前提条件
已在环境上安装CANN、PyTorch、Torch-NPU和ATB Models,详情请参见《MindIE安装指南》。

本次样例参考以下安装路径进行:
安装ATB Models并初始化ATB Models环境变量。模型仓set_env.sh脚本中有初始化“${ATB_SPEED_HOME_PATH}”环境变量的操作,所以source模型仓中set_env.sh脚本时会同时初始化“${ATB_SPEED_HOME_PATH}”环境变量。
约束
- 使用ATB Models进行推理,模型初始化失败时,模型初始过程中用户自定义修改导致的失败,需要手动结束进程。
- 使用ATB Models进行推理,权重路径及文件的权限需保证其他用户无写权限。
Readme文档解读
当前ATB Models包含三类Readme文档指导您执行推理流程,了解模型支持特性以及提供基础的调测和问题定位手段。
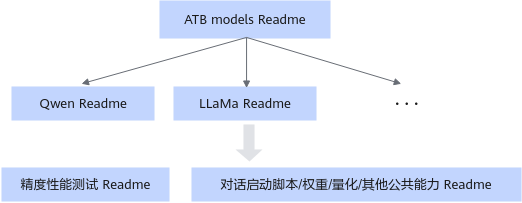
文档名称 |
作用 |
内容 |
|---|---|---|
“${ATB_SPEED_HOME_PATH}/README.md” |
为ATB Models所有文档的总入口。 |
|
“${ATB_SPEED_HOME_PATH}/examples/models/{模型名称}/README.md” |
为ATB Models每个模型各自的文档,例如:“${ATB_SPEED_HOME_PATH}/examples/models/llama/README.md”中为LLaMA模型的文档,其中涵盖了LLaMA系列和LLaMA2系列模型的介绍和运行指导。 |
|
“${ATB_SPEED_HOME_PATH}/examples/README.md” |
汇总了对于公共能力和接口的介绍。 |
|
“${ATB_SPEED_HOME_PATH}/tests/modeltest/README.md” |
ModelTest为大模型的性能和精度提供测试功能。 |
|
使用示例
下面以LLaMA2-7B模型为例,展示对话推理以及性能测试的执行步骤。
- 配置环境变量。
1 2 3 4 5 6
# 配置CANN环境,默认安装在/usr/local目录下 source /usr/local/Ascend/ascend-toolkit/set_env.sh # 配置加速库环境 source /usr/local/Ascend/nnal/atb/set_env.sh # 配置模型仓环境变量 source /usr/local/Ascend/llm_model/set_env.sh
- 准备模型权重:可从Hugging Face官网直接下载,将下载的权重保存在“/data/Llama-2-7b-hf”。
- (可选)当前ATB Models推理仅支持加载safetensor格式的权重文件。若下载的权重文件是safetensor格式文件,则无需进行权重转换,若下载的权重文件是bin格式文件,则需要按照如下方式进行转换。
1 2 3 4
# 进入ATB Models 所在路径 cd ${ATB_SPEED_HOME_PATH} # 执行脚本生成safetensor格式的权重 python examples/convert/convert_weights.py --model_path /data/Llama-2-7b-hf
输出结果会保存在bin格式的权重文件同目录下。
- 测试对话推理。
1 2
cd ${ATB_SPEED_HOME_PATH} bash examples/models/llama/run_pa.sh /data/Llama-2-7b-hf
如上命令调用的run_pa.sh脚本是对run_pa.py脚本的封装,默认推理内容为"What's deep learning?",batch size为1,可以通过5修改推理内容。
- 自定义推理内容。
- 用户可以通过以下方式直接调用run_pa.py脚本,通过传入参数的方式自定义推理内容及推理方式。
例如:使用/data/Llama-2-7b-hf路径下的权重,使用8卡推理"What's deep learning?"和"Hello World.",推理时batch size为2。
1 2 3 4
# 指定当前机器上可用的逻辑NPU核心,多个核心间使用逗号相连 export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 # 执行推理 torchrun --nproc_per_node 8 --master_port 20030 -m examples.run_pa --model_path /data/Llama-2-7b-hf --input_texts "What's deep learning?" "Hello World." --max_batch_size 2
- 用户可以通过传入Token id的方式进行推理。
新建一个py脚本(如test.py)用于生成Token id:
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained( pretrained_model_name_or_path="{tokenizer所在的文件夹路径}", use_fast=False, padding_side='left', trust_remote_code="{用户输入的trust_remote_code值}") inputs = tokenizer("What's deep learning?", return_tensors="pt") token_id = inputs.data["input_ids"] print(token_id)执行如下命令,生成Token id:
python test.py
执行如下命令进行推理,如下以生成的第一个推理内容对应的Token id为"1,15043,2787",第二个推理内容对应的Token id为"1,306,626,2691"为例,其中推理内容间以空格分开。# 执行推理 torchrun --nproc_per_node 8 --master_port 20030 -m examples.run_pa --model_path /data/Llama-2-7b-hf --input_ids 1,15043,2787 1,306,626,2691 --max_batch_size 2
表2 run_pa.py脚本参数说明 参数名称
是否为必选
类型
默认值
描述
--model_path
是
string
""
模型权重路径。
该路径会进行安全校验,必须使用绝对路径,且和执行推理用户的属组和权限保持一致。
--input_texts
否
string
"What's deep learning?"
