算子编译运行逻辑架构
一个完整的CANN算子包含四部分:算子原型定义、对应开源框架的算子适配插件、算子信息库定义和算子实现。
算子开发完成后在昇腾AI处理器硬件平台上的编译运行的架构如图1和图2所示。
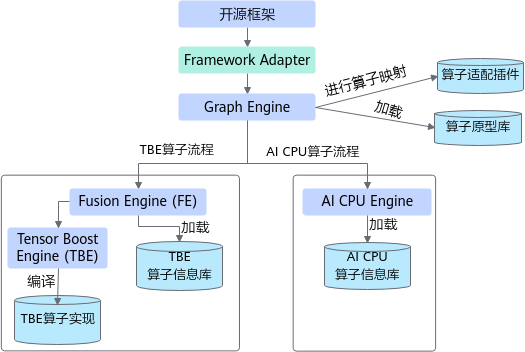
其中,Framework Adapter只有在基于原始框架网络(例如TensorFlow/PyTorch等)进行训练时使用,将模型迁移到CANN平台。
上图中 代表开发人员在全新开发自定义CANN算子时需要实现的交付件。
代表开发人员在全新开发自定义CANN算子时需要实现的交付件。
开发交付件 |
说明 |
|---|---|
算子原型库 |
算子调用入口,算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要体现算子的数学含义,包含定义算子输入、输出、属性和取值范围,基本参数的校验和shape的推导。网络运行时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。 注意:算子原型定义不区分算子类型(TBE或者AI CPU),是昇腾AI处理器中可运行算子的全局约束。 |
算子实现 |
描述算子的计算功能。
|
算子信息库 |
算子信息库区分了TBE算子信息库与AI CPU算子信息库,描述的是对应的算子实现文件的实现规格,也就是对应算子在昇腾AI处理器上实现的限制,包括算子的输入输出dtype、format以及输入shape信息。网络运行时,图编译器会根据算子信息库匹配到具体的算子实现。 |
算子适配插件 |
基于第三方框架(TensorFlow/Caffe)进行自定义算子开发的场景,开发人员完成自定义算子的实现代码后,需要进行适配插件的开发,将基于第三方框架的算子映射成适昇腾AI处理器的算子。基于第三方框架的网络运行时,首先会加载并调用算子适配插件信息,将第三方框架网络中的算子进行解析并映射成昇腾AI处理器中的算子。 注意:如果不需要将算子融入到原始网络中,无需开发算子适配插件。 |

若存在相同OpType的TBE算子与AI CPU算子,Graph Engine会优先匹配TBE算子进行执行。
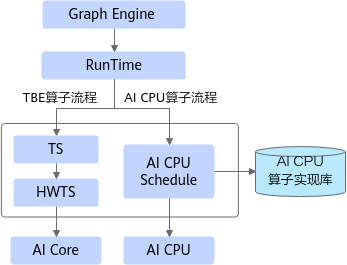
算子编译流程
- TBE算子编译流程
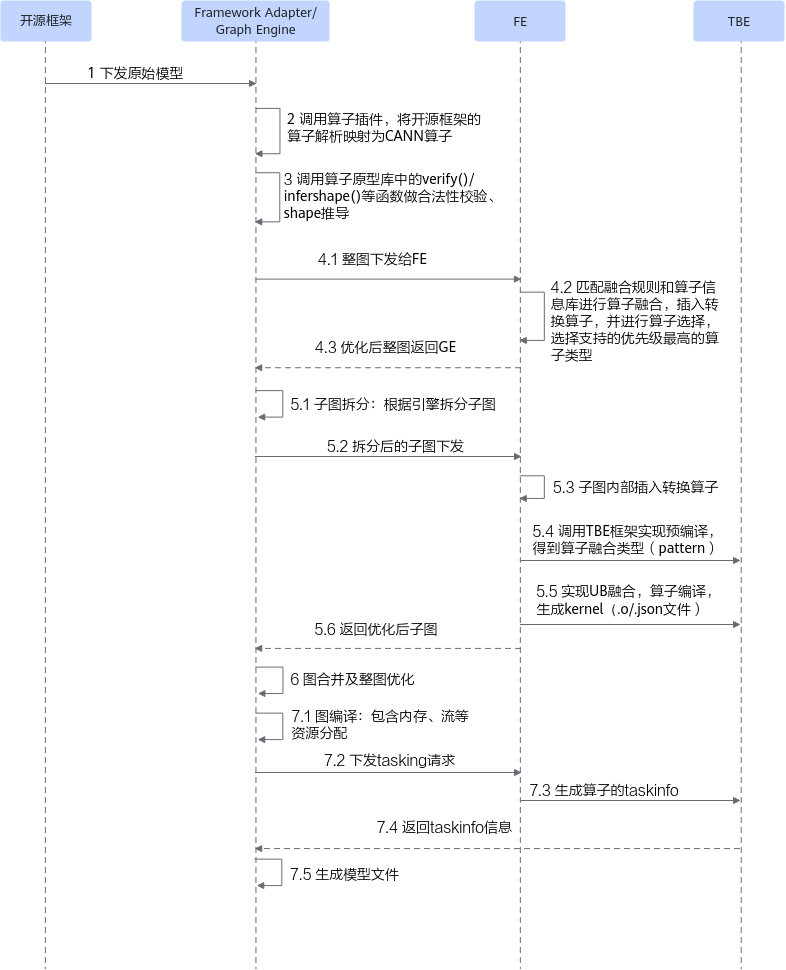
TBE算子的详细编译流程如图3所示。
- 将开源框架网络模型下发给Graph Engine。
