问题分析
在大规模模型训练中,张量并行虽能有效降低显存占用并加快训练速度,但其要求将模型各层分割为独立块,这在处理如LayerNorm和Dropout等操作时存在局限。尽管这些操作计算成本较低,但存储激活所需的冗余显存显著,为了解决这一问题,序列并行作为一种补充策略被引入,旨在分摊那些在张量并行中难以分割的显存和计算负担。
解决方案
序列并行策略在张量并行的基础上进一步发展,通过将输入数据的序列维度进行切分。
解决思路
每个计算设备仅需处理一部分的LayerNorm和Dropout等操作。具体而言,假设输入张量X的维度为s x b x h,通过序列维度切分后 ,各设备仅需处理对应的子序列,随后执行LayerNorm操作后结果为
,各设备仅需处理对应的子序列,随后执行LayerNorm操作后结果为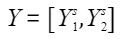 ,最终进行张量模型并行。
,最终进行张量模型并行。
图1 序列并行示意图

使用场景
序列并行技术适用于以下场景:
- 显存占用过高:即使采用了张量并行,显存占用仍接近或超出处理器显存限制。
- 计算资源优化:旨在进一步降低显存开销,提升训练速度。
使用方法
启用序列并行,需在训练脚本中加入以下参数配置:
--tensor-model-parallel-size N # 设置张量模型并行大小 --sequence-parallel # 开启序列并行
使用效果
通过序列并行策略,利用多设备协同作用,不仅有效降低了显存占用,还加速了训练进程。