e-02, -1.2054e-01, 1.6980e-01, ..., -6.8542e-02, -2.5254e+00, -6.9519e-02], [ 1.2405e-02, -1.4902e+00, 8.0750e-02, ..., 3.4570e-01, -1.5029e+00, 2.8442e-01], [-9.0271e-02, 4.3335e-01, -1.7402e+00, ..., 1.3574e-01, -5.5762e-01, -1.3123e-01], ..., [ 1.0004e-01, 1.5312e+00, 1.4189e+00, ..., -2.6172e-01, 1.6113e-01, -1.1887e-02], [-5.9845e-02, 2.0911e-01, -6.4735e-03, ..., 5.1422e-02, 2.6289e+00, 2.5977e-01], [ 1.3649e-02, -1.3329e-02, -6.9031e-02, ..., 3.5977e+00, -1.2178e+00, -2.3242e+00]], [[-3.1816e+00, -2.6719e+00, 1.4038e-01, ..., 2.6660e+00, 7.7820e-02, 2.3999e-01], [ 2.9297e+00, -1.7754e+00, 2.6703e-02, ..., -1.3318e-01, -6.2109e-01, -1.9072e+00], [ 1.1316e-01, 5.8887e-01, 8.2959e-01, ..., 1.1273e-01, 1.1481e-01, 4.2419e-02], ..., [-2.6831e-01, -1.7288e-02, 2.6343e-01, ..., 9.3750e-02, -2.2324e+00, 1.2894e-02], [-2.0630e-01, 5.9619e-01, -1.4210e-03, ..., -1.2598e-01, -6.5552e-02, 1.1115e-01], [-1.6143e+00, -1.6150e-01, -4.9774e-02, ..., 8.6426e-02, 1.1879e-02, -1.9795e+00]], [[ 4.3152e-02, 1.9250e-01, -4.7485e-02, ..., -5.8632e-03, 1.4551e-01, -2.1289e+00], [ 4.7951e-03, 2.0691e-01, 4.4458e-01, ..., 4.7485e-02, -4.8889e-02, 1.5684e+00], [-8.9404e-01, -8.0420e-01, -2.9248e-01, ..., 1.6205e-02, 3.5449e+00, 8.2397e-02], ..., [-1.9385e+00, -1.8838e+00, 6.0010e-01, ..., -8.5059e-01, 6.1829e-02, 1.0547e-01], [-5.1086e-02, -1.0760e-01, -7.1228e-02, ..., -9.2468e-02, 4.7900e-01, -3.5278e-01], [ 1.7078e-01, 1.6846e-01, 2.5528e-02, ..., 1.3708e-01, 1.4954e-01, -2.8418e-01]], ..., [[-6.3574e-01, -2.0156e+00, 9.3994e-02, ..., 2.2402e+00, -6.2218e-03, 8.7402e-01], [ 1.5010e+00, -1.8518e-01, -3.0930e-02, ..., 1.1511e-01, -3.8300e-02, -1.6150e-01], [-2.8442e-01, 4.4373e-02, -1.0022e-01, ..., 9.2468e-02, -1.2524e-01, -1.2115e-01], ..., [ 3.4760e-02, 1.9812e-01, -9.1431e-02, ..., -1.1650e+00, 2.4011e-01, -1.0919e-01], [-1.5283e-01, 1.8535e+00, 4.4360e-01, ..., 6.4844e-01, -2.8784e-01, -2.5938e+00], [-9.9915e-02, 4.6436e-01, 6.6528e-02, ..., -1.2817e-01, -1.5686e-01, -5.4962e-02]], [[-2.3279e-01, 4.5630e-01, -5.4834e-01, ..., 5.9013e-03, -4.7974e-02, -2.7617e+00], [-1.0760e-01, -2.0371e+00, 3.7915e-01, ..., 6.4551e-01, 2.6953e-01, -1.0910e-03], [ 4.9683e-01, 1.2402e+00, -1.0429e-02, ..., 3.4294e-03, -8.2959e-01, 1.2012e-01], ..., [ 1.6956e-01, 5.3027e-01, -1.6418e-01, ..., -2.1094e-01, -9.8267e-02, 2.3364e-01], [ 4.1687e-02, -1.1365e-01, 