背景与挑战
在当前大模型训练场景中,混合精度训练已成为标准实践,其中涉及计算权重与状态权重的持续存储。然而,这两类权重的生命周期并不重叠,这意味着它们可以共享内存空间,而非各自独立占用。通过数值变换技巧,可以消除这一冗余,实现资源的有效利用。
现有的大模型训练框架中,重计算和反向计算是绑定在一起调度的,这严重限制了重计算的灵活性。在某些场景下,会限制重计算在模型性能上的优化。
比如在模型中存在某个流程:
- 前向:gelu激活函数模块->后续模块A
- 反向:后续模块A的反向(需要gelu输出的激活值)->gelu反向(与重计算绑定)
gelu激活函数会产生大量的数据,但本身计算量很小。此时进行激活函数的重计算可以在性能劣化极少的代价下,减少内存占用。 但在现有重计算框架下,如果对gelu激活函数模块做重计算,并不能节省gelu函数的输出。这是因为在反向时,模块A所需要的gelu输出的激活值,会早于gelu激活函数模块的重计算流程,所以前向必须保留激活函数的输出,导致激活函数的输出并不能节省下来。
解决方案
激活函数重计算重新实现了一套重计算框架,可以将重计算灵活地插入到反向计算之前的任意位置,即如下流程:
反向(新框架):gelu函数重计算->后续模块A的反向
此时,gelu函数的输出已经早于模块A的反向,在前向时就无须保留gelu函数的输出值。
设计一种传入模块函数进行重计算的机制,在合适的时机,丢弃重计算模块输出的物理存储,保留逻辑视图。在反向时,在合适的时机,利用register_hook插入重计算流程。利用传入的函数重新进行计算,得到结果。
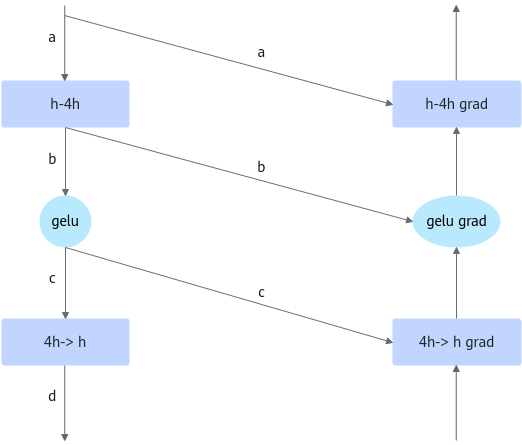
比如gelu在MLP中的位置如图1所示。反向计算需要前向产生的a、b、c、d。其中b和c的shape为(batch, seq , 4hidden_size),gelu为激活函数,其计算较少,故可将tensor c释放掉,反向在4h->h反向前重新计算。

在前向4h->h计算完毕后,将c释放,保留逻辑视图。在4h->h grad前,需要将c计算回来。如图2所示,这里使用给d打tensor_hook的方式来进行重计算的插入。
使用场景
主要用于训练场景,用户内存不足或要节省内存时,可以开启激活函数重计算。
使用方法
需在训练脚本中加入以下参数配置:
--recompute-activation-function # 开启激活函数重计算 --recompute-activation-function-num-layers N # 指定激活函数重计算的层数

激活函数重计算可以与全重计算同时开启:
- 同时开启时,仅支持 --recompute-method设置为block。
- 同时开启时,会按照指定的全重计算和激活函数重计算的层数做各自类型的重计算,即不会有一层既做全重计算又做激活函数重计算。
执行优先级是先计算全重计算层,后计算激活函数重计算层。在流水线并行未开启的情况下,全重计算层数和激活函数重计算层数之和应该等于总层数。
使用效果
启用激活函数重计算后,内存占用减少,计算时间基本无损。