在大模型推理场景下,Prefill和Decoder阶段一起部署时,会造成计算资源的浪费,原因如下:
- Prefill阶段对算力要求高,序列长度不一致,在算力约束下可能导致时延增长。
- Decoder阶段单次计算量小,可以增大batch以提升算力利用率。
基于上述背景,提出了Prefill和Decoder分离部署的方案。LLM-DataDist作为大模型分布式集群和数据管理组件,提供了分布式集群中的KV Cache管理能力,包含两个模块link-manager和cache-manager。
- link-manager用于集群之间建链、断链,实现集群的动态扩缩的能力。
- cache-manager用于管理KV Cache,提供PD之间传输KV Cache的能力。
LLM-DataDist利用昇腾集群多样化通信链路(HCCS/RoCE)可实现跨实例和集群的高效KV Cache传输,并支持与主流LLM推理框架如MindIE-LLM、vLLM等的集成。
图1 LLM-DataDist整体架构
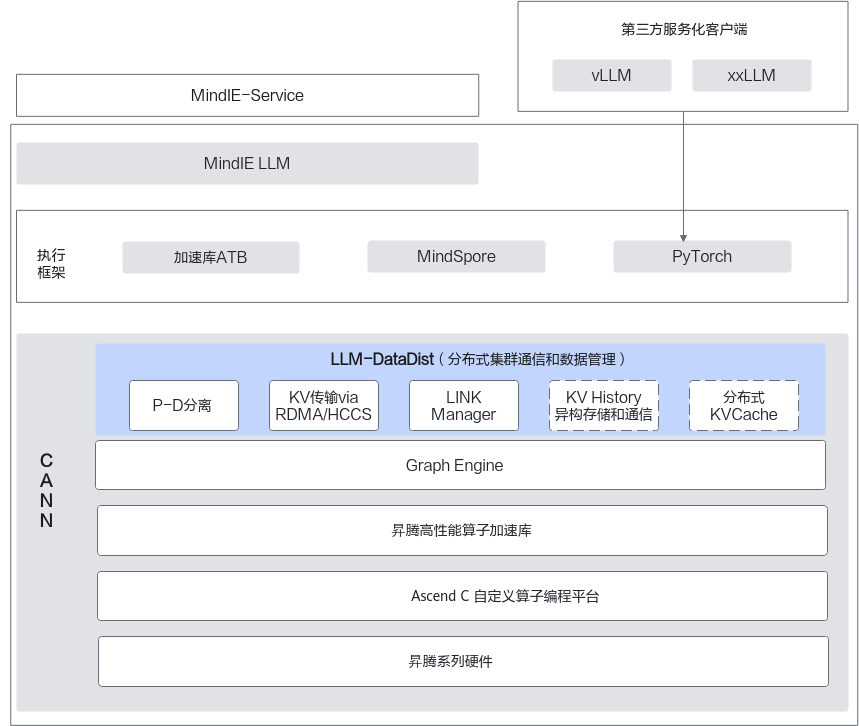
图2 基于CANN的P-D分离系统示意图
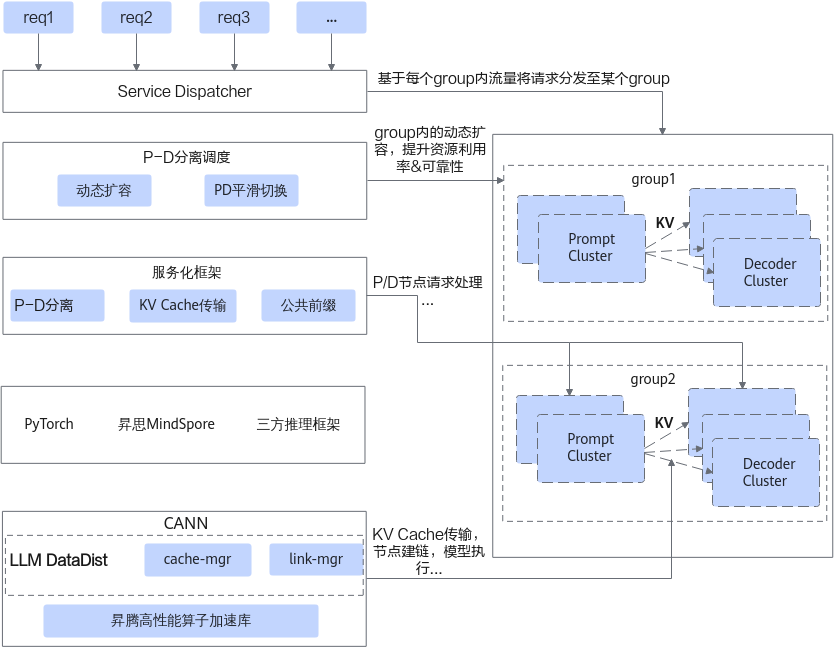
基于如上的分层,外部在与PyTorch/MindSpore等这些执行框架解耦的同时,内部也将不同特性进行了解耦:
- 服务化框架层:基于LLM-DataDist提供的KV Cache管理能力来构建起P-D之间的KV Cache传输,可以结合常见的KV Cache的优化手段,例如PA(Paged Attention)、公共前缀缓存等。
- P-D分离调度层:基于LLM-DataDist提供的集群动态扩缩能力来构建起P-D集群的管理,并可以在业务的忙闲时以及故障场景下完成Prefill或Decoder节点的上下线。