Atlas 推理系列产品未提供DataCopyPad的接口,需要对搬进和搬出非对齐场景进行处理,如下为不同场景及其处理方式:
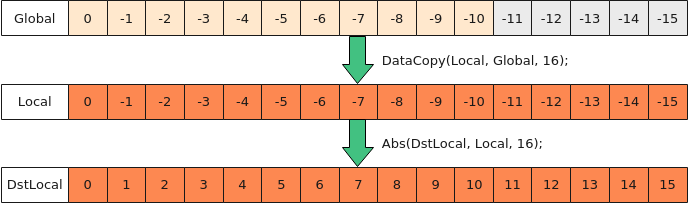
- Global上逐行搬运长度不对齐数据到Local中,导致Local中每行都存在冗余数据
- 冗余数据参与计算
如下图所示,将前11个half数据进行Abs计算,冗余数据可以参与计算,不影响最终结果,该种方式主要用于elemwise计算,这里步骤为:
- 使用DataCopy搬运16个half数据到Local中;
- 直接使用Abs做整块计算,可以不用计算尾块大小。
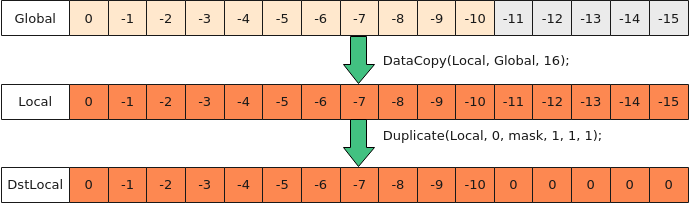
- 使用Mask掩掉脏数据,一般用于轴归约计算等
如下图所示,为将前4个half数据进行ReduceMin计算,有效数据后的冗余数据不能参与到计算中,可以通过在使用ReduceMin API时,设置Mask掩掉脏数据,这里步骤为:
- 使用DataCopy搬运16个half数据到Local中;
- 对归约计算的目的操作数DstLocal清零,如使用Duplicate等;
- 进行归约操作,将ReduceMin的mask模式设置为前4个数据有效,来掩掉对冗余数据区域的处理。
- 搬入Local中,逐行调用高阶API Duplicate,脏数据位置填充0值
如下图所示,对于搬入后的非对齐数据,逐行进行Duplicate清零处理,步骤为:
- 使用DataCopy搬运16个half数据到Local;
- 使用高阶API Duplicate,按照如下方式设置mask值,控制仅后5个元素位置有效,将冗余数据填充为0。
uint64_t mask0 = ((uint64_t)1 << 16) - ((uint64_t)1 << 11); uint64_t mask[2] = {mask0, 0};
- 冗余数据参与计算
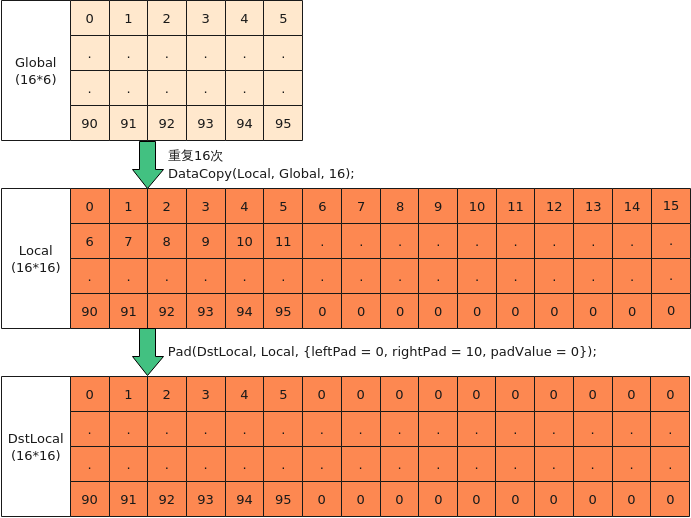
- Global搬运非对齐数据到Local, 逐行搬入后,Pad成0值
如下图所示,将Local内16*16大小的数据库进行脏数据清零,逐行清零性能会很差,可以使用Pad一次性清零,步骤为:
- 将16*6的数据从GM上逐行搬入UB后,每行6个有效数据;
- 与Pad接口的场景2相同,将脏数据位置填充为0;
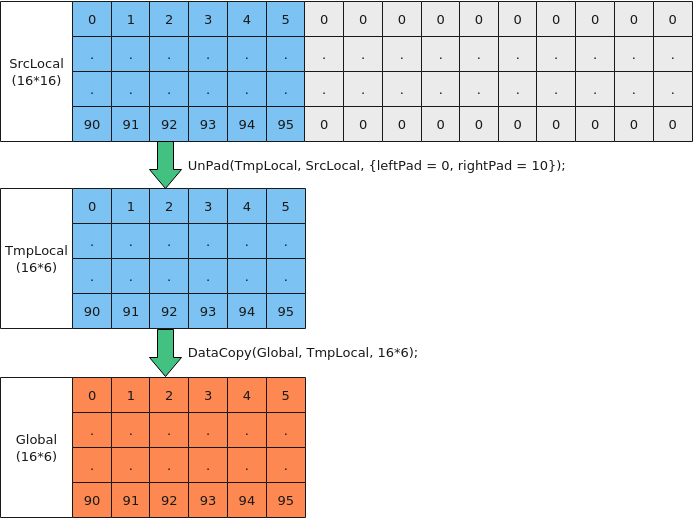
- Local非对齐拷贝出Global,拷贝长度大于32B
- Local中存在冗余数据,如果有效数据为32B整除,使用UnPad接口去除冗余数据并完整搬出
如下图所示,Local内存为16*16, 需要将16*6的有效内存搬到Global中,步骤如下:
- 要搬出的有效数据16*6为32B对齐,可以使用UnPad高阶API去除冗余值;
- 使用DataCopy搬运出连续的16*6个half数据到Global中。
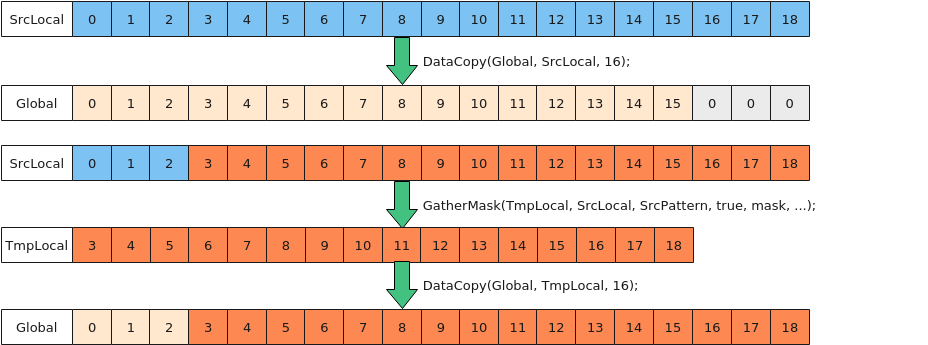
- 使用GatherMask处理
如下图所示,为搬出19个half数据到Global中,使用GatherMask处理,步骤如下:
- 完整拷贝前16个half(32B)数据到Global中;
- 使用GatherMask接口,将SrcLocal[4]~[19]的数Gather到TmpLocal中,TmpLocal从对齐地址开始;
- 从TmpLocal中搬运Gather的数据(32B整数倍)到Global中。
- Local中存在冗余数据,如果有效数据为32B整除,使用UnPad接口去除冗余数据并完整搬出
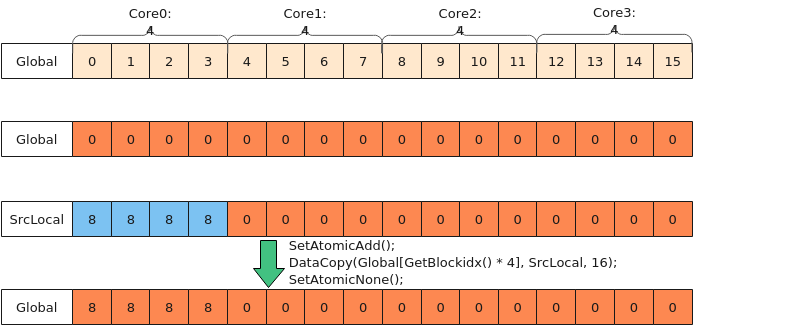
- Local非对齐拷贝出Global, 拷贝长度小于32B
- 将目标Global完整清零,可以通过在HOST清零或者在Kernel侧用UB覆盖的方式处理;
- 将本核内的Local数据,除了要搬出的4个有效数,其余冗余部分清零(使用Duplicate);
- 使用atomic累加的方式拷贝到Global,因为冗余数据已被清成0值,所以不会出现数据踩踏。

调用示例
- 如下代码展示,数据大于32B,图1 冗余数据参与计算和图6 使用GatherMask借位搬运的搬出数据方式。
include "kernel_operator.h" using namespace AscendC; constexpr int32_t BLOCK_BYTE_SIZE = 36; // equivalent to the definition of blockLen of DataCopyPad constexpr int32_t BLOCK_GROUP_NUM = 1; // equivalent to the definition of blockCount of DataCopyPad constexpr int32_t BLOCKLEN_CEIL = (BLOCK_BYTE_SIZE + 32 - 1) / 32 * 32 / sizeof(half); //round up with respect to 32 bytes constexpr int32_t BLOCK_ELEMENT_NUM = BLOCK_BYTE_SIZE / sizeof(half); constexpr int32_t USE_CORE_NUM = 8; // num of core used constexpr int32_t TILE_NUM = 16; // split data into 16 tiles for each core constexpr int32_t BUFFER_NUM = 1; // tensor num for each queue constexpr int32_t TOTAL_LENGTH = USE_CORE_NUM * TILE_NUM * BUFFER_NUM * BLOCK_GROUP_NUM * BLOCK_ELEMENT_NUM; constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / USE_CORE_NUM; constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM; class KernelDataCopyPad { public: __aicore__ inline KernelDataCopyPad() {} __aicore__ inline void Init(GM_ADDR inputGM, GM_ADDR outputGM) { srcGlobal.SetGlobalBuffer((__gm__ half *)(inputGM) + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); dstGlobal.SetGlobalBuffer((__gm__ half *)(outputGM) + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); pipe.InitBuffer(inQueue, BUFFER_NUM, BLOCKLEN_CEIL * sizeof(half)); pipe.InitBuffer(outQueue, BUFFER_NUM, BLOCKLEN_CEIL * sizeof(half)); pipe.InitBuffer(outQueueTail, BUFFER_NUM, 32); pipe.InitBuffer(tmpPattern, 32); } __aicore__ inline void Process() { const int32_t loopCount = TILE_NUM * BUFFER_NUM; for (int32_t i = 0; i < loopCount; i++) { CopyIn(i); Compute(i); CopyOut(i); } } private: __aicore__ inline void CopyIn(int32_t progress) // GM->UB { LocalTensor<half> inputLocal = inQueue.AllocTensor<half>(); for (int i = 0; i < BLOCK_GROUP_NUM; i++) { uint32_t srcGM_idx = progress * TILE_LENGTH + BLOCK_ELEMENT_NUM * i; DataCopy(inputLocal[BLOCKLEN_CEIL * i],srcGlobal[srcGM_idx],BLOCKLEN_CEIL); // each time copy 32 half elements to UB } inQueue.EnQue(inputLocal); } __aicore__ inline void Compute(int32_t progress) { LocalTensor<half> outputLocal = outQueue.AllocTensor<half>(); LocalTensor<half> inputLocal = inQueue.DeQue<half>(); uint32_t calLen = (TILE_LENGTH * sizeof(half) + 32 - 1) / 32 * 32 / sizeof(half); Abs(outputLocal, inputLocal, calLen); // main calculation event_t eventIDMTE3ToV = static_cast<event_t>(GetTPipePtr()->FetchEventID(HardEvent::MTE3_V)); LocalTensor<uint16_t> bufPattern = tmpPattern.Get<uint16_t>(); bufPattern.SetValue(0, 0b1111111111111100); // select the last 14 elements of the first 16 positions bufPattern.SetValue(1, 0b0000000000000011); // select the first 2 elements of the next 16 positions SetFlag<HardEvent::MTE3_V>(eventIDMTE3ToV); // setting Buf_Pattern before doing atomic add WaitFlag<HardEvent::MTE3_V>(eventIDMTE3ToV); uint32_t mask = 128; uint64_t rsvdCnt = 0; LocalTensor<half> tailLocal = outQueueTail.AllocTensor<half>(); GatherMask(tailLocal, outputLocal, bufPattern, true, mask, {1, 1, 8, 8}, rsvdCnt); outQueue.EnQue<half>(outputLocal); outQueueTail.EnQue<half>(tailLocal); inQueue.FreeTensor(inputLocal); } __aicore__ inline void CopyOut(int32_t progress) { LocalTensor<half> outputLocal = outQueue.DeQue<half>(); LocalTensor<half> tailLocal = outQueueTail.DeQue<half>(); uint32_t copyLenMain = TILE_LENGTH * sizeof(half) / 32 * 32 / sizeof(half); uint32_t offsetMain = progress * TILE_LENGTH; DataCopy(dstGlobal[offsetMain], outputLocal, copyLenMain); uint32_t tailLen = 32 / sizeof(half); uint32_t offsetTail = offsetMain + (TILE_LENGTH - tailLen); DataCopy(dstGlobal[offsetTail], tailLocal, tailLen); outQueue.FreeTensor(outputLocal); outQueueTail.FreeTensor(tailLocal); } private: GlobalTensor<half> srcGlobal; GlobalTensor<half> dstGlobal; TPipe pipe; TQue<QuePosition::VECIN, BUFFER_NUM> inQueue; TQue<QuePosition::VECOUT, BUFFER_NUM> outQueue, outQueueTail; TBuf<QuePosition::VECCALC> tmpPattern; }; extern "C" __global__ __aicore__ void datacopypad_custom(GM_ADDR inputGM, GM_ADDR outputGM) { KernelDataCopyPad op; op.Init(inputGM, outputGM); op.Process(); }main.cpp中的特殊处理inputByteSize如下所示。
uint32_t blockDim = 8; // 2304 is TOTAL_LENGTH,TOTAL_LENGTH = USE_CORE_NUM * TILE_NUM * BUFFER_NUM * BLOCK_GROUP_NUM * BLOCK_ELEMENT_NUM; // 2318 is TOTAL_LENGTH + (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) // borrow the next (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) elements of srcGM size_t inputByteSize = 2318 * sizeof(int16_t); size_t outputByteSize = 2304 * sizeof(int16_t);
- 如下代码展示,数据小于32B,参考图3 逐行填充0值的方法逐行将Local上脏数据清零,参考图7 使用atomic累加的方式处理拷贝长度小于32B的场景的搬出数据方式。
