背景与挑战
MoE(Mixture of Experts,混合专家)模型中引入了alltoall通信算子,用于在ep(Expert Parallel,专家并行)组中不同rank间交换token。在MoE层前向过程中,MLP前后各有一个alltoall通信算子,且计算与通信为串行执行,需要减少这部分通信的时间,提升训练性能。
解决方案
Ampipe将transformer模型中从Attention到MLP部分的通信和计算的输入切分为多份,每一份之间数据互相独立不存在依赖,使得各个部分的计算和通信可以循环流水并行,同时调整计算和通信的算子执行顺序,实现计算和通信并行达到掩盖通信的目的。详细说明可参见文献AMPIPE: ACCELERATING MOE MODELTRAINING WITH INTRA-BLOCK PIPELINING。
图1 Intra-Block Pipeline Parallelism
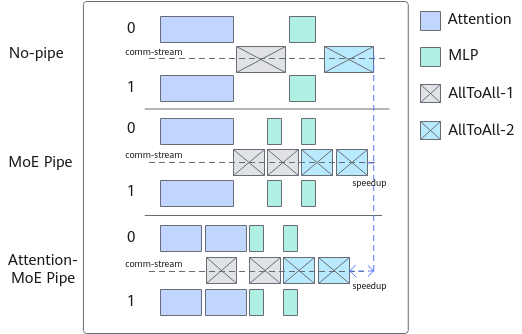
实现步骤:
- 从attention的输入开始切分,q(query)和atten_mask在seq序列维度进行切分,k(key)或v(value)保持完整输入,可以使得切分attention后再拼接结果等价。
- attention之后的Dropout、残差、norm归一化以及MLP等计算在seq序列维度上均独立,切分后再拼接结果同样可以等价,所以在中间各个部分不需要拼接,直到所有计算完成后再拼接结果即可实现。
- 切分后重新编排各个切分副本循环流水的顺序,使得计算和通信并行。
- 针对主流的Megatron的序列并行sequence-parallel以及长序列并行的context-parallel进行适配,可以实现sp(Sequence Parallel,序列并行)开启时MLP部分的all-gather和reduce-scatter通信隐藏。
使用场景
在训练MoE模型时,可以开启Ampipe特性。
推荐在--seq-length序列长度较长时开启特性,可以获得更好的性能提升。
使用方法
- 在训练脚本中添加如下参数即可使能Ampipe特性。
--ampipe-degree N # N为切分数
- 推荐开启如下参数,额外掩盖MLP中tp域内通信以达到最佳性能提升。
--ampipe-tp-sp-comm-overlap
- 支持同时开启Ampipe特性(包含以上两个特性开关)以及MLP通信隐藏特性--use-pipe-experts,单独或同时设置--pipe-experts-multi-stream和--pipe-experts-multi-data N来叠加使用“多流水线”和“多副本”的特性。
启用该特性时需注意以下几点:
- 在开启--ampipe-degree N时,若N过大,导致输入数据切分过细,会引入多余的cast和add算子,造成额外的开销,引起性能劣化。
目前仅推荐设置--ampipe-degree为2,在--context-parallel-size大于1的场景下,仅支持设置--ampipe-degree为2。
- 推荐开启--ampipe-tp-sp-comm-overlap,尤其在开启--sequence-parallel时,可额外掩盖MLP中tp域内通信以达到最佳性能提升。
- 与部分通信隐藏特性冲突,暂时不支持。

- 需要在开启--moe-model-type deepspeed_moe以及--use-flash-attn的前提下使用该特性。
- 需要保证设置的--seq-length即序列长度可以被--ampipe-degree整除,如果需要开启--sequence-parallel以及--context-parallel-size大于1,需要额外保证设置的--seq-length可以再被tp和cp整除。
- 同时开启Ampipe特性以及MLP通信隐藏特性时,多副本数量N(--pipe-experts-multi-data N)必须被Ampipe切分数M(--ampipe-degree M )整除且N大于M,否则--use-pipe-experts不生效;额外设置--pipe-experts-multi-stream时,此限制可以放开至N大于等于M。
- 暂不支持与异步DDP(--overlap-grad-reduce)、权重更新通信隐藏(--overlap-param-gather)以及Nano-Pipe流水线并行(--use-nanopipe)、重计算流水独立调度(--recompute-in-bubble、--recompute-in-advance)和自适应选择重计算特性同时开启。
使用效果
使用该特性,通过减少通信时间,提高设备利用效率,可总体获得3%-5% 的计算效率提升。