在Device侧,部分操作符执行速度过快,可能导致Device侧需等待主机端CPU下发新任务进行计算,从而造成不必要的等待时间。这种等待不仅会限制NPU的计算效率,更可能成为整个系统性能的瓶颈。为解决这一问题,可将面临下发瓶颈的操作符替换为自定义融合操作符。例如,将dropout、add和layer_norm操作融合为npu_dropout_add_layer_norm。
功能描述
“npu_dropout_add_layer_norm”融合算子实现了以下计算公式:
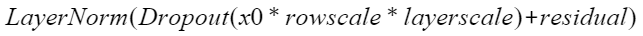
接口原型
npu_dropout_add_layer_norm(x0, residual, weight, bias, dropout_p, epsilon, rowscale=None, layerscale=None, prenorm=False, residual_in_fp32=False, return_dropout_mask=False) -> (Tensor, Tensor, Bool)
参数说明
- x0:必选输入,shape为(B,S,H)。
- residual:必选输入,shape为(B,S,H),可输入None,代表残差。
- weight:必选输入,shape为(H,),用于归一化处理的权重参数。
- bias:必选输入,shape为(H,),数据类型与输入weight一致,可输入None,用作归一化处理的偏置参数。
- dropout_p:必选属性,数据类型float,表示Dropout舍弃概率,eval模式下p=0。
- epsilon:必选属性,数据类型float。归一化处理时,添加到分母中的值,以提高数值稳定性。
- rowscale:可选输入,shape为(B,S),数据类型与输入x0一致,缺省值为None,表示矩阵按行缩放比例。
- layerscale:可选输入,shape为(H,),数据类型与输入x0一致,缺省值为None,表示矩阵按列缩放比例。
- prenorm:可选属性,数据类型为bool,缺省值为False,表示是否返回输出pre_norm_result。
- residual_in_fp32:可选属性,数据类型为bool,缺省值为False,仅当residual非None时有效。
- return_dropout_mask:可选属性,数据类型为bool,缺省值为False,决定是否返回dropout掩码drop_mask。
x0 |
residual |
weight |
rowscale |
layerscale |
|---|---|---|---|---|
fp32 |
fp32 |
fp32 |
fp32 |
fp32 |
fp16 |
fp16 |
fp16 |
fp16 |
fp16 |
bf16 |
bf16 |
bf16 |
bf16 |
bf16 |
输出说明
- norm_result:必选输出,数据类型与输入x0一致。
- pre_norm_result:可选输出,数据类型与输入residual一致。
- mask_result:可选输出,数据类型为布尔型。
使用示例
示例一(基础使用):
输入x0和weight,结果只返回norm_result。
import torch
import torch_npu
from mindspeed.ops.dropout_add_layer_norm import npu_dropout_add_layer_norm
batch, seq, hidden_size = 6, 60, 1024
x0 = torch.randn((batch, seq, hidden_size), requires_grad=True).to(torch.float).npu()
weight = torch.randn((hidden_size, ), requires_grad=True).to(torch.float).npu()
residual, bias, rowscale, layerscale = None, None, None, None
dropout_p = 0.0
epsilon = 1e-5
prenorm, residual_in_fp32, return_dropout_mask = False, True, False
# 前向传播实例
norm_result = npu_dropout_add_layer_norm(x0, residual, weight, bias, dropout_p, epsilon,
rowscale, layerscale, prenorm, residual_in_fp32, return_dropout_mask)
g = torch.randn_like(norm_result)
norm_result.backward(g)
x0_grad = x0.grad
weight_grad = weight.grad
示例二:
输入x0、residual、weight、rowscale、layerscale,结果返回norm_result、pre_norm_result、mask_result。
import torch
import torch_npu
from mindspeed.ops.dropout_add_layer_norm import npu_dropout_add_layer_norm
batch, seq, hidden_size = 6, 60, 1024
x0 = torch.randn((batch, seq, hidden_size), requires_grad=True).to(torch.float).npu()
residual = torch.randn((batch, seq, hidden_size), requires_grad=True).to(torch.float).npu()
weight = torch.randn((hidden_size, ), requires_grad=True).to(torch.float).npu()
bias = torch.randn((hidden_size, ), requires_grad=True).to(torch.float).npu()
rowscale = torch.randn((batch, seq, ), requires_grad=True).to(torch.float).npu()
layerscale = torch.randn((hidden_size, ), requires_grad=True).to(torch.float).npu()
dropout_p = 0.0
epsilon = 1e-5
prenorm, residual_in_fp32, return_dropout_mask = True, True, True
# 前向传播实例
norm_result, pre_norm_result, mask_result = npu_dropout_add_layer_norm(x0, residual, weight,
bias, dropout_p, epsilon,
rowscale, layerscale, prenorm,
residual_in_fp32, return_dropout_mask)
g = torch.randn_like(norm_result)
norm_result.backward(g)
x0_grad = x0.grad
residual_grad = residual.grad
weight_grad = weight.grad
bias_grad = bias.grad
rowscale_grad = rowscale.grad
layerscale_grad = layerscale.grad