#include "kernel_operator.h" using namespace AscendC; constexpr int32_t BLOCK_BYTE_SIZE = 22; //equivalent to the definition of blockLen of DataCopyPad constexpr int32_t BLOCK_GROUP_NUM = 15; //equivalent to the definition of blockCount of DataCopyPad constexpr int32_t BLOCK_ELEMENT_NUM = BLOCK_BYTE_SIZE / sizeof(half); //round up with respect to 32 bytes constexpr int32_t BLOCKLEN_CEIL = 32 / sizeof(half); // since BLOCK_BYTE_SIZE<32 constexpr int32_t USE_CORE_NUM = 4; // num of core used constexpr int32_t TILE_NUM = 1; constexpr int32_t BUFFER_NUM = 1; constexpr int32_t TOTAL_LENGTH = USE_CORE_NUM * TILE_NUM * BUFFER_NUM * BLOCK_GROUP_NUM * BLOCK_ELEMENT_NUM; constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / USE_CORE_NUM; // length computed of each core constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM; // tensor num for each queue class KernelDataCopyPad { public: __aicore__ inline KernelDataCopyPad() {} __aicore__ inline void Init(GM_ADDR inputGM, GM_ADDR outputGM) { srcGlobal.SetGlobalBuffer((__gm__ half *)(inputGM) + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); dstGlobal.SetGlobalBuffer((__gm__ half *)(outputGM) + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); pipe.InitBuffer(inQueue, BUFFER_NUM, BLOCK_GROUP_NUM * BLOCKLEN_CEIL * sizeof(half)); pipe.InitBuffer(outQueue, BUFFER_NUM, BLOCK_GROUP_NUM * BLOCKLEN_CEIL * sizeof(half)); // 32 magic number pipe.InitBuffer(zeroQueue, BUFFER_NUM, 32); } __aicore__ inline void Process() { constexpr int32_t loopCount = TILE_NUM * BUFFER_NUM; for (int32_t i = 0; i < loopCount; i++) { CopyIn(i); Compute(i); CopyOut(i); } } private: __aicore__ inline void CopyIn(int32_t progress) // GM->UB { LocalTensor<half> inputLocal = inQueue.AllocTensor<half>(); for (int i = 0; i < BLOCK_GROUP_NUM; i++) { DataCopy(inputLocal[i * BLOCKLEN_CEIL], srcGlobal[i * BLOCK_ELEMENT_NUM], BLOCKLEN_CEIL); // each time copy 16 half elements to UB } inQueue.EnQue(inputLocal); } __aicore__ inline void Compute(int32_t progress) { LocalTensor<half> outputLocal = outQueue.AllocTensor<half>(); LocalTensor<half> inputLocal = inQueue.DeQue<half>(); LocalTensor<half> zeroTensor = zeroQueue.AllocTensor<half>(); // use local zero tensor to clear dstGM constexpr uint32_t zeroLen = 32 / sizeof(half); Duplicate<half>(zeroTensor, 0, zeroLen); constexpr uint32_t aligneElementSize = 32 / sizeof(half); uint32_t copyLen = BLOCK_ELEMENT_NUM * BLOCK_GROUP_NUM / aligneElementSize * aligneElementSize; // round down 165 -> 160 zeroQueue.EnQue<half>(zeroTensor); zeroTensor = zeroQueue.DeQue<half>(); // clear dstGM before doing calculations event_t eventIDMTE3ToV = static_cast<event_t>(GetTPipePtr()->FetchEventID(HardEvent::MTE3_V)); for (int i = 0; i < copyLen / zeroLen; i++) { DataCopy<half>(dstGlobal[i * zeroLen], zeroTensor, zeroLen); } DataCopy<half>(dstGlobal[BLOCK_ELEMENT_NUM * BLOCK_GROUP_NUM - BLOCKLEN_CEIL], zeroTensor, BLOCKLEN_CEIL); SetFlag<HardEvent::MTE3_V>(eventIDMTE3ToV); WaitFlag<HardEvent::MTE3_V>(eventIDMTE3ToV); //mask mode controls only the last 5 elements doing Duplicate uint64_t mask0 = (1ul << 16) - (1ul << BLOCK_ELEMENT_NUM); uint64_t mask[2] = {mask0, 0}; for (int32_t i = 0; i < BLOCK_GROUP_NUM; i++) { Duplicate<half>(inputLocal[i * BLOCKLEN_CEIL], 0, mask, 1, 1, 1); // clear dummy data on inputLocal } Abs(outputLocal, inputLocal, BLOCKLEN_CEIL * BLOCK_GROUP_NUM); outQueue.EnQue<half>(outputLocal); inQueue.FreeTensor(inputLocal); zeroQueue.FreeTensor(zeroTensor); } __aicore__ inline void CopyOut(int32_t progress) { LocalTensor<half> outputLocal = outQueue.DeQue<half>(); SetAtomicAdd<half>(); for (int32_t i = 0; i < BLOCK_GROUP_NUM; i++) { DataCopy<half>(dstGlobal[i * BLOCK_ELEMENT_NUM], outputLocal[i * BLOCKLEN_CEIL], BLOCKLEN_CEIL); } SetAtomicNone(); outQueue.FreeTensor(outputLocal); } private: GlobalTensor<half> srcGlobal; GlobalTensor<half> dstGlobal; TPipe pipe; TQue<QuePosition::VECIN, BUFFER_NUM> inQueue; TQue<QuePosition::VECOUT, BUFFER_NUM> outQueue; TQue<QuePosition::VECOUT, BUFFER_NUM> zeroQueue; }; extern "C" __global__ __aicore__ void datacopypad_custom(GM_ADDR inputGM, GM_ADDR outputGM) { KernelDataCopyPad op; op.Init(inputGM, outputGM); op.Process(); }main.cpp中的特殊处理inputByteSize和outputByteSize,如下所示。
uint32_t blockDim = 4; //665 is TOTAL_LENGTH + (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) //copy in borrow the next (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) elements of srcGM size_t inputByteSize = 665 * sizeof(int16_t); //copy out atomic add extra (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) zeros to dstGM size_t outputByteSize = 665 * sizeof(int16_t);
- 如下代码展示,数据小于32B,参考图2,使用mask掩掉脏数据,参考图7的搬出数据方式。
#include "kernel_operator.h" using namespace AscendC; constexpr int32_t BLOCK_BYTE_SIZE = 8; //equivalent to the definition of blockLen of DataCopyPad constexpr int32_t BLOCK_GROUP_NUM = 4; //equivalent to the definition of blockCount of DataCopyPad constexpr int32_t BLOCK_ELEMENT_NUM = BLOCK_BYTE_SIZE / sizeof(half); constexpr int32_t BLOCKLEN_CEIL = 32 / sizeof(half); //since BLOCK_BYTE_SIZE<32 constexpr int32_t USE_CORE_NUM = 4; // num of core used constexpr int32_t TILE_NUM = 1; constexpr int32_t BUFFER_NUM = 1; constexpr int32_t TOTAL_LENGTH = USE_CORE_NUM * TILE_NUM * BUFFER_NUM * BLOCK_GROUP_NUM * BLOCK_ELEMENT_NUM; constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / USE_CORE_NUM; // length computed of each core constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM; // tensor num for each queue class KernelDataCopyPad { public: __aicore__ inline KernelDataCopyPad() {} __aicore__ inline void Init(GM_ADDR inputGM, GM_ADDR outputGM){ srcGlobal.SetGlobalBuffer((__gm__ half*)(inputGM) + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); dstGlobal.SetGlobalBuffer((__gm__ half*)(outputGM) + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); pipe.InitBuffer(inQueue, BUFFER_NUM, BLOCK_GROUP_NUM * BLOCKLEN_CEIL*sizeof(half)); pipe.InitBuffer(outQueue, BUFFER_NUM, BLOCK_GROUP_NUM * BLOCKLEN_CEIL*sizeof(half)); pipe.InitBuffer(zeroQueue, BUFFER_NUM, 32); pipe.InitBuffer(workQueue, BUFFER_NUM, 32); } __aicore__ inline void Process() { // loop count need to be doubled, due to double buffer const int32_t loopCount = TILE_NUM * BUFFER_NUM; // tiling strategy, pipeline parallel for (int32_t i = 0; i < loopCount; i++) { CopyIn(i); Compute(i); CopyOut(i); } } private: __aicore__ inline void CopyIn(int32_t progress){ LocalTensor<half> inputLocal = inQueue.AllocTensor<half>(); LocalTensor<half> zeroTensor = zeroQueue.AllocTensor<half>(); for (int i = 0; i < BLOCK_GROUP_NUM; i++){ DataCopy(inputLocal[i*BLOCKLEN_CEIL], srcGlobal[i*BLOCK_ELEMENT_NUM], BLOCKLEN_CEIL); // each time copy 16 half elements to UB } inQueue.EnQue(inputLocal); zeroQueue.EnQue(zeroTensor); } __aicore__ inline void Compute(int32_t progress){ LocalTensor<half> outputLocal = outQueue.AllocTensor<half>(); LocalTensor<half> workLocal = workQueue.AllocTensor<half>(); LocalTensor<half> inputLocal = inQueue.DeQue<half>(); LocalTensor<half> zeroTensor = zeroQueue.DeQue<half>(); Duplicate<half> (zeroTensor, 0, 32/sizeof(half)); //set an all 0 tensor zeroQueue.EnQue(zeroTensor); zeroTensor = zeroQueue.DeQue<half>(); // clear dstGM before doing calculations event_t eventIDMTE3ToV = static_cast<event_t>(GetTPipePtr()->FetchEventID(HardEvent::MTE3_V)); DataCopy<half> (dstGlobal, zeroTensor, TILE_LENGTH); SetFlag<HardEvent::MTE3_V>(eventIDMTE3ToV); WaitFlag<HardEvent::MTE3_V>(eventIDMTE3ToV); outQueue.EnQue<half>(outputLocal); outputLocal = outQueue.DeQue<half>(); Duplicate<half> (outputLocal, 0, BLOCK_GROUP_NUM * BLOCKLEN_CEIL); outQueue.EnQue<half>(outputLocal); outputLocal = outQueue.DeQue<half>(); uint64_t Mask0 = ((uint64_t)1 << BLOCK_ELEMENT_NUM) - 1; //mask mode controls only the first 4 elements do ReduceMin calculation uint64_t Mask[2] = {Mask0, 0}; // main calculation for (int i=0; i<BLOCK_GROUP_NUM; i++){ ReduceMin<half>(outputLocal[i*BLOCKLEN_CEIL], inputLocal[i*BLOCKLEN_CEIL], workLocal, Mask, 1, 8, false); } outQueue.EnQue<half>(outputLocal); inQueue.FreeTensor(inputLocal); workQueue.FreeTensor(workLocal); zeroQueue.FreeTensor(zeroTensor); } __aicore__ inline void CopyOut(int32_t progress){ LocalTensor<half> outputLocal = outQueue.DeQue<half>(); SetAtomicAdd<half>(); for (int i=0; i<BLOCK_GROUP_NUM; i++){ DataCopy<half> (dstGlobal[i*BLOCK_ELEMENT_NUM], outputLocal[i*BLOCKLEN_CEIL], BLOCKLEN_CEIL); } SetAtomicNone(); outQueue.FreeTensor(outputLocal); } private: GlobalTensor<half> srcGlobal; GlobalTensor<half> dstGlobal; TPipe pipe; TQue<QuePosition::VECIN, BUFFER_NUM> inQueue; TQue<QuePosition::VECOUT, BUFFER_NUM> outQueue; TQue<QuePosition::VECOUT, BUFFER_NUM> workQueue; TQue<QuePosition::VECOUT, BUFFER_NUM> zeroQueue; }; extern "C" __global__ __aicore__ void datacopypad_custom(GM_ADDR inputGM, GM_ADDR outputGM){ KernelDataCopyPad op; op.Init(inputGM, outputGM); op.Process(); }main.cpp中的特殊处理inputByteSize和outputByteSize,如下所示。
uint32_t blockDim = 4; //76 is TOTAL_LENGTH + (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) //copy in borrow the next (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) elements of srcGM size_t inputByteSize = 76 * sizeof(int16_t); //copy out atomic add extra (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) zeros to dstGM size_t outputByteSize = 76 * sizeof(int16_t);
- 如下代码展示,数据小于32B,图1和图5的搬出数据方式。
#include "kernel_operator.h" #include "datacopypad_tiling.h" using namespace AscendC; constexpr int32_t BLOCK_BYTE_SIZE = 28; //equivalent to the definition of blockLen of DataCopyPad constexpr int32_t BLOCK_GROUP_NUM = 16; //equivalent to the definition of blockCount of DataCopyPad constexpr int32_t BLOCK_ELEMENT_NUM = BLOCK_BYTE_SIZE / sizeof(half); constexpr int32_t BLOCKLEN_CEIL = 32 / sizeof(half); // since BLOCK_BYTE_SIZE<32 constexpr int32_t USE_CORE_NUM = 8; // num of core used constexpr int32_t TILE_NUM = 8; // split data into 8 tiles for each core constexpr int32_t BUFFER_NUM = 2; // tensor num for each queue constexpr int32_t TOTAL_LENGTH = USE_CORE_NUM * TILE_NUM * BUFFER_NUM * BLOCK_GROUP_NUM * BLOCK_ELEMENT_NUM; constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / USE_CORE_NUM; // length computed of each core constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM; // tensor num for each queue class KernelDataCopyPad { public: __aicore__ inline KernelDataCopyPad() {} __aicore__ inline void Init(GM_ADDR inputGM, GM_ADDR