基本原理
AOE(Ascend Optimization Engine)是一款自动调优工具,通过生成调优策略、编译和在运行环境上验证的闭环反馈机制,不断迭代出更优的调优策略,最终得到最佳的调优策略,从而可以更充分利用硬件资源,不断提升网络的性能,达到最优的效果。
使用场景
用户在模型训练后,可参见PyTorch Analyse迁移分析工具,使用“dynamic_shape”模式,添加动态分析代码并运行脚本,根据分析结果判断为固定shape或动态shape。当结果为固定shape时,可选择AOE调优。
操作步骤
以PyTorch官网提供的Imagenet数据集训练脚本main.py为例,说明在PyTorch 1.8及以上版本通过AOE进行调优的方法。
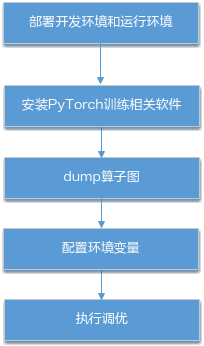

- 参见模型迁移与训练对训练脚本进行迁移使能混合精度并训练,保证进行AOE调优前模型能执行成功并且精度达到预期。
- dump算子图。
- 在添加混合精度模块后的代码中添加如下代码使能算子dump。
# switch to train mode model.train() end = time.time() scaler = amp.GradScaler() # 这里的dump_path需用户自行指定,本例以训练脚本main.py所在路径下的dump文件夹为例 # 例如可以设置为torch_npu.npu.set_aoe('./dump/') torch_npu.npu.set_aoe(dump_path) for i, (images, target) in enumerate(train_loader): # 仅需要运行一个step即可 if i > 0: exit() # measure data loading time data_time.update(time.time() - end) # move data to the same device as model images = images.to(device, non_blocking=True) target = target.to(device, non_blocking=True) # compute output with amp.autocast(): output = model(images) loss = criterion(output, target) # measure accuracy and record loss acc1, acc5 = accuracy(output, target, topk=(1, 5)) losses.update(loss.item(), images.size(0)) top1.update(acc1[0], images.size(0)) top5.update(acc5[0], images.size(0)) # compute