AI Core采用顺序取指令、并行执行指令的调度方式,如下图所示:
图1 AI Core指令调度方式
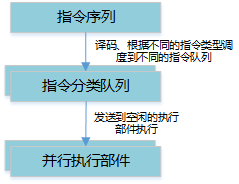
指令序列被顺序译码,根据指令的类型,有两种可能:
- 如果指令是Scalar指令,指令会被直接执行。
- 其他指令,指令会被调度到5个独立的分类队列,然后再分配到某个空间的执行部件执行。
表1 分类队列 队列缩写
队列名称
备注
V
Vector指令队列
用于调度向量指令
M
Matrix指令队列
用于调度Cube指令
MTE1
存储移动指令队列1
用于调度如下内存移动指令:
L1到L0A/L0B/UB,或者用SPR初始化L0A/L0B Buffer
MTE2
存储移动指令队列2
用于调度如下内存移动指令:
GM到L1/L0A/L0B/UB
MTE3
存储移动指令队列3
用于调度如下内存移动指令:
UB到GM
根据调度分类的不同,可以把指令分类,加上被译码过程直接解释的Scalar指令(缩写为S),可以有6种指令分类:S、V、M、MTE1/2/3。
除S队列之外,分属于不同队列的指令能够乱序执行,但是队列内部指令为顺序执行,即在满足数据依赖的前提下,指令的物理执行顺序不一定与代码的书写顺序一致。
硬件按照下发顺序,将不同队列的指令分发到相应的队列上执行,昇腾AI处理器提供Barrier、set_flag/wait_flag两种指令,保证队列内部以及队列之间按照逻辑关系执行。- Barrier本身是一条指令,用于在队列内部约束执行顺序。其作用是,保证前序队列中所有数据的读写工作全部完成,后序指令才能执行。
- set_flag/wait_flag为两条指令,在set_flag/wait_flag的指令中,可以指定一对指令队列的关系,表示两个队列之间完成一组“锁”机制,其作用方式为:
- set_flag:当前序指令的所有读写操作都完成之后,当前指令开始执行,并将硬件中的对应标志位设置为1。
- wait_flag:当执行到该指令时,如果发现对应标志位为0,该队列的后续指令将一直被阻塞;如果发现对应标志位为1,则将对应标志位设置为0,同时后续指令开始执行。
TBE封装了这种依赖关系,所以应用开发人员不必对Barrier或者Flag进行编程。但应用开发人员仍需要理解这个基本原理,才能通过合适的代码调度,实现更好的同步关系。基于DSL方式进行算子开发无需关注代码调度,DSL提供了自动调度(auto_schedule)机制。