typedef enum {
ACL_PRECISION_MODE, // 算子精度模式
ACL_AICORE_NUM, // 模型编译时使用的AI Core数量
ACL_AUTO_TUNE_MODE, // 算子的自动调优模式
ACL_OP_SELECT_IMPL_MODE, // 选择算子是高精度实现还是高性能实现
ACL_OPTYPELIST_FOR_IMPLMODE, // 列举算子类型的列表,该列表中的算子使用ACL_OP_SELECT_IMPL_MODE指定的模式
ACL_OP_DEBUG_LEVEL, // TBE算子编译debug功能开关
ACL_DEBUG_DIR, // 保存模型转换、网络迁移过程中算子编译生成的调试相关过程文件的路径,包括算子.o/.json/.cce等文件。
ACL_OP_COMPILER_CACHE_MODE, // 算子编译磁盘缓存模式
ACL_OP_COMPILER_CACHE_DIR, // 算子编译磁盘缓存的目录
ACL_OP_PERFORMANCE_MODE, // 通过该选项设置是否按照算子执行高性能的方式编译算子
ACL_OP_JIT_COMPILE, // 选择是在线编译算子,还是使用已编译的算子二进制文件
ACL_OP_DETERMINISTIC, // 是否开启确定性计算
ACL_CUSTOMIZE_DTYPES, // 模型编译时自定义某个或某些算子的计算精度
ACL_OP_PRECISION_MODE, // 指定算子内部处理时的精度模式,支持指定一个算子或多个算子。
ACL_ALLOW_HF32 // hf32是昇腾推出的专门用于算子内部计算的精度类型,当前版本不支持
} aclCompileOpt;
表1 编译选项配置
编译选项 |
取值说明 |
ACL_PRECISION_MODE |
用于配置算子精度模式。如果不配置该编译选项,默认采用allow_fp32_to_fp16。
- force_fp32/cube_fp16in_fp32out:
配置为force_fp32或cube_fp16in_fp32out,效果等同,系统内部都会根据Cube算子或Vector算子,来选择不同的处理方式。cube_fp16in_fp32out为新版本中新增的,对于Cube算子,该选项语义更清晰。
- force_fp16:
表示网络模型中算子支持float16和float32时,强制选择float16。
- allow_fp32_to_fp16:
- 对于Cube计算,使用float16。
- 对于Vector计算,优先保持原图精度,如果网络模型中算子支持float32,则保留原始精度float32,如果网络模型中算子不支持float32,则直接降低精度到float16。
- must_keep_origin_dtype:
表示保持原图精度。如果原图中部分算子精度为float16,但NPU中该部分算子的实现不支持float16、仅支持float32,则系统内部会自动采用高精度float32;如果原图中部分算子精度为float32,但NPU中该部分算子的实现不支持float32类型、仅支持float16类型,则不能使用该参数值,系统不支持使用低精度。
- allow_mix_precision/allow_mix_precision_fp16:
配置为allow_mix_precision或allow_mix_precision_fp16,效果等同,均表示使用混合精度float16和float32数据类型来处理神经网络的过程。allow_mix_precision_fp16为新版本中新增的,语义更清晰,便于理解。 针对网络模型中float32数据类型的算子,按照内置的优化策略,自动将部分float32的算子降低精度到float16,从而在精度损失很小的情况下提升系统性能并减少内存使用。 若配置了该种模式,则可以在OPP软件包安装路径${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/config/<soc_version>/aic-<soc_version>-ops-info.json内置优化策略文件中查看“precision_reduce”参数的取值:
- 若取值为true(白名单),则表示允许将当前float32类型的算子,降低精度到float16。
- 若取值为false(黑名单),则不允许将当前float32类型的算子降低精度到float16,相应算子仍旧使用float32精度。
- 若网络模型中算子没有配置该参数(灰名单),当前算子的混合精度处理机制和前一个算子保持一致,即如果前一个算子支持降精度处理,当前算子也支持降精度;如果前一个算子不允许降精度,当前算子也不支持降精度。
