算力利用率指负载在集群上每秒消耗的实际算力占集群标称算力的比例。
标称算力是指硬件或设备在正常工作状态下的理论计算能力,通常以单位时间内能够完成的浮点运算次数(FLOPS)或整数运算次数(IOPS)来衡量。
对一个典型的GPT-like负载,其主要的浮点算力都由Transformer层和logit层中的矩阵乘(GEMMs)贡献。例如昇腾上一个典型的千亿大模型盘古中,99.3%以上的浮点算力都由fp16的矩阵乘贡献。
考虑一个具有I个transformer层的大模型负载,F表示一个iteration中负载消耗的算力。注意,F为真实FLOPs统计的lower bound。真实的计算过程中,负载还有少量的vector算力和padding带来的额外算力(占比极少)。
下面的计算公式,B代表Batch Size,s代表sequence length,I是transformer层的数量,h是hidden size,V是vocabulary size。
一个Amk * Xkn的矩阵乘法需要2mnk个浮点运算(乘加运算算两次)。Transformer层由一个注意力模块(attention)和一个2层前馈网络(FFN)组成。对于注意力模块,主要的贡献者是键(key)、查询(query)和值(value)的转换(6Bsh2次运算),注意力矩阵计算(2Bs2h次运算),对值进行注意力计算(2Bs2h次运算)和注意力后的线性投影(2Bsh2次运算)。前馈网络将隐藏大小增加到4h,再将其缩小回h。这需要16Bsh2个浮点运算。
将上面的这些加起来,每个transformer层的正向传递结果为24Bsh2 + 4Bs2h个FLOPs。反向传递需要两倍于此的FLOPs,因为我们需要计算相对于输入和权重张量的梯度。
此外,如果我们使用了激活重计算技术,这需要在反向传递之前进行额外的前向传递。因此,每个transformer层的总FLOP数为:

所以,考虑I层GPT负载一个iteration中GEMMs的FLOPs算力(前向计算+重计算+反向计算)为:
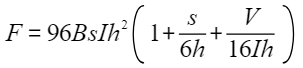
集群算力利用率的公式为:

其中,C为集群中每块AI处理器的标称算力,N为集群中AI处理器的个数,step_time为一个iteration的时间。
算力利用率可以衡量AI处理器算力的发挥程度,也可以衡量对负载和AI处理器的亲和优化。对于昇腾或GPU等重算力AI处理器,我们希望尽量多的算力都在CUBE/TensorCore上,如果Vector算力成为瓶颈,较少的算力花了较多的时间,此时step_time增加,算力利用率降低。所以,算力利用率可以反映实际的算力发挥情况,牵引软硬件栈的优化。同时,算力利用率和吞吐成正比关系,可以纵向反映性能问题。
影响算力利用率的因素是所有非矩阵运算花的时间,包括AICORE内部的数据搬运、VECTOR计算及卡间不可掩盖的通信时间等。