
本节介绍的核函数运行验证功能,主要目的是帮助开发者快速的理解矢量编程的编程模型、熟悉矢量算子的开发和基础调用流程。所以本节仅提供简单的算子运行验证功能,不支持获取用户的workspace特性。
核函数即算子kernel程序开发完成后,即可编写host侧的核函数调用程序,实现从host侧的APP程序调用算子,进行运行验证。本节将会介绍CPU侧和NPU侧两种运行验证方法:
- CPU侧运行验证主要通过ICPU_RUN_KF CPU调测宏等CPU调测库提供的接口来完成;
- NPU侧运行验证主要通过使用<<<>>>内核调用符和AscendCL API提供的运行时接口来完成。
CPU侧和NPU侧的运行验证原理图如下:

您可以根据下文的介绍来完成基本的运行验证流程,流程中使用到接口的详细细节请参考:
- CPU调测库请参考调测接口。
- <<<>>>内核调用符使用方法请参考核函数调用。
- AscendCL API使用方法请参考AscendCL API参考。
基于NPU域算子的调用接口(<<<>>>内核调用符)编写的算子程序,通过毕昇编译器编译后运行,可以完成算子NPU域的运行验证;基于CPU域算子的调用接口(ICPU_RUN_KF CPU)编写的算子程序,通过标准的GCC编译器进行编译后运行,可以完成算子CPU域的运行验证。
CPU侧的运行程序,通过GDB通用调试工具进行单步调试,精准验证程序执行流程是否符合预期。如果您想进一步了解CPU侧调试的具体内容,可在完成本节内容的学习后参考CPU域调试。
创建代码目录
您可以单击LINK,获取核函数开发和运行验证的完整样例。
代码目录如下:
Add |-- input // 存放脚本生成的输入数据目录 |-- output // 存放算子运行输出数据和真值数据的目录 |-- CMakeLists.txt // 编译工程文件 |-- add_custom.cpp // 算子kernel实现 |-- scripts | ├── gen_data.py // 输入数据和真值数据生成脚本文件 | ├── verify_result.py // 验证输出数据和真值数据是否一致的验证脚本 |-- cmake // 编译工程文件 |-- data_utils.h // 数据读入写出函数 |-- main.cpp // 主函数,调用算子的应用程序,含CPU域及NPU域调用 |-- run.sh // 编译运行算子的脚本
在进行算子调用前,请确保已经参考矢量编程完成了Ascend C算子实现文件的编写,本样例中为add_custom.cpp文件。除此之外,还需要特别关注以下文件,需要根据自己实际的使用场景进行修改。
- 调用算子的应用程序:main.cpp。
- 输入数据和真值数据生成脚本文件:gen_data.py;验证输出数据和真值数据是否一致的验证脚本:verify_result.py。
- 编译运行算子的脚本:run.sh。
算子调用应用程序
下面代码以固定shape的add_custom算子为例,介绍算子核函数调用的应用程序main.cpp如何编写。您在实现自己的应用程序时,需要关注由于算子核函数不同带来的修改,包括算子核函数名,入参出参的不同等,合理安排相应的内存分配、内存拷贝和文件读写等,相关API的调用方式直接复用即可。
- 应用程序框架编写。该应用程序通过__CCE_KT_TEST__ 宏区分代码逻辑运行于CPU侧还是NPU侧。
#include "data_utils.h" #ifndef __CCE_KT_TEST__ #include "acl/acl.h" extern void add_custom_do(uint32_t coreDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z); #else #include "tikicpulib.h" extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z); #endif int32_t main(int32_t argc, char* argv[]) { size_t inputByteSize = 8 * 2048 * sizeof(uint16_t); // uint16_t represent half size_t outputByteSize = 8 * 2048 * sizeof(uint16_t); // uint16_t represent half uint32_t blockDim = 8; #ifdef __CCE_KT_TEST__ // 用于CPU调试的调用程序 #else // NPU侧运行算子的调用程序 #endif return 0; } - CPU侧运行验证。完成算子核函数CPU侧运行验证的步骤如下:
图2 CPU侧运行验证步骤
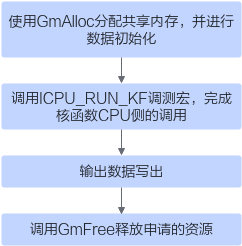