1.2598e+00, ..., -5.6299e-01, 1.5967e+00, 9.3445e-02], [ 9.7656e-02, -4.5410e-01, -2.9395e-01, ..., -1.6565e-01, -8.2153e-02, -7.0068e-01]], [[ 1.6345e-01, 2.5806e-01, -6.1951e-02, ..., -6.5857e-02, -6.0303e-02, -1.9080e-01], [ 1.9666e-01, 1.8262e+00, -1.1951e-01, ..., 1.0138e-01, -2.0911e-01, -6.0638e-02], [-6.9141e-01, -2.5234e+00, -1.2734e+00, ..., 1.0510e-01, -1.6504e+00, -9.7070e-01], ..., [-2.5406e-03, -3.1342e-02, -7.0862e-02, ..., 9.2041e-02, 7.7271e-02, 8.0518e-01], [-1.5161e-01, -6.8848e-02, 7.0801e-01, ..., 7.0166e-01, -3.3661e-02, -1.4319e-01], [-3.0899e-02, 1.4490e-01, 1.9763e-01, ..., -8.1116e-02, 7.8955e-01, 1.8347e-01]]], device='npu:0', dtype=torch.float16) y_gelu_npu: tensor([[[-1.5771e-01, -1.4331e-01, -1.0846e-01, ..., -1.1133e-01, 1.3818e+00, -1.5076e-01], [-1.8600e-02, 1.6904e+00, -6.9336e-02, ..., 3.6890e-01, 1.6768e+00, 2.5146e-01], [ 7.5342e-01, 6.0742e-01, 1.0820e+00, ..., 1.5063e-01, 1.1572e+00, -9.4482e-02], ..., [-1.5796e-01, 8.4082e-01, 9.2627e-01, ..., -1.6064e-01, -1.1096e-01, -1.6370e-01], [ 3.4814e-01, -1.6418e-01, -3.1982e-02, ..., -1.5186e-01, 1.3330e+00, -1.4111e-01], [-8.4778e-02, -1.1023e-01, -1.0669e-01, ..., 1.9521e+00, 9.5654e-01, 1.5635e+00]], [[ 1.7881e+00, 1.8359e+00, -1.6663e-01, ..., 1.4609e+00, -1.6760e-01, -1.6528e-01], [ 1.9434e+00, 1.7168e+00, -1.1615e-01, ..., -9.8816e-02, 9.4043e-01, 1.2344e+00], [-1.6064e-01, 5.7031e-01, 1.6475e+00, ..., -1.0809e-01, -1.6785e-01, -1.6345e-01], ..., [-1.6797e-01, -4.6326e-02, 2.6904e-01, ..., 6.9458e-02, 1.3174e+00, 1.3486e+00], [-1.0645e-01, 3.0249e-01, -9.9411e-03, ..., -1.3928e-01, -1.0974e-01, -7.1533e-02], [ 1.7012e+00, -1.0254e-01, -8.2825e-02, ..., -4.8492e-02, -1.1926e-01, 1.7490e+00]], [[-6.6650e-02, -1.0370e-01, -2.3788e-02, ..., -1.0706e-01, -1.6980e-01, 1.4209e+00], [-5.2986e-03, -1.1133e-01, 2.5439e-01, ..., -3.9459e-02, -6.8909e-02, 1.2119e+00], [ 6.1035e-01, 6.8506e-01, -1.5039e-01, ..., 5.8136e-02, 1.8232e+00, -6.7383e-02], ..., [ 1.4434e+00, 1.6787e+00, 1.2422e+00, ..., 7.5488e-01, -5.0720e-02, -6.8787e-02], [-1.4600e-01, -1.2213e-01, -1.6711e-01, ..., 3.7280e-01, 1.3125e+00, 2.2375e-01], [ 3.4985e-01, -1.2659e-01, -4.6722e-02, ..., -1.4685e-01, 1.4856e-01, -1.6406e-01]], ..., [[ 4.8730e-01, 1.6680e+00, -5.7098e-02, ..., 1.4189e+00, 7.1983e-03, 7.8857e-01], [ 1.1328e+00, -1.6931e-01, -1.1163e-01, ..., -1.6467e-01, 