功能描述
算子功能:该FFN算子提供MoeFFN和FFN的计算功能。在没有专家分组(expert_tokens为空)时是FFN,有专家分组时是MoeFFN。
计算公式为:
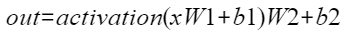
说明:激活层为geglu/swiglu/reglu时,性能使能需要满足门槛要求,即整网中FFN结构所对应的小算子中vector耗时30us且占比10%以上的用例方可尝试FFN融合算子;或在不知道小算子性能的情况下,尝试使能FFN,若性能劣化则不使能FFN。
接口原型
npu_ffn(Tensor x, Tensor weight1, Tensor weight2, str activation, *, int[]? expert_tokens=None, Tensor? bias1=None, Tensor? bias2=None, Tensor? scale=None, Tensor? offset=None, Tensor? deq_scale1=None, Tensor? deq_scale2=None, Tensor? antiquant_scale1=None, Tensor? antiquant_scale2=None, Tensor? antiquant_offset1=None, Tensor? antiquant_offset2=None, int? inner_precise=None, ScalarType? output_dtype=None) -> Tensor
参数说明
- x:Tensor类型,即输入参数中的x。公式中的输入x,数据类型支持FLOAT16、BFLOAT16、INT8,数据格式支持ND,支持输入的维度最少是2维[M, K1],最多是8维。
- weight1:Tensor类型,专家的权重数据,公式中的W1,数据类型支持FLOAT16、BFLOAT16、INT8,数据格式支持ND,输入在有/无专家时分别为[E, K1, N1]/[K1, N1]。
- weight2:Tensor类型,专家的权重数据,公式中的W2,数据类型支持FLOAT16、BFLOAT16、INT8,数据格式支持ND,输入在有/无专家时分别为[E, K2, N2]/[K2, N2]。

M表示token个数,对应transform中的BS(B(Batch)表示输入样本批量大小、S(Seq-Length)表示输入样本序列长度);K1表示第一组matmul的输入通道数,对应transform中的H(Head-Size)表示隐藏层的大小);N1表示第一组matmul的输出通道数;K2表示第二组matmul的输入通道数;N2表示第二组matmul的输出通道数,对应transform中的H;E表示有专家场景的专家数。
- expert_tokens:List类型,可选参数。代表各专家的token数,数据类型支持INT,数据格式支持ND,若不为空时可支持的最大长度为256个。
- bias1:Tensor类型,可选参数。权重数据修正值,公式中的b1,数据类型支持FLOAT16、FLOAT32、INT32,数据格式支持ND,输入在有/无专家时分别为[E, N1]/[N1]。
- bias2:Tensor类型,可选参数。权重数据修正值,公式中的b2,数据类型支持FLOAT16、FLOAT32、INT32,数据格式支持ND,输入在有/无专家时分别为[E, N2]/[N2]。
- activation:string类型,代表使用的激活函数,即输入参数中的activation。当前仅支持fastgelu/gelu/relu/silu/geglu/swiglu/reglu。
- scale:Tensor类型,可选参数,量化参数,量化缩放系数,数据类型支持FLOAT32,数据格式支持ND,per-tensor下输入在有/无专家时均为一维向量,输入元素个数在有/无专家时分别为[E]/[1];per-channel下输入在有/无专家时为二维向量/一维向量,输入元素个数在有/无专家时分别为[E, N1]/[N1]。
- offset:Tensor类型,可选参数,量化参数,量化偏移量,数据类型支持FLOAT32,数据格式支持ND,一维向量,输入元素个数在有/无专家时分别为[E]/[1]。
- deq_scale1:Tensor类型,可选参数,量化参数,第一组matmul的反量化缩放系数,数据类型支持INT64、FLOAT32、BFLOAT16,数据格式支持ND,输入在有/无专家时分别为[E, N1]/[N1]。
- deq_scale2:Tensor类型,可选参数,量化参数,第二组matmul的反量化缩放系数,数据类型支持INT64、FLOAT32、BFLOAT16,数据格式支持ND,输入在有/无专家时分别为[E, N2]/[N2]。
- antiquant_scale1:Tensor类型,可选参数,伪量化参数,第一组matmul的缩放系数,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND,per-channel下输入在有/无专家时分别为[E, N1]/[N1]。
- antiquant_scale2:Tensor类型,可选参数,伪量化参数,第二组matmul的缩放系数,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND,per-channel下输入在有/无专家时分别为[E, N2]/[N2]。
- antiquant_offset1:Tensor类型,可选参数,伪量化参数,第一组matmul的偏移量,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND,per-channel下输入在有/无专家时分别为[E, N1]/[N1]。
- antiquant_offset2:Tensor类型,可选参数,伪量化参数,第二组matmul的偏移量,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND,per-channel下输入在有/无专家时分别为[E, N2]/[N2]。
- inner_precise:int类型,可选参数,表示高精度或者高性能选择。数据类型支持INT64。该参数仅对FLOAT16生效,BFLOAT16和INT8不区分高精度和高性能。
- innerPrecise为0时,代表开启高精度模式,算子内部采用FLOAT32数据类型计算。
- innerPrecise为1时,代表高性能模式。
