Format为数据的物理排布格式,定义了解读数据的维度,比如1D,2D,3D,4D,5D等。
NCHW和NHWC
- N:Batch数量,例如图像的数目。
- H:Height,特征图高度,即垂直高度方向的像素个数。
- W:Width,特征图宽度,即水平宽度方向的像素个数。
- C:Channels,特征图通道,例如彩色RGB图像的Channels为3。
由于数据只能线性存储,因此这四个维度有对应的顺序。不同深度学习框架会按照不同的顺序存储特征图数据,比如Caffe,排列顺序为[Batch, Channels, Height, Width],即NCHW。TensorFlow中,排列顺序为[Batch, Height, Width, Channels],即NHWC。
如图1所示,以一张格式为RGB的图片为例,NCHW中,C排列在外层,实际存储的是“RRRRRRGGGGGGBBBBBB”,即同一通道的所有像素值顺序存储在一起;而NHWC中C排列在最内层,实际存储的则是“RGBRGBRGBRGBRGBRGB”,即多个通道的同一位置的像素值顺序存储在一起。

尽管存储的数据相同,但不同的存储顺序会导致数据的访问特性不一致,因此即便进行同样的运算,相应的计算性能也会不同。
NC1HWC0
昇腾AI处理器中,为了提高通用矩阵乘法(GEMM)运算数据块的访问效率,所有张量数据统一采用NC1HWC0的五维数据格式,如下图所示。

C0与微架构强相关,等于AI Core中矩阵计算单元的大小,对于FP16类型为16,对于INT8类型则为32,这部分数据需要连续存储。
C1=C/C0。如果结果不整除,向上取整。
- NHWC -> NC1HWC0的转换过程为:
- 将NHWC数据在C维度进行分割,变成C1份NHWC0。
- 将C1份NHWC0在内存中连续排列,由此变成NC1HWC0。
NHWC变换为NC1HWC0的过程为:
Tensor.reshape( [N, H, W, C1, C0]).transpose( [0, 3, 1, 2, 4] )
- NCHW变换为NC1HWC0的过程为:
Tensor.reshape( [N, C1, C0, H, W]).transpose( [0, 1, 3, 4, 2] )
FRACTAL_NZ
FRACTAL_NZ是分形格式,如Feature Map的数据存储,在cube单元计算时,输出矩阵的数据格式为NW1H1H0W0。整个矩阵被分为(H1*W1)个分形,按照column major排布,形状如N字形;每个分形内部有(H0*W0)个元素,按照row major排布,形状如z字形。考虑到数据排布格式,将NW1H1H0W0数据格式称为Nz(大N小z)格式。其中,H0,W0表示一个分形的大小,示意图如下所示:
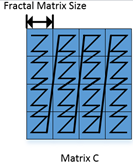
ND –> FRACTAL_NZ的变换过程为:
tensor.reshape( [M1, M0, N1, N0] ).transpose( [2, 0, 1, 3] )
FRACTAL_Z
FRACTAL_Z是用于定义卷积权重的数据格式,由FT Matrix(FT:Filter,卷积核)变换得到。FRACTAL_Z是送往Cube的最终数据格式,采用“C1HW,N1,N0,C0”的4维数据排布。
数据有两层Tiling,如下图所示:

第一层与Cube的Size相关,数据按照列的方向连续(小n);第二层与矩阵的Size相关,数据按照行的方向连续(大Z)。
例如:HWCN = (2, 2, 32, 32),将其变成 FRACTAL_Z( C1HW, N1, N0, C0 ) = (8, 2, 16, 16)
HWCN变换5HD的过程为:
Tensor.padding([ [0,0], [0,0], [0,(C0–C%C0)%C0], [0,(N0–N%N0)%N0] ]).reshape( [H, W, C1, C0, N1, N0]).transpose( [2, 0, 1, 4, 5, 3] ).reshape( [C1*H*W, N1, N0, C0])
NCHW变换5HD的过程为:
Tensor.padding([ [0,(N0–N%N0)%N0], [0,(C0–C%C0)%C0], [0,0], [0,0] ]).reshape( [N1, N0, C1, C0, H, W,]).transpose( [2, 4, 5, 0, 1, 3] ).reshape( [C1*H*W, N1, N0, C0])