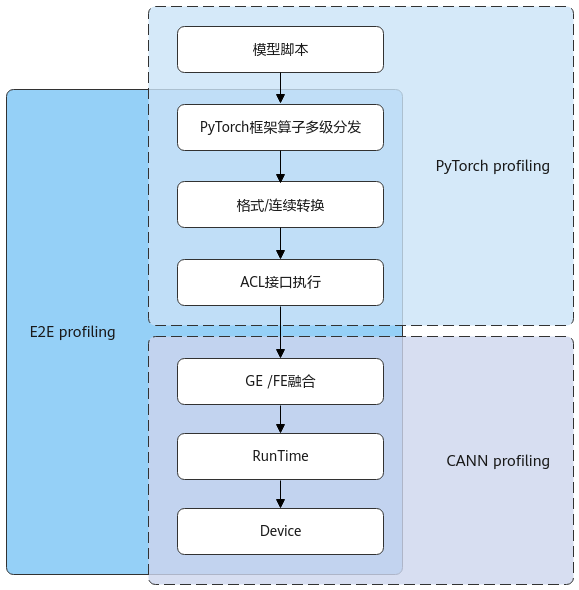
当模型训练过程中吞吐量(系统在单位时间内处理数据的数量)指标不达标时,可以采集训练过程中的profiling数据来分析是哪个环节、哪个算子导致的性能消耗。基于NPU的PyTorch在模型训练时,算子通过PyTorch框架多次分发后,调用AscendCL接口,然后经过CANN层编译和GE/FE等模块的处理,最终在NPU上计算执行。
针对这一系列的流程,我们提供了三种不同层次的profiling方式,记录不同层面的性能数据,分别是PyTorch profiling、CANN profiling和E2E profiling(推荐)。
- PyTorch profiling功能是继承自原生PyTorch的功能,主要记录了PyTorch框架层面的算子在多次分发中调用栈的耗时信息,可以获取算子耗时信息、算子的input shape、使用的NPU内存等信息。但是对于算子在CANN内的流程,该功能只能作为一整块展示,无法详细展示内部流程。
- CANN profiling则是仅针对CANN层内算子执行流程来记录性能信息,主要功能是分析算子在NPU设备上的执行性能,可以清晰看出算子在不同shape/format下耗时信息。CANN profiling采集CANN层软件站的数据,例如GE模块、TASK SCHEDULE的任务调度信息数据、AscendCL接口、Runtime接口耗时数据等。
- E2E profiling将PyTorch层面和CANN层面的性能数据叠加起来,可以端到端地分析模型性能瓶颈所在。E2E profiling展示的性能数据分模块展示,在PyTorch层面的数据与PyTorch profiling的数据基本一致,而在CANN 层面展示的数据分为GE/ACL/RunTime/AI CPU/device等多个模块,可以从整体上分析模型性能瓶颈。
三种profiling的关系如下图所示。
图1 3种Profiling关系示意图