若基于Tensorflow或者Pytorch框架进行在线训练,首先会调用TF Adapter或者PT Adapter适配接口生成对应框架的原始网络模型,然后下发给Graph Engine;若原始网络框架为MindSpore,则直接将原始网络模型下发给Graph Engine;若使用AscendCL应用进行模型推理,则直接将原始网络模型下发给Graph Engine。
注:网络模型的拓扑图后续简称为图。
- Graph Engine调用算子插件,将原始网络模型中的算子映射为适配昇腾AI处理器的算子,从而将原始开源框架图解析为适配昇腾AI处理器的图。
若原始网络框架为MindSpore,在MindSpore侧已经进行了算子的解析映射,所以在Graph Engine中无需再次调用插件进行解析。
- 调用算子原型库校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。
- Graph Engine向FE发送图优化请求,并将图下发给FE。FE匹配融合规则进行图融合,并进行算子选择,选择优先级最高的算子类型进行算子匹配(默认自定义算子优先级最高),最后将优化后的整图返回给Graph Engine。
- Graph Engine根据图中数据将图拆分为子图并下发给FE。FE首先在子图内部插入转换算子,然后按照当前子图流程进行TBE算子预编译,对TBE算子进行UB融合(算子可以在UB中根据UB融合规则自动与其他算子的计算进行组装),并根据算子信息库中算子信息找到算子实现,将其编译成算子kernel(算子的*.o与*.json),最后将优化后子图返回给Graph Engine。
- Graph Engine将子图进行合并,并对合并后的整图进一步优化。
- Graph Engine进行图编译,包含内存分配、流资源分配等,并向FE发送tasking请求,FE返回算子的taskinfo信息给Graph Engine,图编译完成后生成适配昇腾AI处理器的模型。
- 将开源框架网络模型下发给Graph Engine。
- AI CPU算子编译流程
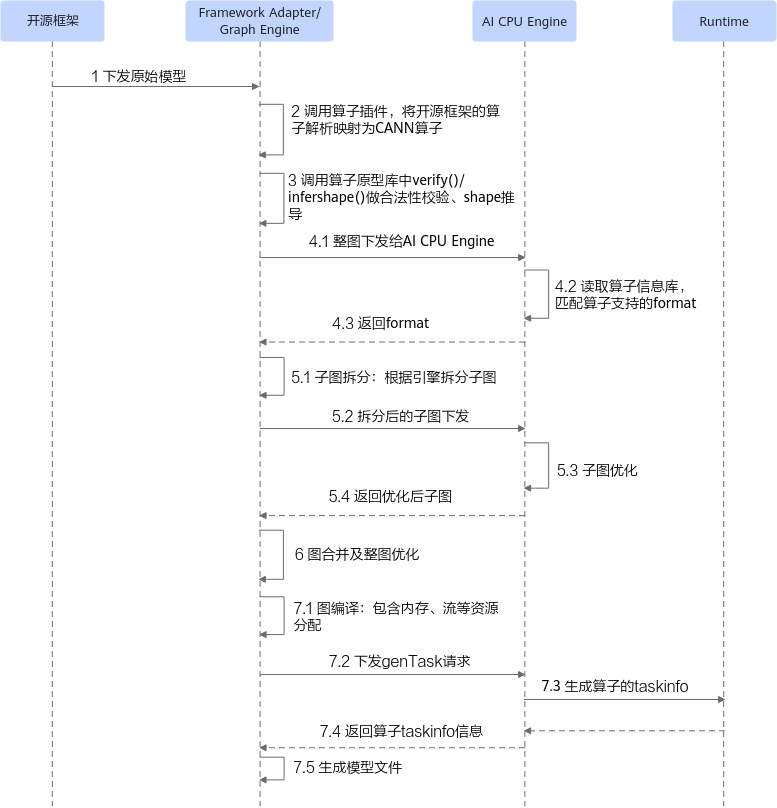
AI CPU算子的详细编译流程如图4所示。
- 将开源框架网络模型下发给Graph Engine。