outputGM) { srcGlobal.SetGlobalBuffer((__gm__ half*)(inputGM) + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); dstGlobal.SetGlobalBuffer((__gm__ half*)(outputGM) + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); pipe.InitBuffer(inQueue, BUFFER_NUM, BLOCK_GROUP_NUM * BLOCKLEN_CEIL * sizeof(half)); pipe.InitBuffer(outQueue, BUFFER_NUM, BLOCK_GROUP_NUM * BLOCKLEN_CEIL * sizeof(half)); } __aicore__ inline void Process(DataCopyPadCustomTilingData& tiling) { const int32_t loopCount = TILE_NUM * BUFFER_NUM; for (int32_t i = 0; i < loopCount; i++) { CopyIn(i); Compute(i, tiling); CopyOut(i); } } private: __aicore__ inline void CopyIn(const int32_t progress) { LocalTensor<half> inputLocal = inQueue.AllocTensor<half>(); for (int32_t i = 0; i < BLOCK_GROUP_NUM; i++) { const uint32_t srcGmIdx = progress * BLOCK_ELEMENT_NUM * BLOCK_GROUP_NUM + BLOCK_ELEMENT_NUM * i; DataCopy(inputLocal[BLOCKLEN_CEIL * i], srcGlobal[srcGmIdx], BLOCKLEN_CEIL); } inQueue.EnQue(inputLocal); } __aicore__ inline void Compute(const int32_t progress, DataCopyPadCustomTilingData& tiling) { LocalTensor<half> inputLocal = inQueue.DeQue<half>(); LocalTensor<half> outputLocal = outQueue.AllocTensor<half>(); Abs(inputLocal, inputLocal, BLOCK_GROUP_NUM * BLOCKLEN_CEIL); // main calculation UnPadParams unPadParams; unPadParams.rightPad = BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM; // delete 2 dummy half each row UnPad<half>(outputLocal, inputLocal, unPadParams, tiling.unPadTiling); outQueue.EnQue<half>(outputLocal); inQueue.FreeTensor(inputLocal); } __aicore__ inline void CopyOut(const int32_t progress) { LocalTensor<half> outputLocal = outQueue.DeQue<half>(); DataCopy(dstGlobal[progress * TILE_LENGTH], outputLocal, TILE_LENGTH); outQueue.FreeTensor(outputLocal); } private: GlobalTensor<half> srcGlobal; GlobalTensor<half> dstGlobal; TPipe pipe; TQue<QuePosition::VECIN, BUFFER_NUM> inQueue; TQue<QuePosition::VECOUT, BUFFER_NUM> outQueue; }; extern "C" __global__ __aicore__ void datacopypad_custom(GM_ADDR inputGM, GM_ADDR outputGM, DataCopyPadCustomTilingData tiling) { KernelDataCopyPad op; op.Init(inputGM, outputGM); op.Process(tiling); }tiling.h中注册结构体,如下所示。#include "kernel_tiling/kernel_tiling.h" struct DataCopyPadCustomTilingData { UnPadTiling unPadTiling; }; int32_t GenerateTiling(const std::vector<int64_t> &shape, uint32_t &coreNum,DataCopyPadCustomTilingData &tiling);tiling.cpp文件中根据输入shape、剩余的可供计算的空间大小等信息获取UnPad kernel侧接口所需tiling参数。#include "graph/tensor.h" #include "tiling/tiling_api.h" #include "tiling/platform/platform_ascendc.h" using namespace AscendC; // tbd, whether to use AscendC namespace int32_t GenerateTiling(const std::vector<int64_t>& shape, uint32_t& coreNum, DataCopyPadCustomTilingData& tiling) { platform_ascendc::PlatformAscendC* ascendcPlatform = platform_ascendc::PlatformAscendCManager::GetInstance(); coreNum = 8; ge::Shape srcShape(shape); uint32_t tmpMinSize, tmpMaxSize; GetUnPadMaxMinTmpSize(*ascendcPlatform, srcShape, sizeof(int16_t), tmpMaxSize, tmpMinSize); optiling::UnPadTiling unPadTiling; UnPadTilingFunc(srcShape, tmpMaxSize, sizeof(int16_t), unPadTiling); unPadTiling.SaveToBuffer(&(tiling.unPadTiling), sizeof(tiling.unPadTiling)); return 0; }main.cpp中特殊处理inputByteSize,如下所示。对应的kernel侧在核函数中调用GenerateTiling获取tiling,继而传入UnPad接口参与计算。const std::vector<int64_t> shape({ 16, 16 }); DataCopyPadCustomTilingData tiling; uint32_t blockDim = 8; (void)GenerateTiling(shape, blockDim, tiling); //28674 is TOTAL_LENGTH + (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) //28672 is TOTAL_LENGTH //copy in borrow the next (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) elements of srcGM size_t inputByteSize = 28674 * sizeof(int16_t); size_t outputByteSize = 28672 * sizeof(int16_t); ... ICPU_RUN_KF(datacopypad_custom, blockDim, inputGM, outputGM, tiling);