3.5309e-02, -1.5173e-01], [-1.6858e-01, -8.9111e-02, -1.4709e-01, ..., -8.1970e-02, 5.4248e-01, 5.0830e-01], ..., [ 2.1936e-01, 7.7197e-01, 4.8737e-02, ..., 8.7842e-01, -1.6406e-01, -7.1716e-02], [-1.2720e-01, 1.9404e+00, 1.0391e+00, ..., 7.3877e-01, -1.6199e-01, 1.5781e+00], [-1.6968e-01, 1.0664e+00, -1.6431e-01, ..., -7.5439e-02, -1.5332e-01, 2.1790e-01]], [[ 3.0981e-01, 6.0010e-01, 7.9346e-01, ..., 4.0169e-03, 5.8447e-01, 1.7109e+00], [-1.6699e-01, 1.7646e+00, 5.9326e-01, ..., 3.3813e-01, -1.5845e-01, -4.7699e-02], [ 3.7573e-01, 9.4580e-01, -9.5276e-02, ..., 2.4805e-01, 8.3350e-01, 1.2573e-01], ..., [-1.5369e-01, 1.2021e+00, -1.6626e-01, ..., -1.1108e-01, 1.6084e+00, -1.4807e-01], [-4.6234e-02, -6.4331e-02, 8.9844e-01, ..., 9.2871e-01, 7.9834e-01, -1.6992e-01], [-6.4941e-02, 1.1465e+00, -1.5161e-01, ..., -1.5076e-01, -8.6487e-02, 1.0137e+00]], [[-1.1731e-01, -1.4404e-01, -8.9050e-02, ..., -1.2128e-01, -1.0919e-01, -1.6943e-01], [ 1.5186e-01, 1.1396e+00, -6.5735e-02, ..., -7.4829e-02, -1.6455e-01, -8.9355e-02], [ 6.4404e-01, 1.5625e+00, 1.7725e+00, ..., -5.5176e-02, 1.7920e+00, 6.6504e-01], ..., [ 1.9083e-03, 3.8452e-01, -4.9011e-02, ..., -1.5405e-01, -1.6003e-01, 1.3975e+00], [ 1.0437e-01, -8.6182e-02, 5.5713e-01, ..., 1.0645e+00, -1.3818e-01, 5.1562e-01], [-1.0229e-01, -1.0529e-01, 2.6562e-01, ..., -5.6702e-02, 1.0830e+00, -1.6833e-01]]], device='npu:0', dtype=torch.float16)
torch_npu.npu_rms_norm(Tensor self, Tensor gamma, float epsilon=1e-06) -> (Tensor, Tensor)
RmsNorm算子是大模型常用的归一化操作,相比LayerNorm算子,其去掉了减去均值的部分 。其计算公式为

- 参数说明
- self:Tensor类型,支持float16、bfloat16、float32,输入shape支持2-8维。
- gamma:Tensor类型,数据类型需要和self保持一致,输入shape支持2-8维,通常为self的最后一维。
- epsilon:float数据类型,用于防止除0错误。
- 输出说明
第1个输出为Tensor,计算公式的最终输出y;
第2个输出为Tensor,rms_norm的reverse rms中间结果,用于反向计算。
- 约束说明
- 调用示例
import torch import torch_npu x = torch.randn(24, 1, 128).bfloat16().npu() w = torch.randn(128).bfloat16().npu() out1 = torch.npu_rms_norm(x, w, epsilon=1e-5)[0] print(out1) tensor([[[-0.1123, 0.3398, 0.0986, ..., -2.1250, -0.8477, -0.3418]], [[-0.0591, 0.3184, -0.5000, ..., 1.0312, -1.1719, -0.1621]], [[-0.1445, 0.3828, -0.3438, ..., -0.9102, -0.5703, 0.0073]], ..., [[-0.1631, -0.3477, 0.4297, ..., 0.9219, 0.1621, 0.3125]], [[-0.1387, 0.0815, 0.0967, ..., 1.7109, 0.1455, -0.1406]], [[ 0.0698, 1.3438, -0.0127, ..., -2.2656, -0.4473, 0.3281]]], device='npu:0', dtype=torch.bfloat16)