// 使用GmAlloc分配共享内存,并进行数据初始化 uint8_t* x = (uint8_t*)AscendC::GmAlloc(inputByteSize); uint8_t* y = (uint8_t*)AscendC::GmAlloc(inputByteSize); uint8_t* z = (uint8_t*)AscendC::GmAlloc(outputByteSize); ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize); ReadFile("./input/input_y.bin", inputByteSize, y, inputByteSize); // 矢量算子需要设置内核模式为AIV模式 AscendC::SetKernelMode(KernelMode::AIV_MODE); // 调用ICPU_RUN_KF调测宏,完成核函数CPU侧的调用 ICPU_RUN_KF(add_custom, blockDim, x, y, z); // 输出数据写出 WriteFile("./output/output_z.bin", z, outputByteSize); // 调用GmFree释放申请的资源 AscendC::GmFree((void *)x); AscendC::GmFree((void *)y); AscendC::GmFree((void *)z);
- NPU侧运行验证。完成算子核函数NPU侧运行验证的步骤如下:
图3 NPU侧运行验证步骤

// AscendCL初始化 CHECK_ACL(aclInit(nullptr)); // 运行管理资源申请 aclrtContext context; int32_t deviceId = 0; CHECK_ACL(aclrtSetDevice(deviceId)); CHECK_ACL(aclrtCreateContext(&context, deviceId)); aclrtStream stream = nullptr; CHECK_ACL(aclrtCreateStream(&stream)); // 分配Host内存 uint8_t *xHost, *yHost, *zHost; uint8_t *xDevice, *yDevice, *zDevice; CHECK_ACL(aclrtMallocHost((void**)(&xHost), inputByteSize)); CHECK_ACL(aclrtMallocHost((void**)(&yHost), inputByteSize)); CHECK_ACL(aclrtMallocHost((void**)(&zHost), outputByteSize)); // 分配Device内存 CHECK_ACL(aclrtMalloc((void**)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST)); CHECK_ACL(aclrtMalloc((void**)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST)); CHECK_ACL(aclrtMalloc((void**)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST)); // Host内存初始化 ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize); ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize); CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE)); CHECK_ACL(aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE)); // 用内核调用符<<<>>>调用核函数完成指定的运算,add_custom_do中封装了<<<>>>调用 add_custom_do(blockDim, nullptr, stream, xDevice, yDevice, zDevice); CHECK_ACL(aclrtSynchronizeStream(stream)); // 将Device上的运算结果拷贝回Host CHECK_ACL(aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST)); WriteFile("./output/output_z.bin", zHost, outputByteSize); // 释放申请的资源 CHECK_ACL(aclrtFree(xDevice)); CHECK_ACL(aclrtFree(yDevice)); CHECK_ACL(aclrtFree(zDevice)); CHECK_ACL(aclrtFreeHost(xHost)); CHECK_ACL(aclrtFreeHost(yHost)); CHECK_ACL(aclrtFreeHost(zHost)); CHECK_ACL(aclrtDestroyStream(stream)); CHECK_ACL(aclrtDestroyContext(context)); CHECK_ACL(aclrtResetDevice(deviceId)); CHECK_ACL(aclFinalize());