gradient and do SGD step optimizer.zero_grad() scaler.scale(loss).backward() scaler.step(optimizer) scaler.update() # measure elapsed time batch_time.update(time.time() - end) end = time.time() if i % args.print_freq == 0: progress.display(i + 1) - 拉起训练命令执行训练。会在dump_path路径下生成算子图文件。
- 在添加混合精度模块后的代码中添加如下代码使能算子dump。
- (可选)指定调优后自定义知识库的存储路径。
export TUNE_BANK_PATH=/home/HwHiAiUser/custom_tune_bank
如不配置此环境变量,自定义知识库默认存储在${HOME}/Ascend/latest/data/aoe/custom/op/${soc_version}路径下。自定义知识库可以应用于推理和训练的性能提升,使用方法请参考《AOE工具使用指南》中的“附录>如何使用调优后的自定义知识库”章节。
- 执行调优(调优时间较长,请耐心等待)。
# dump_path为上述步骤中配置的算子图文件存放路径 # 以训练脚本main.py所在路径下的dump文件夹为例 aoe --job_type=2 --model_path=dump_path
调优完成后,会在/home/HwHiAiUser/custom_tune_bank/${soc_version}路径下生成自定义知识库。调优命令参数说明可参考下表。完整参数介绍请参见《AOE工具使用指南》中AOE参数说明章节。
表1 命令参数说明 参数名称
参数简述
---model_path
原始模型文件路径,该路径下可以存放多个模型文件。此处配置为dump算子图步骤中的dump_path。
-j
--job_type
调优模式。取值为:
- 1:子图调优,当前PyTorch框架不支持。
- 2:算子调优
- 调优完成后,将使能算子dump的代码删除,并设置如下环境变量使能自定义知识库。
export ENABLE_TUNE_BANK=True
- 重新执行训练,对比未使用AOE时的训练数据,查看是否产生性能收益。
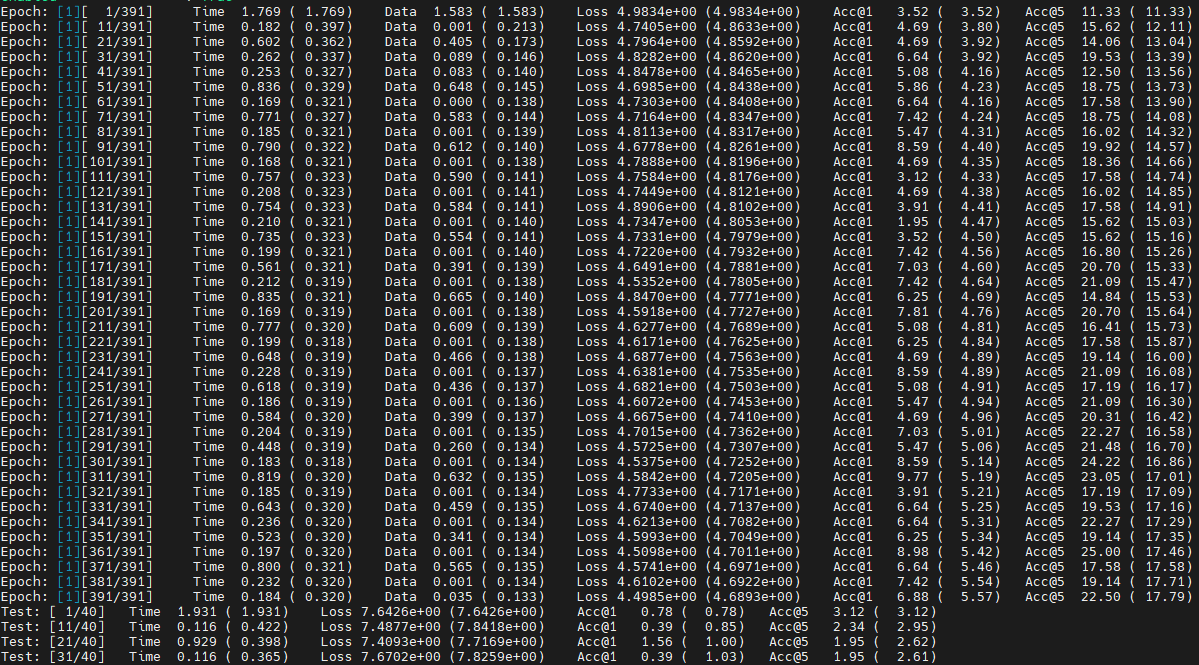
使用AOE前训练的第一个epoch数据,如图2所示,每10个数据处理耗时(TIME)均有超过0.1,最高达到0.8。
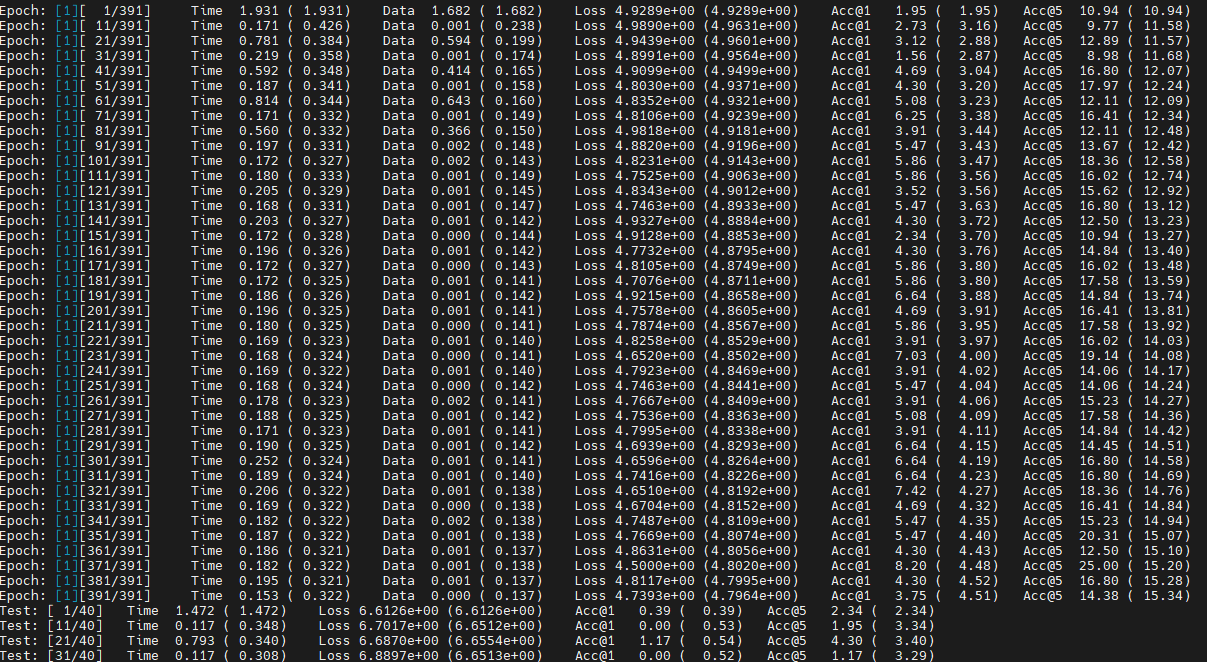
使用AOE后训练的第一个epoch数据,如图3所示,每10个数据处理耗时(TIME)明显下降。