前提条件
- 在进行TensorFlow 1.x原始训练网络生成npy或dump数据前,要求有一套完整、可执行的标准TensorFlow模型训练工程。GPU训练环境准备可以参考在ECS上快速创建GPU训练环境,链接内容仅供参考,请以实际训练场景为准。
- 不论采用Estimator模式或session.run模式,首先要把脚本中所有的随机全部关闭,包括但不限于对数据集的shuffle,参数的随机初始化,以及某些算子的隐形随机初始化(比如dense算子),确认自己脚本内所有参数均非随机初始化。
生成npy数据文件
利用TensorFlow官方提供的debug工具tfdbg生成npy文件。详细的操作方法如下:
- 修改TensorFlow训练脚本,添加debug选项设置。
- 如果采用Estimator模式,采用如下方式添加tfdbg的hook。
- 新增from tensorflow.python import debug as tf_debug导入debug模块。
- 在生成EstimatorSpec对象实例,即构造网络结构代码位置,新增代码training_hooks=[tf_debug.LocalCLIDebugHook()]。
图1 Estimator模式
- 如果采用session.run模式,采用如下方式在run之前设置tfdbg装饰器。
- 新增from tensorflow.python import debug as tf_debug导入debug模块。
- 在session初始化结束后,新增sess = tf_debug.LocalCLIDebugWrapperSession(sess, ui_type="readline")。
图2 session.run模式
- 如果采用Estimator模式,采用如下方式添加tfdbg的hook。
- 执行训练脚本。
- 训练任务停止后,视图进入调试命令行交互模式tfdbg,执行run命令,训练会往下执行一个step。
For more details, see help.. tfdbg> run
run命令执行完成后,获取第一个step的训练结果参数,可以依次执行lt命令查询已存储的张量,执行pt命令查看已存储的张量内容,保存数据为npy格式文件。
收集npy数据文件
run命令执行完成后,需要收集npy文件,但由于tfdbg一次只能dump一个tensor,为了自动收集所有npy文件,具体执行操作如下:
- 执行lt > gpu_dump命令将所有tensor的名称暂存到自定义名称的gpu_dump文件里。命令行中会有如下回显。
Wrote output to tensor_name
- 重新开启一个命令行窗口,在新的命令行窗口进入gpu_dump文件所在目录(默认在训练脚本所在目录),执行下述命令,用以生成在tfdbg命令行执行的命令。
timestamp=$[$(date +%s%N)/1000] ; cat gpu_dump | awk '{print "pt",$4,$4}' | awk '{gsub("/", "_", $3);gsub(":", ".", $3);print($1,$2,"-n 0 -w "$3".""'$timestamp'"".npy")}' - 复制所有生成的存储tensor的命令(所有以“pt”开头的命令),回到tfdbg命令行视图所在窗口,粘贴执行,即可存储所有npy文件。存储路径为训练脚本所在目录。
npy文件默认是以numpy.save()形式存储的,上述命令会将“/”与“:”用下划线_替换。

如果命令行界面无法粘贴文件内容,可以在tfdbg命令行中输入“mouse off”指令关闭鼠标模式后再进行粘贴。
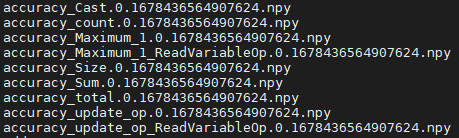
- 检查生成的npy文件命名是否符合{op_name}.{output_index}.{timestamp}.npy格式,如图3所示。
- 如果因算子名较长,造成按命名规则生成的npy文件名超过255字符而产生文件名异常,这类算子不支持精度比对。
- 因tfdbg自身原因或运行环境原因,可能存在部分生成的npy文件名不符合精度比对要求,请按命名规则手工重命名。如果不符合要求的npy文件较多,请参见批量处理生成的npy文件名异常情况重新生成npy文件。
- npy文件命名各字段详细介绍请参见数据格式要求。