模型结构
模型的主要结构:旋转位置编码,多头注意力机制,前馈网络,激活函数,前置层归一化。
首先LLAMA中使用的是Pre-LayerNorm——为了提高训练的稳定性,对每个transformer层的输入进行归一化,而不是输出进行归一化。
其次,RMSNorm,和标准的LayerNorm有少许差异。首先是没有移除均值,直接除的均方根,然后也没有加上偏置项。这两个小的修正可以保证在层归一化不会改变hidden_states对应的词向量的方向,而只会改变其模长。
图1 模型结构

位置编码
- 设计思想是使用绝对位置编码来实现相对位置编码的效果。
- 实现方式是使用旋转矩阵来表示绝对位置编码。
- 使用NTK扩展方式可以使RoPE在短文本上训练并在长文本上进行预测。
多头注意力机制用于融合不同token之间的信息,k和v的head数量可以是q的head数量的几分之一,类似分组卷积的思想,可以减少参数规模。RePE位置编码是每次做多头注意力时都进行一次,允许传入key和value的states的缓存past_key_value,这在多轮对话中可以减少重复计算,起到加速效果。attention_mask是通过加法形式作用到softmax之前的attention矩阵上的。
激活函数
SwiGLU,结合了Swish与GLU的特点,Swish是带有非零负值梯度的ReLU的平滑版本,表达式写作:
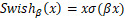
其中的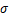 函数即为sigmoid函数。
函数即为sigmoid函数。
GLU则可视作一层网络,是线性变换后接门控机制的结构,其中的门控机制就是一个sigmoid函数用来控制信息能够通过多少。
SwiGLU其实就是采用Swish作为激活函数的GLU变体,由于引入了更多的权重矩阵,通常会对隐藏层的大小做一个缩放,从而保证整体的参数量不变。