背景介绍
在使用昇腾AI处理器在线推理PyTorch网络过程中,发现整体执行时间较长。为了找出原因,使用Profiling性能分析工具对该网络应用执行推理耗时分析,分析结果显示运行的接口aclmdlExecute执行耗时较长,进一步分析结果发现Conv算子执行时间最长。因此我们打开PyTorch网络转换成的om模型查询Conv算子,发现该算子是多个计算单元组成,这样会造成极大的推理开销。由于Conv算子所在函数为Mish激活函数,而当前昇腾AI处理器支持的激活函数只有:Relu、Leakyrelu、Prelu、Elu、Srelu,Mish函数暂时不在支持范围内,因此造成模型转换后的Mish函数被分解成了多个计算单元。
问题解决:我们通过将om模型中的Mish函数替换昇腾AI处理器的激活函数,尝试降低推理耗时,以Leakyrelu替换Mish函数为例,重新执行Profiling性能分析,结果发现推理耗时明显降低。

- 本文仅介绍Profiling性能分析工具的操作及分析过程,对于om模型的算子分析以及函数替换等操作此处不做阐述。
- 有关PyTorch模型转换为om模型的详细介绍请参见《PyTorch网络模型移植&训练指南》中的“模型保存与转换”章节。
前提条件
操作系统:Ubuntu18.04
Profiling性能分析操作
通过以下操作方法执行Profiling:
- 采集Profiling数据。
执行Profiling命令,采集当前已编译完成的应用软件模块性能数据。
./msprof --output=/home/HwHiAiUser/result --application=/home/HwHiAiUser/AscendProjects/MyApp1/out/main
执行完上述命令后,会在--output目录下生成PROF_XXX目录,PROF_XXX目录即为保存的原始Profiling数据。
- 解析Profiling数据。
- 以Ascend-cann-toolkit开发套件包的运行用户登录开发环境。以HwHiAiUser用户为例。
- 切换至msprof.py脚本所在目录,如/home/HwHiAiUser/Ascend/ascend-toolkit/latest/tools/profiler/profiler_tool/analysis/msprof。
小技巧:为方便执行msprof.py脚本,您可以使用HwHiAiUser用户执行命令alias msprof='python3 /home/HwHiAiUser/Ascend/ascend-toolkit/latest/tools/profiler/profiler_tool/analysis/msprof/msprof.py'设置别名,后续就可以不用进入/home/HwHiAiUser/Ascend/ascend-toolkit/latest/tools/profiler/profiler_tool/analysis/msprof目录,在任意目录输入msprof即可执行Profiling命令。该操作仅在当前窗口下生效。
- 执行如下命令,解析PROF_XXX目录下的Profiling数据。
python3 msprof.py import -dir /home/HwHiAiUser/profiler_data
此处以通过import命令行方式解析Profiling数据为例,解析Profiling数据详细介绍请参见数据解析与导出。
- 在msprof.py脚本所在目录继续执行如下命令,导出timeline数据。
python3 msprof.py export timeline -dir home/HwHiAiUser/profiler_data
执行完上述命令后,会在collection-dir目录下的PROF_XXX目录下生成timeline目录,不同的数据生成对应的json文件,如图1所示,具体内容参见Profiling数据说明。
- 在msprof.py脚本所在目录继续执行如下命令,导出summary数据。
python3 msprof.py export summary -dir /home/HwHiAiUser/profiler_data --format csv
执行完上述命令后,会在collection-dir目录下的PROF_XXX目录下生成summary目录,不同的数据(推理,系统)生成对应的csv文件,如图2所示,具体内容参见Profiling数据说明。


