基于TBE开发的算子运行在AI Core上,开发人员需要对AI Core架构有认识,本章节介绍AI Core架构基础知识。
总体架构
不同于传统的支持通用计算的CPU和GPU,也不同于专用于某种特定算法的专用芯片ASIC(Application Specific Integrated Circuit),AI Core架构本质上是为了适应某个特定领域中的常见应用和算法,通常称为“特定域架构”(Domain Specific Architecture,DSA)。
昇腾AI处理器的计算核心主要由AI Core构成,从控制上可以看成是一个相对简化的现代微处理器的基本架构。它包括了三种基础计算资源:矩阵计算单元(Cube Unit)、向量计算单元(Vector Unit)和标量计算单元(Scalar Unit)。这三种计算单元各司其职,形成了三条独立的执行流水线,在系统软件的统一调度下互相配合达到优化的计算效率。此外在矩阵计算单元和向量计算单元内部还提供了不同精度、不同类型的计算模式。
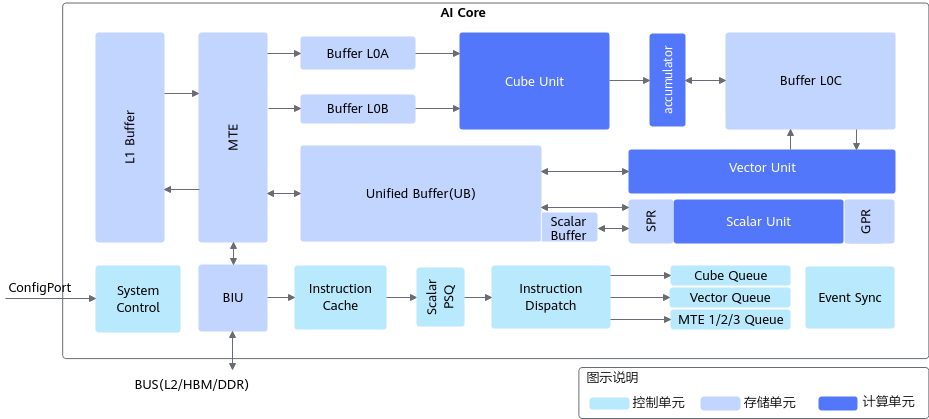
AI Core中包含计算单元、存储单元、与控制单元。
计算单元
计算单元是AI Core中提供强大算力的核心单元,相当于AI Core的主力军。AI Core中的计算单元主要包括:Cube Unit(矩阵计算单元)、Vector Unit(向量计算单元)和Scalar Unit(标量计算单元),完成AI Core中不同类型的数据计算。
计算单元 |
描述 |
|---|---|
Cube |
Cube负责执行矩阵运算。 Cube每次执行可以完成一个fp16的16*16与16*16的矩阵乘,例如C=A*B,如果是int8输入,则一次完成16*32与32*16的矩阵乘。其中A来源于L0A,B来源于L0B,L0C存储矩阵乘的结果和中间结果。 |
Vector |
Vector负责执行向量运算。 其算力低于Cube,但灵活度高于Cube(如支持数学中的求倒数,求平方根等)。Vector所有计算的源数据以及目标数据都要求存储在Unified Buffer中,并要求32Byte对齐。 |
Scalar |
Scalar负责各类型的标量数据运算和程序的流程控制。 功能上可以看做一个小CPU,完成整个程序的循环控制、分支判断、Cube/Vector等指令的地址和参数计算以及基本的算术运算等。 |
存储单元
AI Core中存在内部存储,AI Core需要把外部存储中的数据加载到内部存储中,才能完成相应的计算。AI Core的主要内部存储包括:L1 Buffer(L1缓冲区),L0 Buffer(L0缓冲区),Unified Buffer(统一缓冲区)和Scalar Buffer(标量缓冲区)。
为了配合AI Core中的数据传输和搬运,AI Core中还包含BIU(Bus Interface Unit,总线接口单元),MTE1(Memory Transfer Engine,存储转换引擎),MTE2,MTE3。其中BIU为AI Core与总线交互的接口;MTE为数据搬运单元,完成不同Buffer之间的数据搬运。
不同类型的昇腾AI处理器,存储单元大小不同,用户可通过get_soc_spec接口获取。
AI Core的内部存储列表如表2所示。
存储单元 |
描述 |
|---|---|
MTE |
AI Core上有多个MTE(Memory Transfer Engine,存储转换引擎),MTE负责AI Core内部数据在不同Buffer之间的读写管理及一些格式转换的操作,比如填充(padding)、转置(transpose)、3D图像转2D矩阵(Img2Col)等。 |
BIU |