若基于Tensorflow或者Pytorch框架进行在线训练,首先会调用TF Adapter或者PT Adapter适配接口生成对应框架的原始网络模型,然后下发给Graph Engine;若原始网络框架为MindSpore,则直接将原始网络模型下发给Graph Engine;若使用AscendCL应用进行模型推理,则直接将原始网络模型下发给Graph Engine。
注:网络模型的拓扑图后续简称为图。
- Graph Engine调用算子插件,将原始网络模型中的算子映射为适配昇腾AI处理器的算子,从而将原始开源框架图解析为适配昇腾AI处理器的图。
若原始网络框架为MindSpore,在MindSpore侧已经进行了算子的解析映射,所以在Graph Engine中无需再次调用插件进行解析。
- 调用算子原型库校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。
- Graph Engine向整图下发给AI CPU Engine,AI CPU Engine读取算子信息库,匹配算子支持的format,并将format返回给GE。
- Graph Engine根据图中数据将图拆分为子图并下发给AI CPU Engine,AI CPU Engine进行子图优化,并将优化后子图返回给GE。
- Graph Engine将子图进行合并,并对合并后的整图进一步优化。
- Graph Engine进行图编译,包含内存分配、流资源分配等,并向AI CPU Engine发送genTask请求,AI CPU Engine返回算子的taskinfo信息给Graph Engine,图编译完成之后生成适配昇腾AI处理器的模型。
- 将开源框架网络模型下发给Graph Engine。
算子运行流程
- TBE算子运行流程
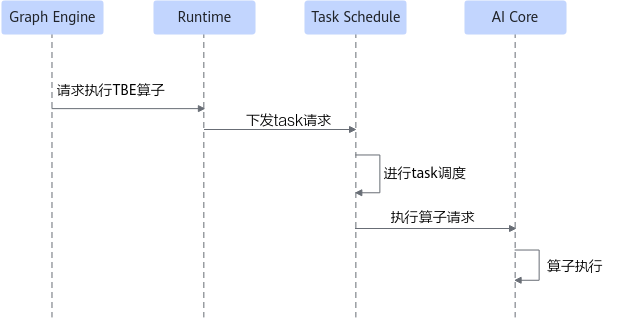
TBE算子的运行流程如图5所示。
- Graph Engine加载编译好的模型,并下发算子执行请求。
- Runtime将对应的task请求下发给Task Schedule。
- Task Schedule进行task调度,调用算子计算接口。
- 算子在AI Core上执行。
- AI CPU算子运行流程
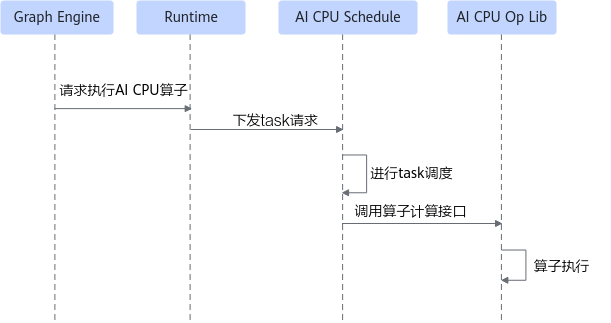
AI CPU的算子运行流程如图6所示。
- Graph Engine下发算子执行请求。
- Runtime将对应的task请求下发给AI CPU Schedule。
- AI CPU Schedule进行task调度,调用算子计算接口。
- AI CPU算子库解析并实例化算子实现,并执行Compute函数完成算子执行。