背景与挑战
Megatron重计算技术是优化内存使用的关键手段,通过避免冗余数据存储以减少内存占用。然而,传统的重计算策略往往预设固定模式,未能动态响应实际内存需求,限制了内存资源的高效利用。
解决方案
为了实现NPU内存资源的最大化利用并显著提升模型训练效率,我们引入了自适应选择重计算特性。这一创新机制能够智能调整训练过程中的内存分配,依据当前内存状况动态选择最佳的重计算策略。
自适应选择重计算特性由三大关键组件构成:
- 重计算策略搜索:根据实时内存状态,智能筛选最适宜的重计算方案。
- SwapManager功能集成:确保关键张量能在CPU与NPU间无缝迁移,预防因内存溢出而导致的训练中断。
- 内存管理:适配Ascend Extension for PyTorch的NPU PluggableAllocator接口,实现OOM(Out of Memory)异常的及时响应与处理。
重计算策略搜索依赖SwapManager功能,及时将tensor换到CPU,避免OOM导致训练中断。自动选择重计算策略流程如下图所示。
图1 自动选择重计算策略流程
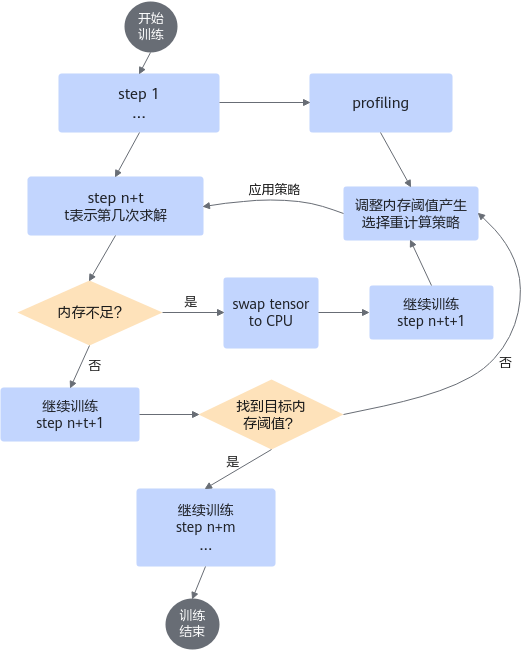
图2 SwapManager管理流程

使用场景
特别适用于训练阶段,尤其是当全重计算模式下NPU内存仍有较大剩余空间,想进行更细粒度的重计算以追求更优训练性能的场景。
使用方法
- 在训练脚本中配置如下参数启用该特性:
--adaptive-recompute-device-swap
- 可选参数
- 指定自适应选择重计算策略的训练内存大小,单位为MB。
--adaptive-recompute-device-size N
内存大于0为有效内存,最大内存限度为Device最大内存。在该范围内自适应重计算才可以进行最优策略搜寻,当配值不在有效内存范围内,将读取到Device最大内存信息作为默认值。需要注意的是内存设定较小时,性能会与全重计算一致。如遇内存溢出(OOM,Out of Memory)情况,系统将提示相应错误。此时,用户需重新设定一个更为合理的内存分配值,进而重启模型训练流程。对于寻求性能最优化的高级用户,我们推荐采用二分查找算法(Binary Search Algorithm)来精确确定最优内存配置。通过迭代缩小测试范围,逐步逼近最适宜的内存阈值,从而在保障训练稳定性的同时,最大化利用可用资源。然而,鉴于该方法对用户的专业知识有一定要求,初学者或不熟悉此特性的用户应谨慎操作,避免不当配置带来的训练中断风险或效率低下。
- 设置停止收集训练信息的步数,默认为10步,推荐值大于5。
--adaptive-recompute-profiling-step N
非标准设置(小于5或者大于总步数的十分之一)会产生警告信息,不影响训练进程及结果,不会对性能和精度有影响。
- 指定自适应选择重计算策略的训练内存大小,单位为MB。

- 自适应选择重计算暂只适用于--use-legacy-models。
- 当前自适应选择性重计算与全重计算、选择重计算、重计算流水独立调度、激活函数重计算、预取特性swap-attention等特性均不兼容。
- 由于自适应选择重计算特性修改了内存管理模块,打开会存在冲突,MindSpeed进行了assert判断。
- 自适应重计算通过实现自身的allocator对OOM进行拦截,该allocator支持环境变量PYTORCH_NPU_ALLOC_CONF,详情可参见《环境变量参考》中的“PYTORCH_NPU_ALLOC_CONF”章节。
使用效果
相较于全重计算模式,LLaMA2-7B模型训练场景下性能提升10%以上,显著优化了训练效率与资源利用。