DataFlow结构
图1 DataFlow结构
DataFlow分三层,各层介绍如下。
- DataFlow API:负责异构计算流表达,App开发人员使用DataFlow API表达业务的数据流,生成基于Graph IR的计算图。数据流表达详细描述请参见数据流表达。
- 异构并行编译器:负责异构计算图编译,将计算图基于异构计算单元的组成关系和连接拓扑进行图切分、图优化和图部署,生成各个异构计算单元的执行Bin。
- 异构Runtime:根据异构计算图编译输出的结果,将执行Bin调度到对应的异构执行单元上执行。异构Runtime详细描述请参见异构Runtime。
数据流表达
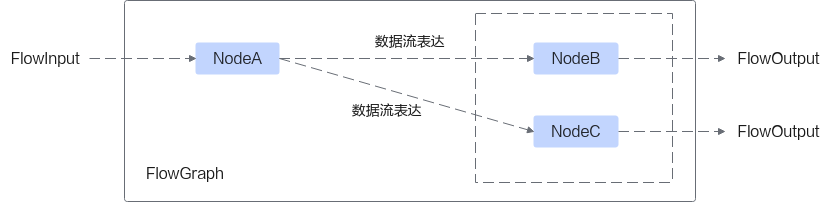
图2 数据流表达示意图
上图中各个节点解释如下。
- FlowData:数据节点,每个FlowData对应一个输入。
- FlowNode:逻辑计算节点的抽象表示。可以关联具体的ProcessPoint实现,ProcessPoint可分为FunctionPp (UDF的计算处理点)、GraphPP(Graph的计算处理点)。
- FlowOutput:数据输出。
- Edge:表示数据流连边。
- FlowGraph:由一系列输入节点FlowData和计算节点FlowNode以及数据流连边Edge构成的DAG图。
- 数据流图表达的规则和约束如下。
- FlowGraph是DAG(Directed Acyclic Graph)图,数据流有向且不允许有成环表达。
- 不支持无输入,也不支持无输入且无输出的FlowGraph。
- 节点间流转的数据要保证不可变的,因此不允许计算节点修改输入数据。
- 数据流支持1对多,表示复制相同数据后分发给多个Node;但不支持多对1。
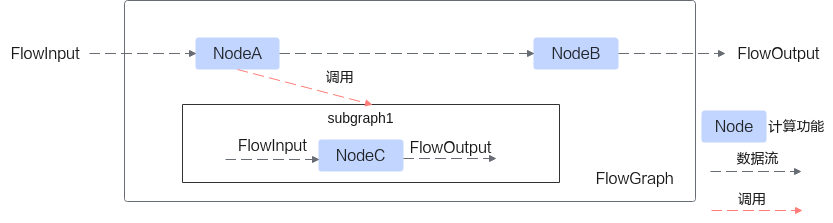
- 支持以子图表达为调用闭包,实现控制流表达如循环迭代,分支控制逻辑如下。
异构Runtime
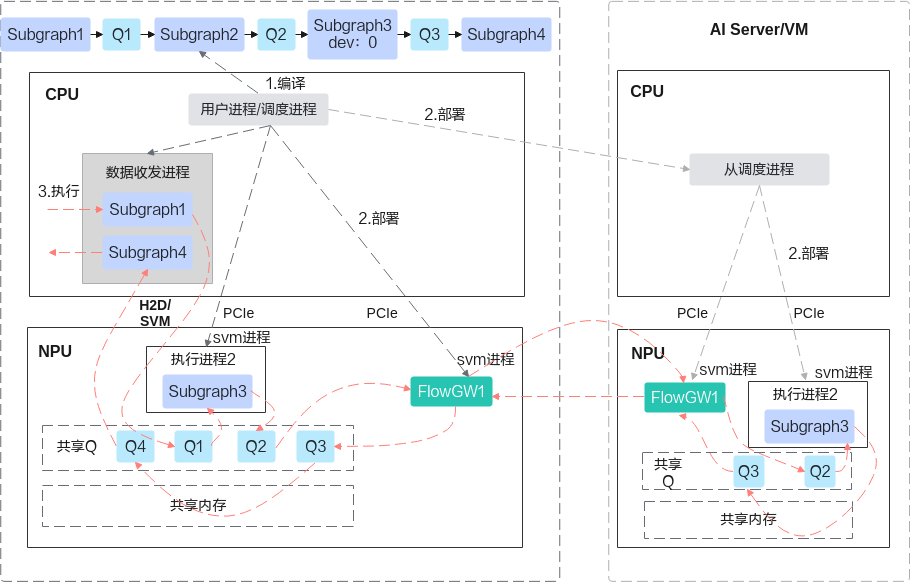
异构Runtime针对CPU、NPU异构节点提供不同的执行器,包括如下。
- CPU图执行器:部署在CPU节点,用于执行计算图。
- NPU图执行器:部署于NPU,用于执行计算图。
- UDF执行器:自定义Func执行引擎,可灵活部署于CPU节点或使用NPU上的AICPU。
各执行器以独立进程方式部署,每个执行进程间采用如下数据通信方式交互数据:在同一节点内采用共享内存、共享队列;跨节点使用RDMA/UB高性能通信。
执行器间数据流的生产、消费关系;1对多分发关系;跨节点数据通信统一由FlowGW(数据流网关)代理并转发。