根据上一章节介绍,核函数中会调用算子类的Init和Process函数,本章具体讲解基于编程范式实现算子类。矩阵编程范式请参考编程范式。
class KernelMatmul {
public:
__aicore__ inline KernelMatmul(){}
// 初始化函数,完成内存初始化相关操作
__aicore__ inline void Init(GM_ADDR a, GM_ADDR b, GM_ADDR c){}
// 核心处理函数,实现算子逻辑
// 调用私有成员函数CopyIn、SplitA、SplitB、Compute、Aggregate、CopyOut完成矩阵算子的五级流水操作
__aicore__ inline void Process(){}
private:
__aicore__ inline void CopyND2NZ(const LocalTensor<half>& dst, const GlobalTensor<half>& src, const uint16_t height, const uint16_t width){}
// 搬进函数,完成编程范式中的CopyIn阶段的处理,由Process函数调用
__aicore__ inline void CopyIn(){}
// 搬进函数,完成编程范式中的Split阶段的处理,由Process函数调用
__aicore__ inline void SplitA(){}
// 搬进函数,完成编程范式中的Split阶段的处理,由Process函数循环调用两次,分别搬运b矩阵的两个part
__aicore__ inline void SplitB(const LocalTensor<half>& b1Local, const int bSplitIdx){}
// 计算函数,完成编程范式中的Compute阶段的处理,由Process函数循环调用两次,分别计算出矩阵c的两个part
__aicore__ inline void Compute(const LocalTensor<half>& a2Local){}
// 搬出函数,完成编程范式中的Aggregate阶段的处理,由Process函数循环调用两次,分别搬出矩阵c的两个part
__aicore__ inline void Aggregate(const LocalTensor<float>& c2Local, const int bSplitIdx){}
// 搬出函数,完成编程范式中的CopyOut阶段的处理,由Process函数调用
__aicore__ inline void CopyOut(){}
private:
TPipe pipe; // Pipe内存管理对象,管理Queue队列的内存
TQue<QuePosition::A1, 1> inQueueA1; // 输入数据的队列,QuePosition为A1
TQue<QuePosition::A2, 1> inQueueA2; // 输入数据的队列,QuePosition为A2
TQue<QuePosition::B1, 1> inQueueB1; // 输入数据的队列,QuePosition为B1
TQue<QuePosition::B2, 2> inQueueB2; // 输入数据的队列,QuePosition为B2
TQue<QuePosition::CO1, 2> outQueueCO1; // 输出数据的队列,QuePosition为CO1
TQue<QuePosition::CO2, 1> outQueueCO2; // 输出数据的队列,QuePosition为CO2
// 管理输入输出Global Memory内存地址的对象,其中aGM,bGM为输入,cGM为输出
GlobalTensor<half> aGM, bGM;
GlobalTensor<float> cGM;
uint16_t m = 32;
uint16_t n = 32;
uint16_t k = 32;
uint16_t aSize, bSize, cSize, mBlocks, nBlocks, kBlocks;
};
KernelMatmul构造函数实现
构造函数中对私有成员变量进行初始化,具体代码如下:
__aicore__ inline KernelMatmul()
{
aSize = m * k;
bSize = k * n;
cSize = m * n;
mBlocks = m / 16;