- 如下代码展示,数据小于32B,图4和图7的搬出数据方式。
#include "datacopypad_tiling.h" #include "kernel_operator.h" using namespace AscendC; constexpr int32_t BLOCK_BYTE_SIZE = 12; //equivalent to the definition of blockLen of DataCopyPad constexpr int32_t BLOCK_GROUP_NUM = 16; //equivalent to the definition of blockCount of DataCopyPad constexpr int32_t BLOCK_ELEMENT_NUM = BLOCK_BYTE_SIZE / sizeof(half); constexpr int32_t BLOCKLEN_CEIL = 32 / sizeof(half); // since BLOCK_BYTE_SIZE<32 constexpr int32_t USE_CORE_NUM = 8; // num of core used constexpr int32_t TILE_NUM = 16; // split data into 16 tiles for each core constexpr int32_t BUFFER_NUM = 1; // tensor num for each queue constexpr int32_t TOTAL_LENGTH = USE_CORE_NUM * TILE_NUM * BUFFER_NUM * BLOCK_GROUP_NUM * BLOCK_ELEMENT_NUM; constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / USE_CORE_NUM; // length computed of each core constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM; class KernelDataCopyPad { public: __aicore__ inline KernelDataCopyPad() {} __aicore__ inline void Init(GM_ADDR inputGM, GM_ADDR outputGM) { srcGlobal.SetGlobalBuffer((__gm__ half *)(inputGM) + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); dstGlobal.SetGlobalBuffer((__gm__ half *)(outputGM) + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); pipe.InitBuffer(inQueue, BUFFER_NUM, BLOCK_GROUP_NUM * BLOCKLEN_CEIL * sizeof(half)); pipe.InitBuffer(outQueue, BUFFER_NUM, BLOCK_GROUP_NUM * BLOCKLEN_CEIL * sizeof(half)); pipe.InitBuffer(zeroQueue, BUFFER_NUM, 32); } __aicore__ inline void Process(CopyInTilingData& tilingData) { const int32_t loopCount = TILE_NUM * BUFFER_NUM; for (int32_t i = 0; i < loopCount; i++) { CopyIn(i); Compute(i, tilingData); CopyOut(i); } } private: __aicore__ inline void CopyIn(int32_t progress) { LocalTensor<half> inputLocal = inQueue.AllocTensor<half>(); for (int32_t i = 0; i < BLOCK_GROUP_NUM; i++) { const uint32_t srcGmIdx = progress * TILE_LENGTH + BLOCK_ELEMENT_NUM * i; DataCopy(inputLocal[BLOCKLEN_CEIL * i], srcGlobal[srcGmIdx], BLOCKLEN_CEIL); } inQueue.EnQue(inputLocal); } __aicore__ inline void Compute(int32_t progress, CopyInTilingData& tilingData) { LocalTensor<half> inputLocal = inQueue.DeQue<half>(); LocalTensor<half> outputLocal = outQueue.AllocTensor<half>(); PadParams padParams; padParams.leftPad = 0; //change the last 2 elements of each row to 0 padParams.rightPad = BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM; padParams.padValue = 0; Pad<half>(outputLocal, inputLocal, padParams, tilingData.padtiling); LocalTensor<half> zeroTensor = zeroQueue.AllocTensor<half>(); outQueue.EnQue<half>(outputLocal); zeroQueue.EnQue<half>(zeroTensor); inQueue.FreeTensor(inputLocal); } __aicore__ inline void CopyOut(int32_t progress) { LocalTensor<half> zeroTensor = zeroQueue.DeQue<half>(); // setting zero_tensor to before copying to dstGM event_t eventIDVToMTE3 = static_cast<event_t>(GetTPipePtr()->FetchEventID(HardEvent::V_MTE3)); constexpr