背景与挑战
与Ulysses并驾齐驱,Ring Attention长序列并行技术同样聚焦于解决长序列训练中的核心难题。
解决方案
Ring Attention长序列并行技术,通过引入环形注意力机制,有效解决了传统并行方法在处理长序列时面临的内存瓶颈、计算效率低下及通信开销大等问题。该技术不仅提升了系统对长序列数据的处理能力,还显著优化了资源利用效率与整体性能。
Ring Attention借鉴了分块Softmax原理,在不需要获取整个序列的完整矩阵情况下进行分块attention计算。因此提出以分块方式执行自注意力和前馈网络计算,跨多个设备分布序列维度。具体地,该方法在进程之间构建注意力计算块的环状通信结构(Ring),每个进程具有一个切分后的本地QKV块。在计算完本地的attention后,通过向后发送和向前获取KV块,遍历进程设备环,以逐块的方式进行注意力和前馈网络计算。同时,本地的attention计算和KV块的通信理想情况下可以互相掩盖,从而消除了额外引入的通信开销。另外该方案在计算attention的过程中全程不需要数据拼接,支持的序列长度理论上可以无限拓展。
在原始Ring Attention基础上设计了新的计算块切分方案,解决序列维度扩展问题。具体细节可参见文献Ring Attention with Blockwise Transformers for Near-Infinite Context。
使用场景
当使用GPT类模型进行训练,同时数据进MoE层时实际序列长度8K以上。
不同于Ulysses方案,该方案不需要确保head_size被cp_size整除。
可兼容Flash Attention,目前已默认开启Flash Attention。
如果想要使得计算和通信可以互相掩盖,理论上需要确保每个计算块分到的序列长度满足以下要求:
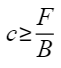
其中F表示每个Device的FLOPS,B表示每个Device间的带宽。在实践中,需要确保每个计算块分到的序列长度足够大,才能较好掩盖。
使用方法
重要参数 |
参数说明 |
|---|---|
--context-parallel-size [int] |
必选,设置长序列并行大小,默认为1,根据用户需求配置。 |
--seq-length [int] |
输入序列的长度。 |
--use-cp-send-recv-overlap |
建议开启,开启后支持send receive overlap功能,减少通信损耗。 |
--attention-mask-type [general/causal] |
可选,设置Mask计算类型。
|
--context-parallel-algo megatron_cp_algo |
可选,设置长序列并行算法。
|

--group-query-attention开启时推荐使能Ring Attention长序列并行。
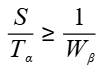
使用效果
利用多个计算设备对输入序列进行并行切分,降低单设备的内存消耗,相比不开启序列并行单步耗时增加,相比重计算计算效率提升。