- allow_mix_precision_bf16:当前版本暂不支持。
表示使用混合精度bfloat16和float32数据类型来处理神经网络的过程。针对网络模型中float32数据类型的算子,按照内置的优化策略,自动将部分float32的算子降低精度到bfloat16,从而在精度损失很小的情况下提升系统性能并减少内存使用。 若配置了该种模式,则可以在OPP软件包安装路径${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/config/<soc_version>/aic-<soc_version>-ops-info.json内置优化策略文件中查看“precision_reduce”参数的取值:
- 若取值为true(白名单),则表示允许将当前float32类型的算子,降低精度到bfloat16。
- 若取值为false(黑名单),则不允许将当前float32类型的算子降低精度到bfloat16,相应算子仍旧使用float32精度。
- 若网络模型中算子没有配置该参数(灰名单),当前算子的混合精度处理机制和前一个算子保持一致,即如果前一个算子支持降精度处理,当前算子也支持降精度;如果前一个算子不允许降精度,当前算子也不支持降精度。
- allow_fp32_to_bf16:当前版本暂不支持。
- 对于Cube计算,使用bfloat16。
- 对于Vector计算,优先保持原图精度,如果网络模型中算子支持float32,则保留原始精度float32,如果网络模型中算子不支持float32,则直接降低精度到bfloat16。
|
ACL_AICORE_NUM |
用于配置模型编译时使用的AI Core数量。 当前版本设置无效。 |
ACL_AUTO_TUNE_MODE |
该参数后续废弃,请勿配置,否则后续版本可能存在兼容性问题。若涉及调优,请参见《AOE工具使用指南》。 用于配置算子的自动调优模式。
- GA(Genetic Algorithm):遗传算法,用于设置Cube算子的调优性能。
- RL(Reinforcement Learning):强化学习,用于设置Vector算子的调优性能。
不支持该参数。 |
ACL_OP_SELECT_IMPL_MODE |
用于选择算子是高精度实现还是高性能实现。如果不配置该编译选项,默认采用high_precision。
- high_precision:表示算子采用高精度实现模式。
该参数采用系统内置的配置文件设置算子实现模式,内置配置文件路径为${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/impl_mode/high_precision.ini。 为保持兼容,该参数仅对high_precision.ini文件中算子列表生效,通过该列表可以控制算子生效的范围并保证之前版本的网络模型不受影响。
- high_performance:表示算子采用高性能实现模式。
该参数采用系统内置的配置文件设置算子实现模式,内置配置文件路径为${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/impl_mode/high_performance.ini。 为保持兼容,该参数仅对high_performance.ini文件中算子列表生效,通过该列表可以控制算子生效的范围并保证之前版本的网络模型不受影响。
- high_precision_for_all:表示算子采用高精度实现模式。
该参数采用系统内置的配置文件设置算子实现模式,内置配置文件路径为${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/impl_mode/high_precision_for_all.ini,该文件中列表后续可能会跟随版本更新。 该实现模式不保证兼容,如果后续新的软件包中有算子新增了实现模式(即配置文件中新增了某个算子的实现模式),之前版本使用high_precision_for_all的网络模型,在新版本上性能可能会下降。
- high_performance_for_all:表示算子采用高性能实现模式。
该参数采用系统内置的配置文件设置算子实现模式,内置配置文件路径为${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/impl_mode/high_performance_for_all.ini,该文件中列表后续可能会跟随版本更新。 该实现模式不保证兼容,如果后续新的软件包中有算子新增了实现模式(即配置文件中新增了某个算子的实现模式),之前版本使用high_performance_for_all的网络模型,在新版本上精度可能会下降。