uint32_t zeroLen = 32 / sizeof(half); Duplicate<half>(zeroTensor, 0, zeroLen); // set all 0 tensor SetFlag<HardEvent::V_MTE3>(eventIDVToMTE3); WaitFlag<HardEvent::V_MTE3>(eventIDVToMTE3); // // clear dstGM before doing calculations event_t eventIDMTE3ToV = static_cast<event_t>(GetTPipePtr()->FetchEventID(HardEvent::MTE3_V)); constexpr uint32_t rowNum = TILE_LENGTH / zeroLen; for (int32_t i = 0; i < rowNum; i++) { DataCopy<half>(dstGlobal[progress * TILE_LENGTH + i * zeroLen], zeroTensor, zeroLen); } SetFlag<HardEvent::MTE3_V>(eventIDMTE3ToV); WaitFlag<HardEvent::MTE3_V>(eventIDMTE3ToV); LocalTensor<half> outputLocal = outQueue.DeQue<half>(); Abs(outputLocal, outputLocal, BLOCK_GROUP_NUM * BLOCKLEN_CEIL); // main calculation outQueue.EnQue<half>(outputLocal); outputLocal = outQueue.DeQue<half>(); SetAtomicAdd<half>(); for (int32_t i = 0; i < BLOCK_GROUP_NUM; i++) { const uint32_t srcGmIdx = progress * TILE_LENGTH + i * BLOCK_ELEMENT_NUM; DataCopy<half>(dstGlobal[srcGmIdx], outputLocal[i * BLOCK_GROUP_NUM], BLOCKLEN_CEIL); } SetAtomicNone(); outQueue.FreeTensor(outputLocal); zeroQueue.FreeTensor(zeroTensor); } private: GlobalTensor<half> srcGlobal; GlobalTensor<half> dstGlobal; TPipe pipe; TQue<QuePosition::VECIN, BUFFER_NUM> inQueue; TQue<QuePosition::VECOUT, BUFFER_NUM> outQueue; TQue<QuePosition::VECOUT, BUFFER_NUM> zeroQueue; }; extern "C" __global__ __aicore__ void datacopypad_custom(GM_ADDR inputGM, GM_ADDR outputGM, CopyInTilingData tilingData) { KernelDataCopyPad op; op.Init(inputGM, outputGM); op.Process(tilingData); }tiling.h中注册结构体,如下所示。#include "kernel_tiling/kernel_tiling.h" struct CopyInTilingData { PadTiling padtiling; }; int32_t GenerateTiling(const std::vector<int64_t>& shapePad, const std::vector<int64_t>& shapeUsed, uint32_t& coreNum, CopyInTilingData& structTilingPad);tiling.cpp文件中的函数GenerateTiling根据输入shape、剩余的可供计算的空间大小等信息获取Pad kernel侧接口所需tiling参数。#include "graph/tensor.h" #include "tiling/tiling_api.h" #include "tiling/platform/platform_ascendc.h" using namespace AscendC; int32_t GenerateTiling(const std::vector<int64_t> &shapePad, const std::vector<int64_t> &shapeUsed, uint32_t &coreNum, CopyInTilingData &structTilingPad) { coreNum = 8; ge::Shape srcShape(shapePad); ge::Shape oriSrcShape(shapeUsed); uint32_t tmpMinSize, tmpMaxSize; GetPadMaxMinTmpSize(srcShape, sizeof(int16_t), tmpMaxSize, tmpMinSize); optiling::PadTiling padtiling; PadTilingFunc(srcShape, oriSrcShape, tmpMaxSize, sizeof(int16_t), padtiling); padtiling.SaveToBuffer(&(structTilingPad.padtiling), sizeof(structTilingPad.padtiling)); return 0; }main.cpp中的特殊处理inputByteSize,outputByteSize,如下所示。对应的kernel侧在核函数中调用GenerateTiling获取structTilingPad,继而传入Pad接口参与计算。
const std::vector<int64_t> shapeUsed({16, 6}); //shape of valid data const std::vector<int64_t> shapePad({16, 16}); //original shape CopyInTilingData structTilingPad; uint32_t blockDim = 8; (void)GenerateTiling(shapePad, shapeUsed, blockDim, structTilingPad); //12298 is TOTAL_LENGTH + (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) //copy in borrow the next (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) elements of srcGM size_t inputByteSize = 12298 * sizeof(int16_t); //copy out atomic add extra (BLOCKLEN_CEIL - BLOCK_ELEMENT_NUM) zeros to dstGM size_t outputByteSize = 12298 * sizeof(int16_t); ... ICPU_RUN_KF(datacopypad_custom, blockDim, inputGM, outputGM, structTilingPad);