- output_dtype: ScalarType类型,可选参数,该参数只在量化场景生效,其他场景不生效。表示输出Tensor的数据类型,支持输入FLOAT16、BFLOAT16。默认值为None,代表输出Tensor数据类型为FLOAT16。
输出说明
一个Tensor类型的输出,公式中的输出y,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND,输出维度与x一致。
约束说明
- 有专家时,专家数据的总数需要与x的M保持一致。
- 激活层为geglu/swiglu/reglu时,仅支持无专家分组时的FLOAT16高性能场景(FLOAT16场景指类型为Tensor的必选参数数据类型都为FLOAT16的场景),且N1=2*K2。
- 激活层为gelu/fastgelu/relu/silu时,支持有专家或无专家分组的FLOAT16高精度及高性能场景,BFLOAT16场景,量化场景及伪量化场景,且N1=K2。
- 非量化场景不能输入量化参数和伪量化参数,量化场景不能输入伪量化参数,伪量化场景不能输入量化参数。
- 量化场景参数类型:x为INT8、weight为INT8、bias为INT32、scale为FLOAT32、offset为FLOAT32,其余参数类型根据y不同分两种情况:
- y为FLOAT16,deq_scale支持数据类型:UINT64、INT64、FLOAT32。
- y为BFLOAT16,deq_scale支持数据类型:BFLOAT16。
- 要求deq_scale1与deq_scale2的数据类型保持一致。
- 量化场景支持scale的per-channel模式参数类型:x为INT8、weight为INT8、bias为INT32、scale为FLOAT32、offset为FLOAT32,其余参数类型根据y不同分两种情况:
- y为FLOAT16,deqScale支持数据类型:UINT64、INT64。
- y为BFLOAT16,deqScale支持数据类型:BFLOAT16。
- 要求deq_scale1与deq_scale2的数据类型保持一致。
- 伪量化场景:
- 支持两种不同参数类型:
- y为FLOAT16、x为FLOAT16、bias为FLOAT16,antiquant_scale为FLOAT16、antiquant_offset为FLOAT16,weight支持数据类型INT8。
- y为BFLOAT16、x为BFLOAT16、bias为FLOAT32,antiquant_scale为BFLOAT16、antiquant_offset为BFLOAT16,weight支持数据类型INT8。
- 支持两种不同参数类型:
- inner_precise参数在BFLOAT16非量化场景,只能配置为0;FLOAT16非量化场景,可以配置为0或者1;量化或者伪量化场景,0和1都可配置,但是配置后不生效。
支持的PyTorch版本
- PyTorch 2.2
- PyTorch 2.1
- PyTorch 1.11.0
支持的型号
- Atlas A2 训练系列产品
调用示例
#单算子调用模式
import torch
import torch_npu
import logging
import os
cpu_x = torch.randn((1, 1280), device='npu', dtype=torch.float16)
cpu_weight1 = torch.randn(1280, 10240, device='npu', dtype=torch.float16)
cpu_weight2 = torch.randn(10240, 1280, device='npu', dtype=torch.float16)
activation = "fastgelu"
npu_out = torch_npu.npu_ffn(cpu_x.npu(), cpu_weight1.npu(), cpu_weight2.npu(), activation, inner_precise=1)
#torch api 入图模式
import torch
import torch_npu
import torchair as tng
from torchair.ge_concrete_graph import ge_apis as ge
from torchair.configs.compiler_config import CompilerConfig
import logging
from torchair.core.utils import logger
logger.setLevel(logging.DEBUG)
import os
os.environ["ENABLE_ACLNN"] = "true"
config = CompilerConfig()
config.debug.graph_dump.type = "pbtxt"
npu_backend = tng.get_npu_backend(compiler_config=config)
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x, weight1, weight2, activation, expert):
return torch_npu.npu_ffn(x, weight1, weight2, activation, expert_tokens=expert, inner_precise=1)
cpu_model = MyModel()
cpu_x = torch.randn((1954, 2560),device='npu',dtype=torch.float16)
cpu_weight1 = torch.randn((16, 2560, 5120),device='npu',dtype=torch.float16)
cpu_weight2 = torch.randn((16, 5120, 200),device='npu',dtype=torch.float16)
activation = "fastgelu"
expert = [227, 62, 78, 126, 178, 27, 122, 1, 19, 182, 166, 118, 66, 217, 122, 243]
model = cpu_model.npu()
model = torch.compile(cpu_model, backend=npu_backend, dynamic=True)
npu_out = model(cpu_x.npu(), cpu_weight1.npu(), cpu_weight2.npu(), activation, expert)