|
ACL_OPTYPELIST_FOR_IMPLMODE |
通过ACL_OPTYPELIST_FOR_IMPLMODE选项设置算子类型的列表(多个算子使用英文逗号进行分隔),与ACL_OP_SELECT_IMPL_MODE选项配合使用,设置列表中的算子通过高精度实现或高性能实现。 |
ACL_OP_DEBUG_LEVEL |
用于配置TBE算子编译debug功能开关。
- 0:不开启算子debug功能,在执行atc命令当前路径不生成算子编译目录kernel_meta。
- 1:开启算子debug功能,在执行atc命令的目录下,生成kernel_meta文件夹,并在该文件夹下生成.o(算子二进制文件)、.json文件(算子描述文件)以及TBE指令映射文件(算子cce文件*.cce和python-cce映射文件*_loc.json),用于后续分析AICore Error问题。
- 2:开启算子debug功能,在执行atc命令的目录下,生成kernel_meta文件夹,并在该文件夹下生成.o(算子二进制文件)、.json文件(算子描述文件)以及TBE指令映射文件(算子cce文件*.cce和python-cce映射文件*_loc.json),用于后续分析AICore Error问题,同时设置为2,还会关闭编译优化开关、开启ccec调试功能(ccec编译器选项设置为-O0-g)。
- 3:不开启算子debug功能,在执行atc命令的目录下,生成kernel_meta文件夹,并在该文件夹中生成.o(算子二进制文件)和.json文件(算子描述文件),分析算子问题时可参考。
- 4:不开启算子debug功能,在执行atc命令的目录下,生成kernel_meta文件夹,并在该文件夹下生成.o(算子二进制文件)和.json文件(算子描述文件)以及TBE指令映射文件(算子cce文件*.cce)和UB融合计算描述文件({$kernel_name}_compute.json),可在分析算子问题时进行问题复现、精度比对时使用。
说明:
配置为2(即开启ccec编译选项)时,会导致算子Kernel(*.o文件)大小增大。动态Shape场景下,由于算子编译时会遍历可能的Shape场景,因此可能会导致算子Kernel文件过大而无法进行编译,此种场景下,建议不要配置ccec编译选项。
由于算子Kernel文件过大而无法编译的报错日志示例如下:
message:link error ld.lld: error: InputSection too large for range extension thunk ./kernel_meta_xxxxx.o
|
ACL_DEBUG_DIR |
用于配置保存模型转换、网络迁移过程中算子编译生成的调试相关过程文件的路径,包括算子.o/.json/.cce等文件。具体生成哪些文件以ACL_OP_DEBUG_LEVEL选项设置的取值为准。 路径支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符。 |
ACL_OP_COMPILER_CACHE_MODE |
用于配置算子编译磁盘缓存模式。该编译选项需要与ACL_OP_COMPILER_CACHE_DIR配合使用。
- enable:表示启用算子编译缓存。启用后可以避免针对相同编译参数及算子参数的算子重复编译,从而提升编译速度。
- force:启用算子编译缓存功能,区别于enable模式,force模式下会强制刷新缓存,即先删除已有缓存,再重新编译并加入缓存。比如当用户的python变更、依赖库变更、算子调优后知识库变更等,需要先指定为force用于先清理已有的缓存,后续再修改为enable模式,以避免每次编译时都强制刷新缓存。
- disable:表示禁用算子编译缓存。
该场景下,可以通过环境变量ASCEND_MAX_OP_CACHE_SIZE来限制某个芯片下缓存文件夹的磁盘空间的大小,当编译缓存空间大小达到ASCEND_MAX_OP_CACHE_SIZE设置的取值,且需要删除旧的kernel文件时,可以通过环境变量ASCEND_REMAIN_CACHE_SIZE_RATIO设置需要保留缓存的空间大小比例。配置示例如下: |
ACL_OP_COMPILER_CACHE_DIR |
用于配置算子编译磁盘缓存的目录,默认目录为$HOME/atc_data。该编译选项需要与ACL_OP_COMPILER_CACHE_MODE配合使用。 路径支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符。 如果设置了ACL_OP_DEBUG_LEVEL编译选项,则只有编译选项值为0或3才会启用编译缓存功能,其它取值禁用编译缓存功能。 |