BIU (Bus Interface Unit,总线接口单元), AI Core的“大门”,负责AI Core与总线的交互。BIU是AI Core从外部存储读取数据以及往外写数据的出入口,负责把AI Core的读写请求转换为总线上的请求并完成协议交互等工作。 |
L1 Buffer |
L1缓冲区,通用内部存储,是AI Core内比较大的一块数据中转区,可暂存AI Core中需要反复使用的一些数据从而减少从总线读写的次数。 某些MTE的数据格式转换功能,要求源数据必须位于L1 Buffer,例如3D图像转2D矩阵(Img2Col)操作。 |
L0A Buffer / L0B Buffer |
Cube指令的输入。 |
L0C Buffer |
Cube指令的输出,但进行累加计算的时候,也是输入的一部分。 |
Unified Buffer |
统一缓冲区,向量和标量计算的输入和输出。 |
Scalar Buffer |
标量计算的通用缓冲区,作为GPR(通用寄存器,General-Purpose Register)不足时的补充。 |
GPR |
通用寄存器(General-Purpose Register),标量计算的输入和输出。 应用开发工程师不需要具体关注这些寄存器。由系统内部实现封装,程序访问Scalar Buffer并执行标量计算的时候,系统内部自动实现Scalar Buffer和GPR之间的同步。 |
SPR |
专用寄存器(Special-Purpose Register),AI Core的一组配置寄存器。 通过修改SPR的内容可以修改AI Core的部分计算行为。 |
本手册将以上AI Core的存储单元分为如下三类:
- Cache:对程序员透明,当指令指定访问下级存储单元的时候,Cache可以对数据进行缓存,从而加快访问速度。
- Buffer:对程序员可见的存储空间,通常用于向量计算或者标量计算中的临时数据保存等。
- Register:对程序员可见的存储空间,通常用于标量计算。
AI Core的每种存储单元只能使用特定的指令访问,当前对程序员开放的存储及指令之间的关系如图2所示。
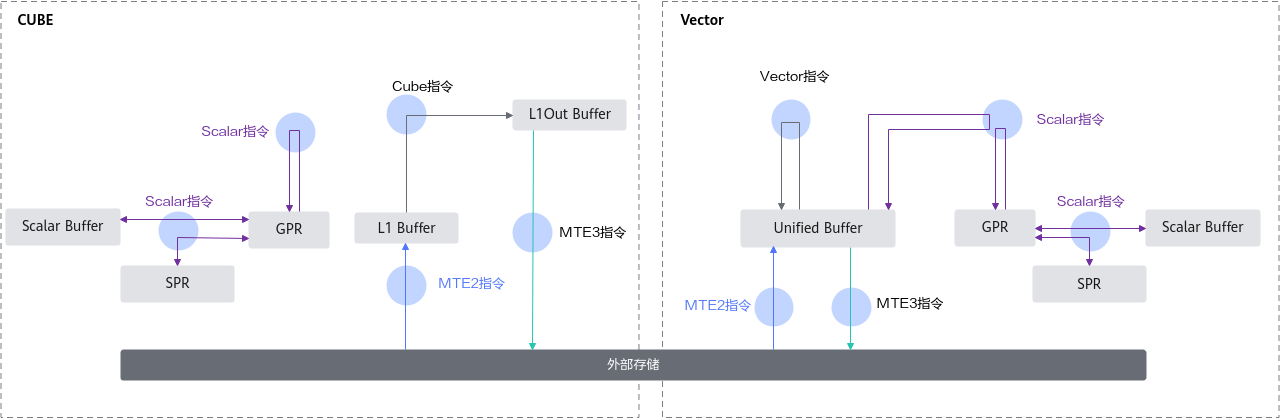

上图的存储单元是软件层面概念,其中:
- Scalar Buffer对应硬件存储单元Scalar Buffer。
- Unified Buffer对应硬件存储单元Unified Buffer。
- L1 Buffer对应硬件存储单元L1 Buffer。
- L1Out Buffer为从L0C上抽象出来的存储Cube计算输出数据的存储单元。
由于开发高性能Cube算子难度较大,当前仅支持用户开发Vector算子。
控制单元
控制单元为整个计算过程提供了指令控制,相当于AI Core的司令部,负责整个AI Core的运行。AI Core包含的控制单元如表3所示。系统控制模块负责指挥和协调AI Core的整体运行模式,配置参数和实现功耗控制等。当指令通过指令发射模块顺次发射出去后,根据指令的不同类型,将会分别被发送到矩阵运算队列、向量运算队列和存储转换队列。
指令执行过程中,可以提前预取后续指令,并一次读入多条指令进入缓存,提升指令执行效率。多条指令从系统内存通过总线接口(BIU)进入到AI Core的指令缓存模块(Instruction Cache)中等待后续硬件快速自动解码或运算。指令被解码后便会被导入标量队列中,实现地址解码与运算控制。
控制单元 |
描述 |
|---|---|
系统控制模块(System Control) |
外部的Task Scheduler控制和初始化AI Core的配置接口, 配置PC、Para_base、BlockID等信息,具体功能包括:Block执行控制、Block执行完之后中断和状态申报、执行错误状态申报等。 |