nBlocks = n / 16;
kBlocks = k / 16;
}
矩阵a的形状为[m, k],矩阵b的形状为[k, n],矩阵c的形状为[m,n],此样例中m、n、k均设置为32。
aSize、bSize、cSize分别为矩阵a、b、c的数值个数。
mBlocks、 nBlocks、 kBlocks为m、n、k所占分形数量,half类型一个分形长度为16,blocks计算公式为:
- mBlocks = m / 16
- nBlocks = n / 16
- kBlocks = k / 16
分形具体介绍可参考数据排布格式。
Init函数实现
Init函数主要完成以下内容:
- 设置输入输出Global Tensor的Global Memory内存地址。
注意,因为本样例中Init函数的入参统一设置为uint8_t*,这里需要强转成具体的数据类型(__gm__ half*),再进行偏移。
- 通过Pipe内存管理对象为输入输出Queue分配内存。
比如,为输入数据队列inQueueB2分配内存,可以通过如下代码段实现:
pipe.InitBuffer(inQueueB2, 2, bSize * sizeof(half) / 2);
此样例中将b矩阵切分为两个part,为inQueueB2分配内存时需要申请两块内存空间,每一块的大小为b矩阵大小的一半,outQueueCO1的内存初始化同理。
具体的初始化函数代码如下:
__aicore__ inline void Init(GM_ADDR a, GM_ADDR b, GM_ADDR c)
{
aGM.SetGlobalBuffer((__gm__ half*)a);
bGM.SetGlobalBuffer((__gm__ half*)b);
cGM.SetGlobalBuffer((__gm__ float*)c);
pipe.InitBuffer(inQueueA1, 1, aSize * sizeof(half));
pipe.InitBuffer(inQueueA2, 1, aSize * sizeof(half));
pipe.InitBuffer(inQueueB1, 1, bSize * sizeof(half));
pipe.InitBuffer(inQueueB2, 2, bSize * sizeof(half) / 2);
pipe.InitBuffer(outQueueCO1, 2, cSize * sizeof(float) / 2);
pipe.InitBuffer(outQueueCO2, 1, cSize * sizeof(float));
}
Process函数实现
基于矩阵编程范式,将核函数的实现分为5个基本阶段:CopyIn,Split,Compute,Aggregate,CopyOut。Split,Compute,Aggregate阶段需要区分a、b矩阵。Process函数中通过如下方式调用这几个函数。
__aicore__ inline void Process()
{
CopyIn();
SplitA();
LocalTensor<half> b1Local = inQueueB1.DeQue<half>();
LocalTensor<half> a2Local = inQueueA2.DeQue<half>();
LocalTensor<float> c2Local = outQueueCO2.AllocTensor<float>();
// split matrix b into 2 parts, [32, 16] and [32, 16]
for (int i = 0; i < 2; ++i) {
SplitB(b1Local, i);
Compute(a2Local);
Aggregate(c2Local, i);
}
inQueueB1.FreeTensor(b1Local);
inQueueA2.FreeTensor(a2Local);
outQueueCO2.EnQue<float>(c2Local);
CopyOut();
}
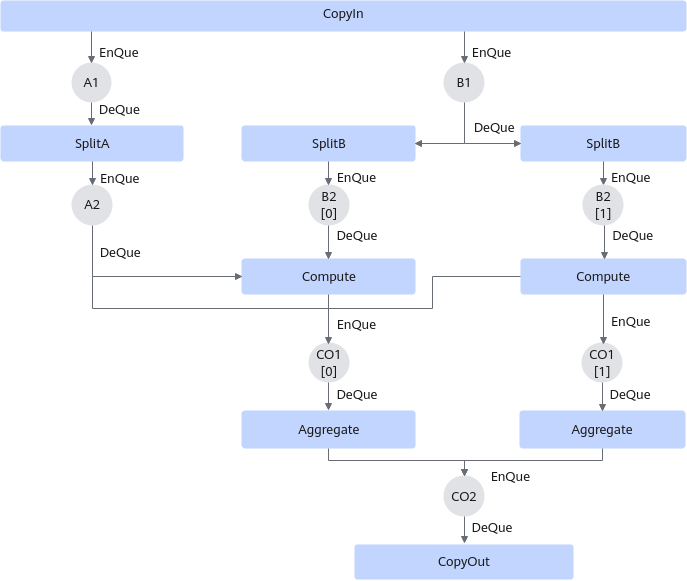
两次循环内,SplitB需要从inQueueB1中分别搬运两个part的b矩阵,Compute需要分别计算a矩阵和两个part b矩阵的乘法,Aggregate要分别搬运两个part的c矩阵,具体五个阶段数据流通示意图如下:
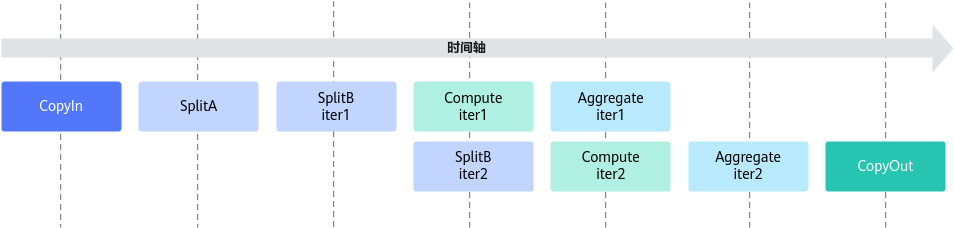
切分b矩阵,可以实现一部分的并行,本样例的流水并行示意图如下:
- Stage1:CopyIn函数实现。
- 使用AllocTensor从A1,B1的Queue中申请a1Local和b1Local。
- 使用DataCopy接口将矩阵a、b搬运到Local Memmory,同时将其数据格式从ND转换为NZ。
一次DataCopy指令搬运height*16个数,循环执行width/16次。DataCopy的参数设置如下:
- blockCount设置为height,共搬运height次。
- blockLen设置为1,一次搬运16个类型为half的数。
- srcStride设置为width/16 - 1,源矩阵每搬运一个block需要跳跃一行。
- dstStride设置为0,目的矩阵每个block在内存中连续存储。
- 每次循环迭代,源矩阵首地址移动16个数,目的矩阵首地址移动16*height个数。
格式转换示意图如下,第一次循环搬运蓝色部分,第二次循环搬运绿色部分;图中width为32,占两个分形,height为32,占两个分形,一共搬运4个16*16分形。
图3 ND to NZ转换示意图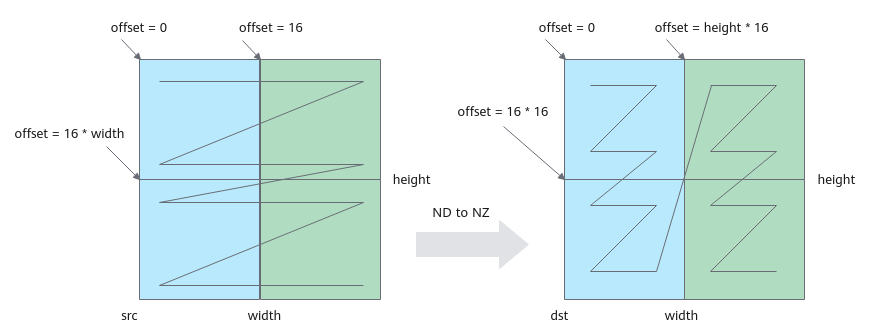
注意:上述ND到NZ的格式转换仅作为举例说明,开发者可根据实际情况选择合适的转换方式。
- 使用EnQue将a1Local、b1Local分别放入A1、B1的Queue中。
具体代码如下:
__aicore__ inline void CopyND2NZ(const LocalTensor<half>& dst, const GlobalTensor<half>& src, const uint16_t height, const uint16_t width) { for (int i = 0; i < width / 16; ++i) { int srcOffset = i * 16; int dstOffset = i * 16 * height; DataCopy(dst[dstOffset], src[srcOffset], { height, 1, uint16_t(width / 16 - 1), 0 }); } } __aicore__ inline void CopyIn() { LocalTensor<half> a1Local = inQueueA1.AllocTensor<half>(); LocalTensor<half> b1Local = inQueueB1.AllocTensor<half>(); CopyND2NZ(a1Local, aGM, m, k); CopyND2NZ(b1Local, bGM, k, n); inQueueA1.EnQue(a1Local); inQueueB1.EnQue(b1Local); } - Stage2:SplitA函数实现。
- 使用DeQue从A1的Queue中取出a1Local。
- 使用AllocTensor从A2的Queue中申请a2Local。
- 使用LoadData将矩阵a搬运到A2,同时将a矩阵从NZ格式转换为ZZ格式。
搬运及格式转换示意图如下:图中k为32,占kBlocks(k/16=2)个分形,m为32,占mBlocks(m/16=2)个分形,一共搬运4个16*16分形。本示例中,调用一次LoadData接口完成两个16*16分形的搬运,循环调用两次LoadData。第一次循环搬运蓝色部分两个分形,第二次循环搬运绿色部分两个分形。
单次循环中LoadData(本样例中要完成2个分形的搬运,蓝色部分或者绿色部分)的参数设置如下:- repeatTimes表示数据处理的迭代次数,因为LoadData每个迭代处理一个分形,所以也可以理解为待搬运分形的个数。本样例中即为k轴方向的分形个数,设置为kBlocks,表示搬运kBlocks个分形。
- srcStride表示,相邻迭代间源操作数分形首地址之间的间隔,以搬运蓝色部分分形为例:下图中左侧源操作数矩阵,第一个蓝色分形和第二个蓝色分形起始地址之间的间隔为mBlocks个分形,此处设置为mBlocks。
- dstStride使用默认值,目的矩阵两个分形连续存储。
- ifTranspose设置为false,每块分形搬运前搬运后都为Z格式,不使能转置。
- 每次循环迭代目的矩阵首地址偏移16*k,源矩阵首地址偏移16*16。
