原理
- 数据排布格式
- 基础格式。在深度学习领域,多维数据通过多维数组存储,比如卷积神经网络的特征图(Feature Map)通常用四维数组保存,即4D,4D格式解释如下:
- N:Batch数量,例如图像的数目。
- H:Height,特征图高度,即垂直高度方向的像素个数。
- W:Width,特征图宽度,即水平宽度方向的像素个数。
- C:Channels,特征图通道,例如彩色RGB图像的Channels为3。
由于数据只能线性存储,因此这四个维度有对应的顺序。不同深度学习框架会按照不同的顺序存储特征图数据,比如Caffe,排列顺序为[Batch, Channels, Height, Width],即NCHW。TensorFlow中,排列顺序为[Batch, Height, Width, Channels],即NHWC。
如图1所示,以一张格式为RGB的图片为例,NCHW中,C排列在外层,实际存储的是“RRRRRRGGGGGGBBBBBB”,即同一通道的所有像素值顺序存储在一起;而NHWC中C排列在最内层,实际存储的则是“RGBRGBRGBRGBRGBRGB”,即多个通道的同一位置的像素值顺序存储在一起。
尽管存储的数据相同,但不同的存储顺序会导致数据的访问特性不一致,因此即便进行同样的运算,相应的计算性能也会不同。
- NPU私有格式。
NPU在NCHW基础格式上,定义了众多与硬件强相关的私有格式,用于加速硬件计算,NPU主要计算单元AI Core包括了三种基础计算资源:矩阵计算单元(Cube Unit)、向量计算单元(Vector Unit)和标量计算单元(Scalar Unit)。Cube的特殊计算方式导致了更加严格的对齐方式,因此通常在计算之前就按照Cube的对齐要求先把数据组织好;Vector相对没有那么严格,因此可以在计算逻辑中做一些对齐操作。Cube算子对于format的要求,典型有两种:卷积类算子要求的NC1HWC0,Matmul类算子要求的FRACTAL_NZ,Vector算子对入参tensor无特殊对齐要求,一般使用ND格式
NPU私有格式全量列举如下。
typedef enum { ACL_FORMAT_UNDEFINED = -1, ACL_FORMAT_NCHW = 0, ACL_FORMAT_NHWC = 1, ACL_FORMAT_ND = 2, ACL_FORMAT_NC1HWC0 = 3, ACL_FORMAT_FRACTAL_Z = 4, ACL_FORMAT_NC1HWC0_C04 = 12, ACL_FORMAT_HWCN = 16, ACL_FORMAT_NDHWC = 27, ACL_FORMAT_FRACTAL_NZ = 29, ACL_FORMAT_NCDHW = 30, ACL_FORMAT_NDC1HWC0 = 32, ACL_FRACTAL_Z_3D = 33 } aclFormat;- UNDEFINED:未知格式,默认值。
- NCHW:NCHW格式。
- NHWC:NHWC格式。
- ND:表示支持任意格式,仅有Square、Tanh等这些单输入对自身处理的算子外,其它需要慎用。
- NC1HWC0:5维数据格式。其中,C0与微架构强相关,该值等于cube单元的size,例如16;C1是将C维度按照C0切分:C1=C/C0, 若结果不整除,最后一份数据需要padding到C0。
- FRACTAL_Z:卷积的权重的格式。
- NC1HWC0_C04:5维数据格式。其中,C0固定为4,C1是将C维度按照C0切分:C1=C/C0, 若结果不整除,最后一份数据需要padding到C0。当前版本不支持。
- HWCN:HWCN格式。
- NDHWC:NDHWC格式。对于3维图像就需要使用带D(Depth)维度的格式。