指令缓存模块(Instruction Cache) |
AI Core内部的指令Cache, 具有指令预取功能。 |
标量指令处理队列(Scalar PSQ) |
Scalar指令处理队列。 |
指令发射模块(Instruction Dispatch) |
CUBE/Vector/MTE指令经过Scalar PSQ处理之后,地址、参数等要素都已经配置好,之后Instruction Dispatch单元根据指令的类型,将CUBE/Vector/MTE指令分别分发到对应的指令队列等待相应的执行单元调度执行。 |
矩阵运算队列(Cube Queue) |
Cube指令队列。同一个队列里的指令顺序执行,不同队列之间可以并行执行。 |
向量运算队列(Vector Queue) |
Vector指令队列。同一个队列里的指令顺序执行,不同队列之间可以并行执行。 |
存储转换队列(MTE Queue) |
MTE指令队列。同一个队列里的指令顺序执行,不同队列之间可以并行执行。 |
事件同步模块(Event Sync) |
用于控制不同队列指令(也叫做不同指令流水)之间的依赖和同步的模块。 |
执行流水线
AI Core采用顺序取指令、并行执行指令的调度方式,如下图所示:
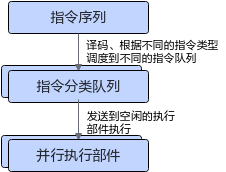
指令序列被顺序译码。根据指令的类型,有两种可能:
- 如果指令是Scalar指令,指令会被直接执行。
- 其他指令,指令会被调度到5个独立的分类队列,然后再分配到某个空间的执行部件执行。
表4 分类队列 队列缩写
队列名称
备注
V
Vector指令队列
用于调度向量指令
M
Matrix指令队列
用于调度Cube指令
MTE1
存储移动指令队列1
用于调度如下内存移动指令:
L1到L0A/L0B/UB,或者用SPR初始化L0A/L0B Buffer
MTE2
存储移动指令队列2
用于调度如下内存移动指令:
GM到L1/L0A/L0B/UB
MTE3
存储移动指令队列3
用于调度如下内存移动指令:
UB到GM
根据调度分类的不同,可以把指令分类,加上被译码过程直接解释的Scalar指令(缩写为S),可以有6种指令分类:S、V、M、MTE1、MTE2、MTE3。
除S队列之外,分属于不同队列的指令能够乱序执行,但是队列内部指令为顺序执行,即在满足数据依赖的前提下,指令的物理执行顺序不一定与代码的书写顺序一致。
硬件按照下发顺序,将不同队列的指令分发到相应的队列上执行,昇腾AI处理器提供Barrier、set_flag/wait_flag两种指令,保证队列内部以及队列之间按照逻辑关系执行。- Barrier本身是一条指令,用于在队列内部约束执行顺序。其作用是,保证前序队列中所有数据的读写工作全部完成,后序指令才能执行。
- set_flag/wait_flag为两条指令,在set_flag/wait_flag的指令中,可以指定一对指令队列的关系,表示两个队列之间完成一组“锁”机制,其作用方式为:
- set_flag:当前序指令的所有读写操作都完成之后,当前指令开始执行,并将硬件中的对应标志位设置为1。
- wait_flag:当执行到该指令时,如果发现对应标志位为0,该队列的后续指令将一直被阻塞;如果发现对应标志位为1,则将对应标志位设置为0,同时后续指令开始执行。
TBE封装了这种依赖关系,所以应用开发人员不必对Barrier或者Flag进行编程。但应用开发人员仍需要理解这个基本原理,才能通过合适的代码调度,实现更好的同步关系。基于DSL方式进行算子开发无需关注代码调度,DSL提供了自动调度(auto_schedule)机制。