背景与挑战
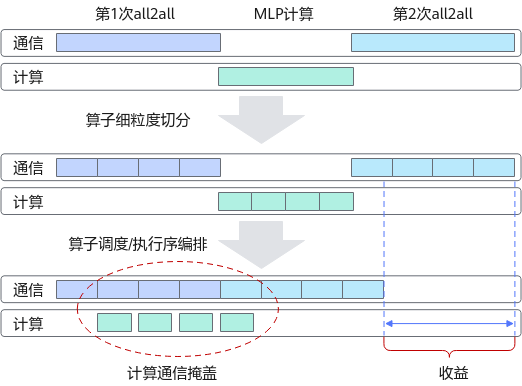
大模型训练过程中,通信和计算往往存在依赖关系,这样的串行执行顺序会造成计算和通信流存在一定程度的空闲等待时间,导致执行效率较低。
解决方案
对通信和计算算子做更细粒度的切分,保证细粒度间的计算和通信任务不存在依赖关系,是创造并行执行任务的前提。
再对算子调度/执行顺序进行编排,实现计算和通信的并行执行,在计算过程能掩盖中间部分的通信过程。
使用场景
- 专家间的计算通信流水
当local_experts数量大于等于2时,可以考虑使用专家间的计算通信流水来实现通信隐藏的目的。这种方式适用于每个设备上有多个专家的情况,通过将计算任务分配给不同的专家,并在计算过程中重叠执行通信操作,以减少等待时间。
- 多副本间的计算通信流水
当local_experts等于1时,即每个设备上只有一个专家(ep = num_expert),可以通过多副本间的计算通信流水来实现通信隐藏的目的。在这种情况下,同一阶段的不同副本之间的通信被设计成与计算并行执行,从而避免了通信成为瓶颈。
- 多流水线支持
为了进一步规避集合通信上可能出现的链路冲突,可开启多流水线选项--pipe-experts-multi-stream。这一机制允许同时处理多个通信流,从而提高了系统的灵活性和鲁棒性。
使用方法
--moe-model-type deepspeed_moe --use-pipe-experts
- 多流水线
--pipe-experts-multi-stream
开启后,能够保证ep的alltoall通信和tp的allgather/reduce-scatter之间串行执行,避免集合通信出现链路冲突。
- 多副本
--pipe-experts-multi-data N # N表示使用N份副本
开启后,能将输入数据切分为多个副本,将不同副本间的计算和通信类比为多个experts的计算和通信。

启用该特性时需注意以下几点:
- 在开启--pipe-experts-multi-data时,若N过大,导致输入数据切分过细,会引入多余的cast和add算子,导致额外的开销,引起性能恶化。
- 8机:当num_local_experts = 1时,推荐开启--pipe-experts-multi-data 4来获得最佳性能;当num_local_experts大于1时,不推荐开启“多副本”。
- 单机:当num_local_experts为1或2时,推荐开启--pipe-experts-multi-data 2来获得最佳性能;当num_local_experts为4及以上时,不推荐开启“多副本”。
- “多副本”特性主要被用来提供num_local_experts为1时无法进行experts间的细粒度切分的替代方案。虽然兼容num_local_experts大于1的场景,开启后可以进一步提高计算通信掩盖比例,但会新引入cast和add算子操作,当掩盖的收益不足以抵消新引入算子的拖慢时,可能会导致性能恶化。
- 在未开启--sequence-parallel(SP,序列并行)时,无法开启多流水线--pipe-experts-multi-stream。
使用效果
在特定配置下使用MLP通信隐藏特性,可以带来显著的性能改进。下表是基于实际测试数据的具体效果描述。
配置参数 |
参数值 |
|---|---|
world_size |
64 |
sequence_len |
128k |
num_layers |
4 |
recompute_granularity |
full |
hidden_size |
12288 |
moe_router_topk |
2 |
ep(专家并行度) |
4 |
tp(张量并行度) |
8 |
dp(数据并行度) |
2 |
cp(长序列并行度) |
4 |
pp(流水线并行度) |
1 |
sp(序列并行) |
True |
总体上,使用MLP通信隐藏特性后,通过减少通信时间、提高设备利用效率,在上述参数配置可以获得5%-6%的计算效率提升。