图4 NZ to ZZ格式转换示意图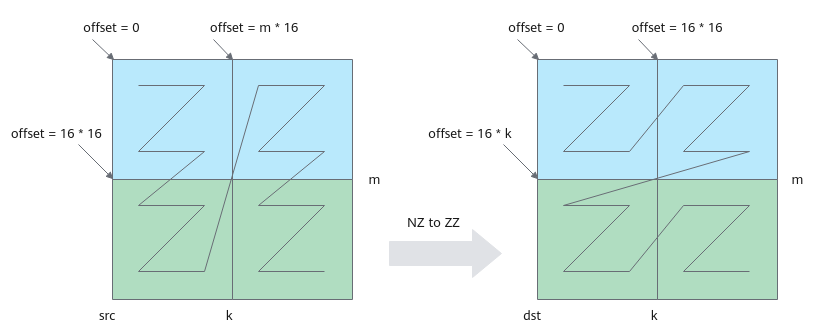
- 使用EnQue将计算结果a2Local放入到A2的Queue中。
具体代码如下:
__aicore__ inline void SplitA() { int srcOffset = 0; int dstOffset = 0; LocalTensor<half> a1Local = inQueueA1.DeQue<half>(); LocalTensor<half> a2Local = inQueueA2.AllocTensor<half>(); // transform nz to zz for (int i = 0; i < mBlocks; ++i) { LoadData2dParams loadDataParams; loadDataParams.repeatTimes = kBlocks; loadDataParams.srcStride = mBlocks; loadDataParams.ifTranspose = false; LoadData(a2Local[dstOffset], a1Local[srcOffset], loadDataParams); srcOffset += 16 * 16; dstOffset += k * 16; } inQueueA2.EnQue<half>(a2Local); inQueueA1.FreeTensor(a1Local); }
- Stage2:SplitB函数实现。
- SplitB需要传入两个参数:使用DeQue从B1的Queue中取出的b1Local和循环迭代变量index。
- 使用AllocTensor从B2的Queue中申请b2Local。
- 使用LoadData将b矩阵搬运到B2,同时从NZ格式转换为ZN格式。
搬运及格式转换示意图如下:图中k为32,占kBlocks(k/16=2)个分形,n为32,占nBlocks(n/16=2)个分形,一共搬运4个16*16分形。本示例中,调用一次LoadData接口完成两个16*16分形的搬运,循环调用两次LoadData。第一次循环搬运蓝色部分两个分形,第二次循环搬运绿色部分两个分形。
单次循环中LoadData(本样例中要完成2个分形的搬运,蓝色部分或者绿色部分)的参数设置如下:- repeatTimes表示数据处理的迭代次数,因为LoadData每个迭代处理一个分形,所以也可以理解为待搬运分形的个数。本样例中即为k轴方向的分形个数,设置为kBlocks,表示搬运kBlocks个分形。
- srcStride相邻迭代间源操作数分形首地址之间的间隔,以搬运蓝色部分分形为例:下图中左侧源操作数矩阵,第一个蓝色分形和第二个蓝色分形起始地址之间的间隔为1个分形,此处设置为1,源矩阵两个分形连续存储。
- dstStride使用默认值,目的矩阵两个分形连续存储。
- ifTranspose设置为true,每块分形搬运前为Z格式,搬运后需要为N格式,需要使能转置。
- 每次循环迭代,源矩阵首地址需要偏移bSize/2。
图5 NZ to ZN格式转换示意图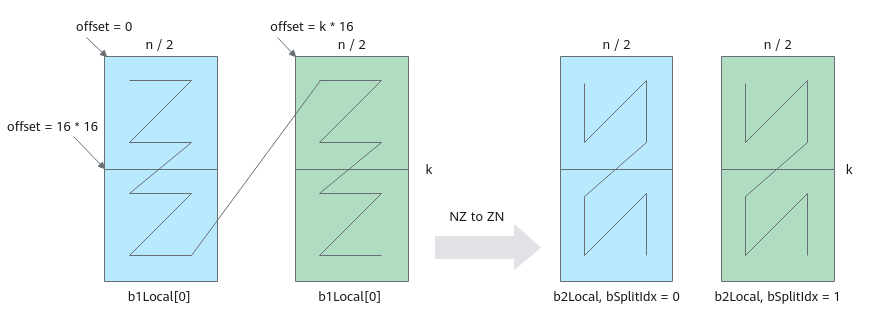
- 使用EnQue将计算结果b2Local放入到B2的Queue中。
具体代码如下:
__aicore__ inline void SplitB(const LocalTensor<half>& b1Local, const int bSplitIdx) { LocalTensor<half> b2Local = inQueueB2.AllocTensor<half>(); // transform nz to zn LoadData2dParams loadDataParams; loadDataParams.repeatTimes = kBlocks; loadDataParams.srcStride = 1; loadDataParams.ifTranspose = true; LoadData(b2Local, b1Local[bSplitIdx * bSize / 2], loadDataParams); inQueueB2.EnQue<half>(b2Local); } - Stage3:Compute函数实现,完成核心的矩阵计算功能。
- Compute函数需要传入参数a2Local,a2Local从A2的Queue中使用DeQue取出。