推理文本或推理文本路径,多条推理文本间使用空格分割。
--input_ids
否
string
None
推理文本经过模型分词器处理后得到的token id列表,多条推理请求间使用空格分割,单个推理请求内每个token使用逗号隔开。
--input_file
否
string
None
仅支持jsonl格式文件,每一行必须为List[Dict]格式的按时间顺序排序的对话数据,每个Dict字典中需要至少包含"role"和"content"两个字段。
--input_dict
否
parse_list_of_json
None
推理文本以及对应的adapter名称。格式形如:'[{"prompt": "A robe takes 2 bolts of blue fiber and half that much white fiber. How many bolts in total does it take?", "adapter": "adapter1"}, {"prompt": "What is deep learning?", "adapter": "base"}]'
--max_prefill_batch_size
否
int或者None
None
模型推理最大Prefill Batch Size。
--max_position_embeddings
否
int或者None
None
模型可接受的最大上下文长度。当此值为None时,则从模型权重文件中读取。
--max_input_length
否
int
1024
推理文本最大token数。
--max_output_length
否
int
20
推理结果最大token数。
--max_prefill_tokens
否
int
-1
模型Prefill推理阶段最大可接受的token数。若输入为-1,则max_prefill_tokens = max_batch_size * (max_input_length + max_output_length)
--max_batch_size
否
int
1
模型推理最大batch size。
--block_size
否
int
128
KV Cache分块存储,每块存储的最大token数,默认为128。
--chat_template
否
string或者None
None
对话模型的prompt模板。
--ignore_eos
否
bool
store_true
当推理结果中遇到eos token(句子结束标识符)时,是否结束推理。若传入此参数,则忽略eos token。
--is_chat_model
否
bool
store_true
是否支持对话模式。若传入此参数,则进入对话模式。
--is_embedding_model
否
bool
store_true
是否为embedding类模型。默认为因果推断类模型,若传入此参数,则为embedding类模型。
--load_tokenizer
否
bool
True
是否加载tokenizer。若传入False,则必须传入input_ids参数,且推理输出为token id。
--enable_atb_torch
否
bool
store_true
是否使用Python组图。默认使用C++组图,若传入此参数,则使用Python组图。
--kw_args
否
string
""
扩展参数,支持用户通过扩展参数进行功能扩展。
--trust_remote_code
否
bool
store_true
是否信任模型权重路径下的自定义代码文件。默认不执行。若传入此参数,则transformers会执行用户权重路径下的自定义代码文件,这些代码文件的功能的安全性需由用户保证,请提前做好安全性检查。
此章节中的run_pa.py脚本用于纯模型快速测试,脚本中未增加强校验,出现异常情况时,会直接抛出异常信息。例如:
- input_texts、input_ids、input_file、input_dict参数包含推理内容,程序进行数据处理的时间和传入数据量成正比。同时这些输入会被转换成token id搬运至NPU,传入数据量过大可能会导致这些NPU tensor占用显存过大,而出现由out of memory导致的报错信息,例如:"req: xx input length: xx is too long, max_prefill_tokens: xx"等报错信息。
- chat_template参数可以使用两种形式输入:模板文本或模板文件的路径。当以模板文本输入时,若文本长度过大,可能会导致运行缓慢。
- 脚本会基于max_batch_size、max_input_length、max_output_length、max_prefill_batch_size和max_prefill_tokens等参数申请推理输入及KV Cache,若用户传入数值过大,会出现由out of memory导致的报错信息,例如:"RuntimeError: NPU out of memory. Tried to allocate xxx GiB."。
- 脚本会基于max_position_embeddings参数,申请旋转位置编码和attention mask等NPU tensor,若用户传入数值过大,会出现由out of memory导致的报错信息,例如:"RuntimeError: NPU out of memory. Tried to allocate xxx GiB."。
- block_size参数若小于张量并行场景下每张卡实际分到的注意力头个数,会出现由shape不匹配导致的报错("Setup fail, enable log: export ASDOPS_LOG_LEVEL=ERROR, export ASDOPS_LOG_TO_STDOUT=1 to find the first error. For more details, see the MindIE official document."),需开启日志查看详细信息。
- 用户可以通过以下方式直接调用run_pa.py脚本,通过传入参数的方式自定义推理内容及推理方式。
- 测试性能。开启ATB_LLM_BENCHMARK_ENABLE环境变量后,将统计模型首Token、增量Token及端到端推理时延。
# 环境变量开启方式 export ATB_LLM_BENCHMARK_ENABLE=1 # 启动推理方式见步骤4、步骤5
耗时结果会显示在Console中,并保存在./benchmark_result/benchmark.csv文件里。