说明
- 本节涉及的.json文件、目录等名称均为举例,请根据实际环境替换。其中,-out指定的结果存放路径,需确保操作用户具有读写权限。
- 基于相同模型(开/关融合)、昇腾AI处理器运行生成的dump数据进行单算子精度比对时,需同时指定-f和-cf参数或同时不指定这两个参数。
操作步骤
本节以非量化昇腾AI处理器运行生成的dump数据与非量化Caffe模型npy数据比对为例进行介绍,下文中参数说明均以该示例介绍,请根据您的实际情况进行替换。
- 登录CANN工具安装环境。
- 生成json文件。
atc --mode=1 --om=$HOME/data/resnet50.om --json=$HOME/data/resnet50.json
- 进入${INSTALL_DIR}/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。若安装的Ascend-cann-toolkit软件包,以root安装举例,则安装后文件存储路径为:/usr/local/Ascend/ascend-toolkit/latest。
- 执行单算子比对默认配置比对。

由于dump和npy比对数据文件是由多个文件组成,故下文操作步骤中-m和-g参数须指定数据文件所在的父目录。如:$HOME/MyApp/resnet50,其中resnet50文件夹下直接保存比对数据文件。
目录结构示例如下:
1 2 3 4 5 6
root@xxx:$HOME/MyApp/resnet50# tree . ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul_1.24.1614717261785536 ├── BatchMatMul.bert_encoder_layer_0_attention_self_MatMul.21.1614717261768864 ├── BatchMatMul.bert_encoder_layer_10_attention_self_MatMul_1.235.1614717263664916 #仅为示例,此处省略剩余文件名。
python3 msaccucmp.py compare -m $HOME/MyApp_mind/resnet50 -g $HOME/Standard_caffe/resnet50 -f $HOME/data/resnet50.json -out $HOME/result -op pool5 -i 0
各参数详细介绍请参见命令格式说明。
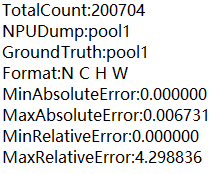
单算子比对概要结果存放在{op_name}_input_{index}_summary.txt或{op_name}_output_{index}_summary.txt文件中,各参数说明如下:表1 单算子比对概要结果的参数说明 参数
说明
TotalCount
该算子的dump数据的data个数。
NPUDump
表示My Output模型算子名。
GroundTruth
表示Ground Truth模型的算子名。
Format
数据格式。
MinAbsoluteError
绝对误差的最小值。
MaxAbsoluteError
绝对误差的最大值。
MinRelativeError
相对误差的最小值。
MaxRelativeError
相对误差的最大值。
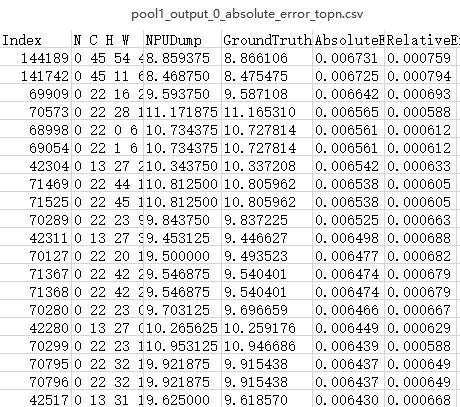
单算子比对完整结果存放在{op_name}_input_{index}_{file_index}.csv或{op_name}_output_{index}_{file_index}.csv文件中,每个文件最多记录100万条数据。配置--ignore_single_op_result参数时不生成此结果。比对结果各列参数说明如表2。
表2 单算子完整比对结果参数说明 参数
说明
N C H W
数据的坐标点。
NPUDump
My Output模型的算子dump值。
GroundTruth
Ground Truth模型的算子dump值。
RelativeError
相对误差,AbsoluteError值除以Ground Truth模型算子的dump值比对出来的结果。当Ground Truth算子的dump值为0时,该处显示为“-”。
AbsoluteError
绝对误差,My Output模型算子的dump值减Ground Truth模型算子的dump值取绝对值比对出来的结果。
若已知输出结果文件数据量较大,可以通过配置参数来减少输出结果的数据量。根据结果文件说明选择合适的比对场景,执行6,以便快速识别算子存在精度问题的位置(输入、输出、坐标点)。
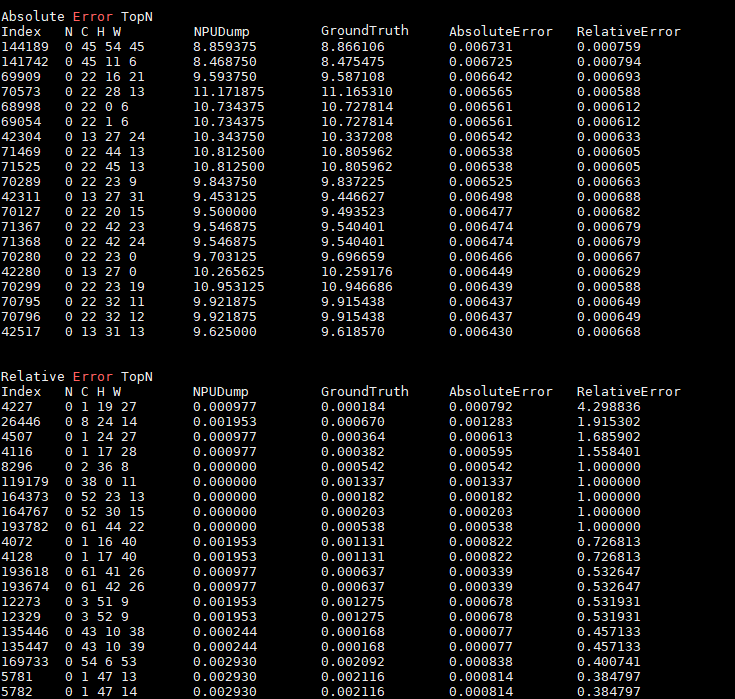
- (可选)执行单算子比对仅比对TopN条数据。
python3 msaccucmp.py compare -m $HOME/MyApp_mind/resnet50 -g $HOME/Standard_caffe/resnet50 -f $HOME/data/resnet50.json -out $HOME/result -op pool1 -o 0 -n 20
各参数详细介绍请参见命令格式说明。
比对完成后的打屏展示结果如图3所示。
- 比对结果分析。
输出比对结果文件后,首先将绝对误差或相对误差由大到小排序,找出TopN条数据,用户可以基于自己的评估指标判断该算子精度是否达标。如果不满足精度要求,可以将当前测评数据交由算子开发人员进行算子内部逻辑分析。
绝对误差或相对误差的值越趋近于0表示精度越高,但实际算子需要满足的精度根据用户实际需求判断。