- FRACTAL_NZ:内部格式,用户目前无需使用。
- NCDHW:NCDHW格式。对于3维图像就需要使用带D(Depth)维度的格式。
- NDC1HWC0:6维数据格式。相比于NC1HWC0,仅多了D(Depth)维度。
- FRACTAL_Z_3D:3D卷积权重格式,例如Conv3D/MaxPool3D/AvgPool3D这些算子都需要这种格式来表达。
- 基础格式。
- 格式转换。
NPU对于不同的计算单元(cube、vector)所使用的默认私有格式不一致,导致在数据在不同的计算单元下流通时需要进行格式转化,另外基础格式到NPU私有格式也需要进行格式转换,NPU侧执行格式转换的算子为TransData。举例如下(图中闪电图标所在位置即为添加转换算子的位置):
图2 Conv2D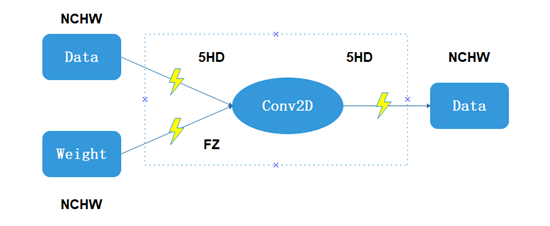 图3 Matmul
图3 Matmul
- 瓶颈产生原因。
TransData算子通常耗时比Conv、MatMul等算子的耗时大。有一些TransData存在冗余的情况,举例如下:
- 冗余:TransData(NCHW=>5HD) -- Conv2D -- TransData(5HD=>NCHW) -- TransData(NCHW =>5HD) -- Conv2D
- 非冗余:TransData(NCHW=>5HD) -- Conv2D -- TransData(5HD=>NCHW/ND) -- ReduceMean
典型场景如下:
- Cube-TransData-TransData-Cube。图4 典型场景1
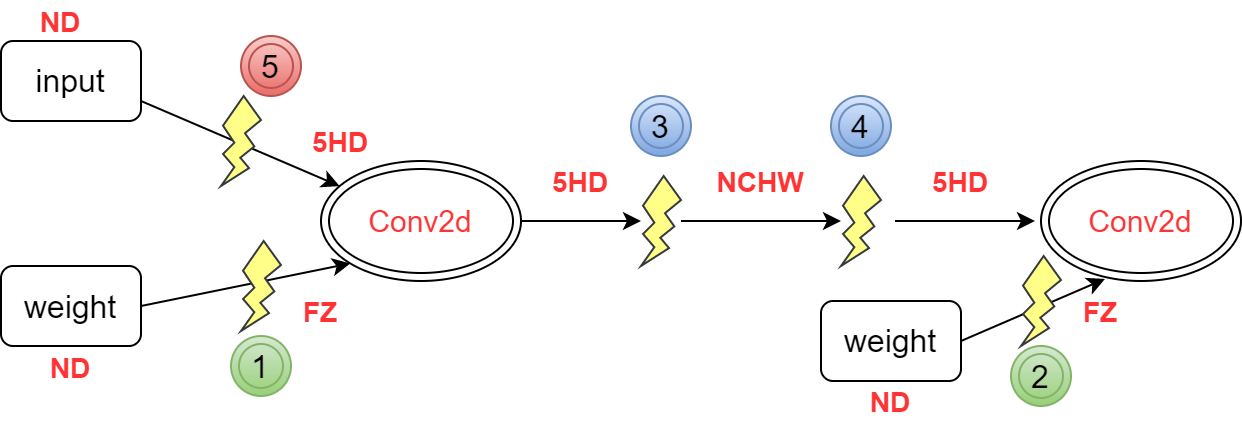
- Cube-TransData-Vector*n-TransData-Cube。图5 典型场景2
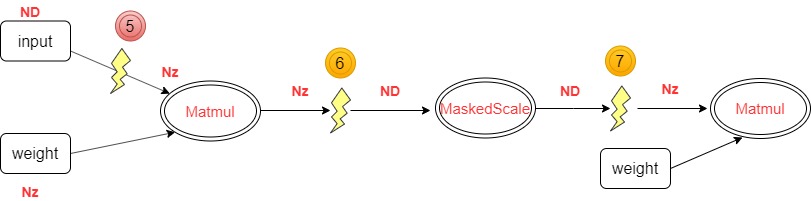
- reshape场景,私有格式数据拷贝。图6 典型场景3
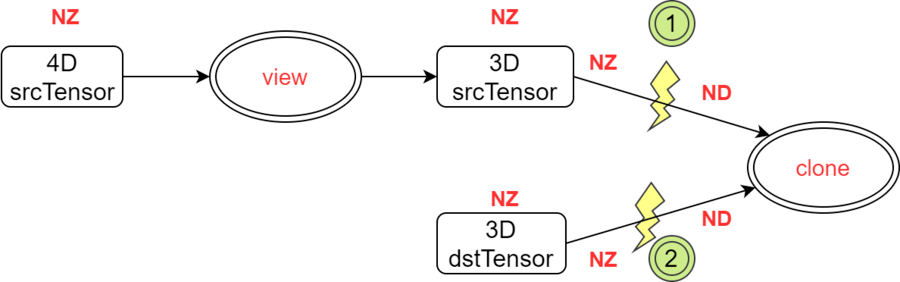

定位思路
- 参见Profiling数据采集及分析在训练脚本中使能profiling。
- 进入Profiling结果目录“path_to_profiling/result/PROF_timestamp/device_id/summary”。
- 打开op_summary_*_*.csv,按照“Input Formats”排序。
- 查看TransData算子耗时是否过长以分析是否进行格式转换。
优化策略
- 算子的格式转换。
使能npu_format_cast(format_type)。
示例1:将ND格式转换为5HD格式数据。def forward(x): x = x.npu_format_cast(3) # 3代表format_type的数字映射,完整映射关系请参见▪NPU私有格式 ....# 前向计算过程示例2:
hidden_states = self.embeddings(pixel_values) # 模型计算 hidden_states = hidden_states.npu_format_cast(29) # 手动添加格式转换 hidden_states = self.pre_layrnorm(hidden_states) # 模型计算
- 对于需要进行格式转换的算子,需在训练脚本的main函数入口处添加如下代码,torch.npu.set_option更多使用方法请参见设置算子编译选项。
option = {} option['MM_BMM_ND_ENABLE'] = 'disable' torch.npu.set_option(option)