输入数据和真值数据生成以及验证脚本文件
以固定shape的add_custom算子为例,输入数据和真值数据生成的脚本样例如下:根据算子的输入输出编写脚本,生成输入数据和真值数据。
#!/usr/bin/python3
# -*- coding:utf-8 -*-
# Copyright 2022-2023 Huawei Technologies Co., Ltd
import numpy as np
def gen_golden_data_simple():
input_x = np.random.uniform(-100, 100, [8, 2048]).astype(np.float16)
input_y = np.random.uniform(-100, 100, [8, 2048]).astype(np.float16)
golden = (input_x + input_y).astype(np.float16)
input_x.tofile("./input/input_x.bin")
input_y.tofile("./input/input_y.bin")
golden.tofile("./output/golden.bin")
if __name__ == "__main__":
gen_golden_data_simple()
验证输出数据和真值数据是否一致的验证脚本样例如下:当前使用numpy接口计算了输出数据和真值数据的绝对误差和相对误差,误差在容忍偏差范围内,视为精度符合要求,输出"test pass"字样。
import os
import sys
import numpy as np
loss = 1e-3 # 容忍偏差,一般fp16要求绝对误差和相对误差均不超过千分之一
minimum = 10e-10
def verify_result(real_result, golden):
real_result = np.fromfile(real_result, dtype=np.float16) # 从bin文件读取实际运算结果
golden = np.fromfile(golden, dtype=np.float16) # 从bin文件读取预期运算结果
result = np.abs(real_result - golden) # 计算运算结果和预期结果偏差
deno = np.maximum(np.abs(real_result), np.abs(golden)) # 获取最大值并组成新数组
result_atol = np.less_equal(result, loss) # 计算绝对误差
result_rtol = np.less_equal(result / np.add(deno, minimum), loss) # 计算相对误差
if not result_rtol.all() and not result_atol.all():
if np.sum(result_rtol == False) > real_result.size * loss and np.sum(result_atol == False) > real_result.size * loss:
print("[ERROR] result error")
return False
print("test pass")
return True
if __name__ == '__main__':
verify_result(sys.argv[1],sys.argv[2])
一键式编译运行脚本
您可以基于样例工程中提供的一键式编译运行脚本进行快速编译,并在CPU侧和NPU侧执行Ascend C算子。一键式编译运行脚本主要完成以下功能:
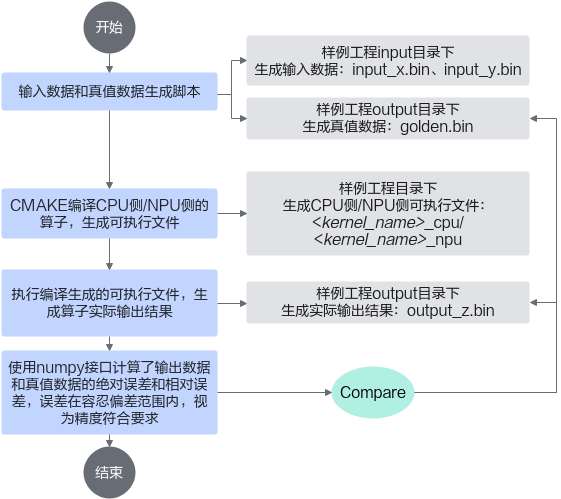
样例中提供的一键式编译运行脚本并不能适用于所有的算子运行验证场景,使用时请根据实际情况进行修改。
- 根据Ascend C算子的算法原理的不同,自行实现输入和真值数据的生成脚本。
运行验证
完成上述文件的编写后,可以执行一键式编译运行脚本,编译和运行应用程序。
执行脚本前需要配置环境变量ASCEND_HOME_DIR,配置为CANN软件的安装路径,示例如下,请根据实际安装路径进行修改:
export ASCEND_HOME_DIR=$HOME/Ascend/ascend-toolkit/latest
bash run.sh <soc_version> <run_mode>
参数名 |
参数介绍 |
|---|---|
<soc_version> |
算子运行的AI处理器型号。
说明:
|
<run_mode> |
表明算子以cpu模式或npu模式运行。 取值为cpu或npu_onboard。 |
如下图所示,脚本执行完毕会出现如下打印,输出"test pass"字样表示算子精度符合要求。
INFO: execute op on ONBOARD succeed! test pass