背景与挑战
在面对大规模数据集的模型训练场景时,单一计算设备往往难以承载整个数据集的处理负荷,导致训练周期过长。为应对这一挑战,需将原始数据集进行有效分割,确保每台计算设备仅需处理数据集的一部分,从而实现训练效率的显著提升。
解决方案
数据并行策略通过将数据集划分为多个批次(Batch),并将其均匀分配至各个计算设备,使得每台设备仅负责处理特定批次的数据。
此方案确保了以下两点关键要素:
- 每一台计算设备上部署的模型结构与参数保持完全一致。
- 各设备处理的数据批次互不相同,确保了训练过程的并行性和效率。
该方案的整体思路如下:
- 模型复制:在每个计算设备上存储完整的模型副本。
- 数据分割:原始数据集被细分为若干个批次,然后均匀分配至各个计算设备,确保负载均衡。
- 梯度同步:完成前向计算并获取局部梯度后,通过All-Reduce操作汇集所有设备的梯度,计算平均值,再将结果广播回各设备,以此维持全局参数的一致性。
使用场景
数据并行技术适用于以下场景:
- 大规模数据集:当训练数据集规模庞大,单一设备难以在合理时间内完成处理。
- 计算资源充裕:拥有足够数量的计算设备,能够支撑多份完整模型的存储与并行训练,从而有效缩短训练周期,降低单设备计算负担。
使用方法
数据并行的启用与参数配置主要依赖于以下指标:
- 总设备数(World Size):参与并行训练的所有计算设备总数。
- 模型并行数(Tensor Model Parallel Size):模型权重的并行分割数。
- 流水线并行数(Pipeline Model Parallel Size):模型架构的流水线并行度。
- 长序列并行数(Context Parallel Size):针对长序列数据处理的并行策略。
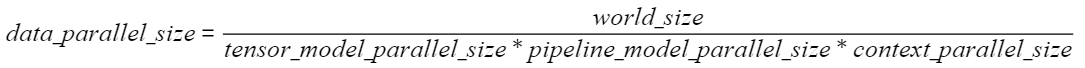

- 模型总层数需被流水线并行数整除。
- global_batch_size需被data_parallel_size整除。
使用效果
数据并行根据其他并行策略的设置自行计算。数据并行处理方式能够显著缩短训练周期,尤其是在处理高维特征和大规模数据集时,能够提高硬件资源的利用率。数据并行架构具备良好的横向扩展性,能够随着计算资源的增加而线性提升性能,易于在不同规模的集群环境中部署与调整,满足不同阶段的计算需求。