问题定位
- 我们首先打开timeline数据的ai_stack_time_{device_id}_{model_id}_{iter_id}.json查看各个组件的耗时数据。在Chrome浏览器中输入“chrome://tracing”地址,将各个组件的耗时数据ai_stack_time_{device_id}_{model_id}_{iter_id}.json拖到空白处进行打开,通过键盘上的快捷键(w:放大,s:缩小,a:左移,d:右移),查看每次迭代的耗时情况。如图3所示。
此时我们可以直观的看到接口调用耗时最长的时间线为AscendCL接口的aclmdlExcute接口。
参见《应用软件开发指南 (C&C++)》中的“AscendCL API参考”章节查找aclmdlExcute接口的作用为“执行应用推理,直到返回推理结果,同步接口”。我们可以发现该接口是执行接口,也就是说应用在推理的过程中存在执行耗时较长的接口。
- 我们接着打开acl_{device_id}_{model_id}_{iter_id}.json文件查看AscendCL接口耗时数据。如图4所示。
此时我们可以看到AscendCL接口中耗时最长的时间线有两段,分别为aclmdlLoadFromFileWithMem和aclmdlExecute接口。也就是说虽然aclmdlExecute接口是在执行接口中耗时最长,但是在AscendCL接口中,aclmdlExecute接口耗时仅排第二。
参见《应用软件开发指南 (C&C++)》中的“AscendCL API参考”章节查找aclmdlLoadFromFileWithMem接口的作用为“从文件加载离线模型数据”,可以分析该接口耗时取决于加载离线模型的时间,加载时间我们暂时无法进行调优。那么还需要继续从aclmdlExecute接口深入分析。
- 由于aclmdlExecute接口是执行接口,而模型中所有算子执行的时间总和就是执行耗时。那么我们通过打开task_time_{device_id}_{model_id}_{iter_id}.json文件查看Task Scheduler任务调度信息数据,分析执行推理过程中具体耗时较长的任务。如图5所示。
从Task Scheduler任务调度信息数据中我们可以看到,时间线中执行了大量的Conv算子(时间线过长图片无法完全展示),且每个Conv算子的执行时间都比其他算子长。
至此我们基本可以判断拖慢应用推理过程中执行效率的因素中,Conv算子的占比较大。
- 为了进一步验证这个结论我们可以打开summary数据中的ai_stack_time_{device_id}_{model_id}_{iter_id}.csv文件如图6所示、acl_{device_id}_{model_id}_{iter_id}.csv文件如图7所示和task_time_{device_id}_{model_id}_{iter_id}.csv文件如图8所示。可以通过表格中的自定义排序,选择Duration为主要关键字,进行降序重排表格。
根据以上三张表中数据可以判断:各个组件耗时信息数据中AscendCL接口的aclmdlExecute接口耗时最长;AscendCL接口中耗时最长的时间线有两段,aclmdlExecute接口耗时排第二;Task Scheduler任务调度信息数据中存在大量的Conv算子,且每个Conv算子的执行时间都较长。
到此Profiling性能分析工具的任务已经完成。
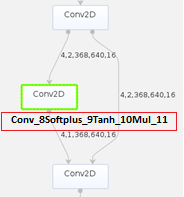
- 接下来我们可以参见《ATC工具使用指南》中的“原始模型文件或离线模型转成json文件”章节,打开PyTorch网络转换成的om模型查询Conv算子,发现该算子是多个计算单元组成,如图9所示,这样会造成极大的推理开销。
- 我们通过查询代码发现计算单元中的Softplus、Tanh和Mul是属于Mish激活函数的计算公式,如图10所示。而当前昇腾AI处理器支持的激活函数只有:Relu、Leakyrelu、Prelu、Elu和Srelu,Mish函数不在支持范围内,因此造成模型转换后的Mish函数被分解成了多个计算单元。
解决该问题最简单的办法就是找到效率更高的替代函数。







问题解决
尝试以官方提供的Leaky Relu激活函数作为替换函数。函数替换操作请用户自行处理,此处不作阐述。完成函数替换后重新执行Profiling性能分析操作得到新的结果中,我们查看图11已经从原先的23.299ms降低到现在的14.190ms,查看图12发现大多数Conv算子的时间线已经得到缩短。同时Leaky Relu函数的精度比Mish函数要小1%,Leaky Relu函数精度更高。


结论
通过Profiling性能分析工具前后两次对网络应用推理的运行时间进行分析,并对比两次执行时间可以得出结论,替换Leaky Relu激活函数后,降低了Conv算子在应用推理的运行时间,提升了推理效率。