- 使用AllocTensor从CO1的Queue中申请c1Local。
- 使用DeQue从B2中取出b2Local。
- 使用Ascend C接口Mmad完成矩阵乘计算。
- 使用EnQue将计算结果c1Local放入到CO1的Queue中。
具体代码如下:
__aicore__ inline void Compute(const LocalTensor<half>& a2Local) { LocalTensor<half> b2Local = inQueueB2.DeQue<half>(); LocalTensor<float> c1Local = outQueueCO1.AllocTensor<float>(); Mmad(c1Local, a2Local, b2Local, { m, uint16_t(n / 2), k, 0, false, true }); outQueueCO1.EnQue<float>(c1Local); inQueueB2.FreeTensor(b2Local); } - Stage4:Aggregate函数实现,完成数据汇聚操作。
- Aggregate需要传入两个参数:使用AllocTensor从CO2的Queue中申请的c2Local和循环迭代变量index。
- 使用DeQue从CO1中取出c1Local。
- 使用DataCopy将结果矩阵从CO1搬运到CO2。
DataCopy参数设置如下:
- blockCount设置为1,blockLen设置为2,连续搬运两个分形,无需格式转换。
- blockMode设置为BlockMode::BLOCK_MODE_MATRIX,表示需要按分形搬运。
- c2Local首地址偏移量设置为index * cSize / 2。
具体代码如下:
__aicore__ inline void Aggregate(const LocalTensor<float>& c2Local, const int bSplitIdx) { LocalTensor<float> c1Local = outQueueCO1.DeQue<float>(); DataCopyParams dataCopyParams; dataCopyParams.blockCount = 1; dataCopyParams.blockLen = 2; DataCopyEnhancedParams enhancedParams; enhancedParams.blockMode = BlockMode::BLOCK_MODE_MATRIX; DataCopy(c2Local[bSplitIdx * cSize / 2], c1Local, dataCopyParams, enhancedParams); outQueueCO1.FreeTensor(c1Local); } - Stage5:CopyOut函数实现。
- 使用DeQue从CO2中取出c2Local。
- 使用DataCopy将结果矩阵从CO2搬运到Global Memory,同时需要将格式从NZ转换为ND。
每次循环移动一个分形,搬运m*16个数。DataCopy参数说明如下:
- blockCount设置为m,共搬运m次。
- blockLen设置为2,DataCopy指令一次搬运16个数,共2个block。
- srcStride设置为0,每两次搬运间没有间隙。
- dstStride设置为(nBlocks - 1) * 2,每两次搬运间隔2个block。
- 每次循环迭代,目的矩阵偏移16,源矩阵偏移m*16。
格式转换示意图如下,第一次循环搬运蓝色部分数据,第二次循环搬运绿色部分数据。
图6 NZ to ND格式转换示意图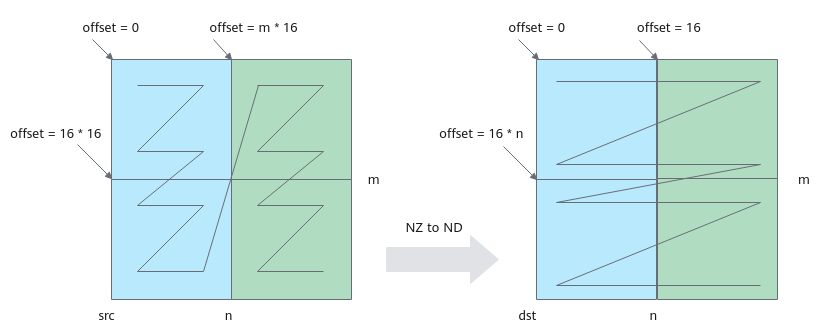
具体代码如下:
__aicore__ inline void CopyOut() { LocalTensor<float> c2Local = outQueueCO2.DeQue<float>(); // transform nz to nd for (int i = 0; i < nBlocks; ++i) { DataCopy(cGM[i * 16], c2Local[i * m * 16], { m, 2, 0, uint16_t((nBlocks - 1) * 2) }); } outQueueCO2.FreeTensor(c2Local); }