内存建模
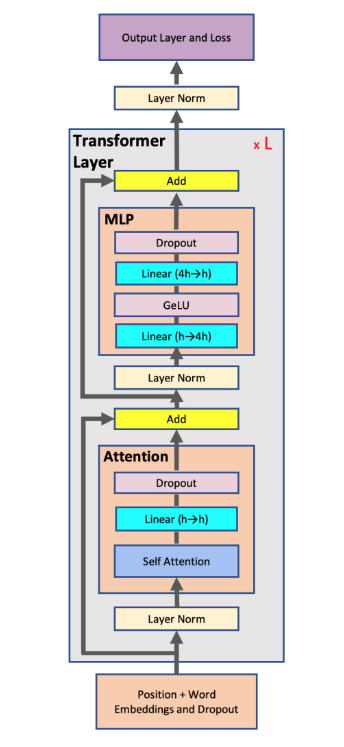
最常见的大模型结构为Transformer结构,该结构由Attention和FFN两个子层组成,如图1所示:
计算量和参数量如图2所示:

参数缩写如图3所示:

模型参数量如图4所示:

内存开销如图5所示:

片上内存上总的内存占用为: 96h^2L + 104hL + 8(v+s)h + 34bshL + 5abLs^2 。
内存优化
常用内存优化手段如下:
- 合理选择并行策略。充分利用集群环境,合理配置数据并行(DP)、Tensor并行(TP)、流水线并行(PP)、序列并行(SP)及优化器并行(ZERO-1/2/3)等大模型并行技术。大模型并行技术主要用于减少设备侧申请的长生命周期内存,如模型权重、梯度、优化器状态等。
- 合理配置重计算策略。对网络层使用重计算后,PyTorch的autograd引擎将不会保存激活值至反向梯度计算,而是在反向过程中重新进行前向的部分计算得到对应的激活值后,再进行反向计算。建议对激活值内存占用大、计算较快的网络层使用重计算技术,即选择性重计算,极端情况可以对整网进行全重计算。
- 定制融合算子。将多个小算子替换为一个融合算子,即可以减少小算子间流通的临时内存,也可以减少需保存至反向结束的激活值内存,典型的融合算子如Flash Attention。Flash attention是Attention层内存消减的业界主流解法,它通过小块数据驻留缓存连续计算,避免了大矩阵数据在片上内存和缓存间多次交换,不需要为大矩阵开辟内存。
- 消减私有格式转换。部分场景下私有格式会比ND格式占用更多内存,同时私有格式引起的格式转换操作会导致额外的临时内存申请,可能导致峰值内存冲高。ND格式整网流转是大模型优先使用的方式,可从算子Profiling中排查是否存在私有格式引入并进行消除。
- 消减非连续转连续。NPU因为芯片架构原因无法高效支持非连续读写,导致在PyTorch中调用View算子后,需要相对GPU额外的一个非连续转连续操作,导致临时内存增加。可从网络脚本侧进行View类操作的消减,常见的View类操作如transpose()、reshape()、split()等。
- 内存碎片消减。频繁地进行内存申请、释放将会产生内存碎片。可以通过调整训练脚本,让内存申请逻辑尽量亲和PyTorch内存池逻辑,以减少内存碎片产生。长生命周期内在训练开始时优先申请,如模型权重、梯度、优化器状态等;或优先申请大内存后申请小内存以提高内存复用率;功能等效的情况下尽量串行申请释放内存,避免批量申请释放内存,提高内存复用。
- 使能跨流内存复用。当前PyTorch框架默认的多流内存复用机制,会导致被通信流依赖的延迟释放,内存复用不及时。在torch_npu中提供了一个多流内存复用的增强功能,提早释放被通信流占用的内存,使得内存能有效利用。
- 使用FSDP,检查limit_all_gathers参数是否为True,该参数可以控制allgather下发数量,避免下发过快导致的allgather输出内存申请过多。类似FSDP场景,对于网络脚本或框架主动创建流的场景,需要关注跨流依赖内存逻辑,避免下发相比于执行过快,跨流依赖内存释放晚导致的内存上涨。