ACL_OP_PERFORMANCE_MODE |
该参数已废弃,请勿配置,否则后续版本可能存在兼容性问题。 通过该选项设置是否按照算子执行高性能的方式编译算子,默认采用normal方式。 取值范围:
- normal:算子编译时按照编译性能最高的方式进行编译。
- high:算子编译时应该按照算子执行性能最好的方式去泛化编译。
|
ACL_OP_JIT_COMPIL |
选择是在线编译算子,还是使用已编译的算子二进制文件。
- enable:在线编译算子,系统根据得到的算子信息进行优化,从而编译出运行性能更优的算子。固定Shape网络场景下,建议设置为enable。
- disable:优先查找系统中的已编译好的算子二进制文件,如果能查找到,则不再编译算子,编译性能更优;如果查找不到,则再编译算子。动态Shape网络场景下,建议设置为disable。若将本参数设置为disable,则需要安装算子二进制文件包,请参见《CANN 软件安装指南》中的“常用操作 > 安装、升级和卸载二进制算子包”章节。
Atlas 200/300/500 推理产品,该选项默认值为enable。 Atlas 训练系列产品,该选项默认值为enable。 Atlas 推理系列产品,该选项默认值为enable。 Atlas A2训练系列产品,该选项默认值为disable。 |
ACL_OP_DETERMINISTIC |
是否开启确定性计算。
- 0:默认值,不开启确定性计算。
- 1:开启确定性计算。
当开启确定性计算功能时,算子在相同的硬件和输入下,多次执行将产生相同的输出。但启用确定性计算往往导致算子执行变慢。 默认情况下,不开启确定性计算,算子在相同的硬件和输入下,多次执行的结果可能不同。这个差异的来源,一般是因为在算子实现中,存在异步的多线程执行,会导致浮点数累加的顺序变化。 通常建议不开启确定性计算,因为确定性计算往往会导致算子执行变慢,进而影响性能。当发现模型多次执行结果不同,或者是进行精度调优时,可开启确定性计算,辅助模型调试、调优。 |
ACL_CUSTOMIZE_DTYPES |
*.cfg配置文件路径,包含文件名,配置文件中列举需要指定计算精度的算子名称或算子类型,每个算子单独一行。通过该配置,在模型编译时,可自定义某个或某些算子的计算精度。 配置约束:
- 路径和文件名支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、英文冒号(:)、中文字符。
- 配置文件中若为算子名称,以Opname::InputDtype:dtype1,...,OutputDtype:dtype1,...格式进行配置,每个Opname单独一行,dtype1,dtype2..需要与可设置计算精度的算子输入,算子输出的个数一一对应。
- 配置文件中若为算子类型,以OpType::TypeName:InputDtype:dtype1,...,OutputDtype:dtype1,...格式进行配置,每个OpType单独一行,dtype1,dtype2..需要与可设置计算精度的算子输入,算子输出的个数一一对应,且算子OpType必须为基于Ascend IR定义的算子的OpType,OpType可查阅《算子清单》。
- 对于同一个算子,如果同时配置了Opname和OpType的配置项,编译时以Opname的配置项为准。
- 使用该参数指定某个算子的计算精度时,如果模型转换过程中该算子被融合掉,则该算子指定的计算精度不生效。
|
ACL_OP_PRECISION_MODE |
设置算子精度模式的配置文件(.ini格式)路径以及文件名,路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符.
|
ACL_ALLOW_HF32 |
当前版本不支持该参数。 算子内部计算时是否允许HF32类型替换FP32类型,true允许,false不允许,当前版本该配置仅针对Conv类算子与Matmul类算子生效。默认针对Conv类算子,启用FP32转换为HF32;默认针对Matmul类算子,关闭FP32转换为HF32。 HF32是昇腾推出的专门用于算子内部计算的单精度浮点类型,与其他常用数据类型的比较如下图所示。HF32与FP32支持相同的数值范围,但尾数位精度(11位)却接近FP16(10位)。通过降低精度让HF32单精度数据类型代替原有的FP32单精度数据类型,可大大降低数据所占空间大小,实现性能的提升。 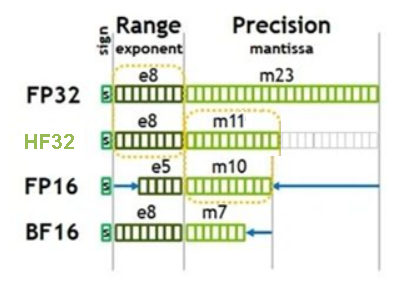
Atlas 200/300/500 推理产品,不支持该配置。 Atlas 训练系列产品,不支持该配置。 Atlas 推理系列产品,不支持该配置。
|