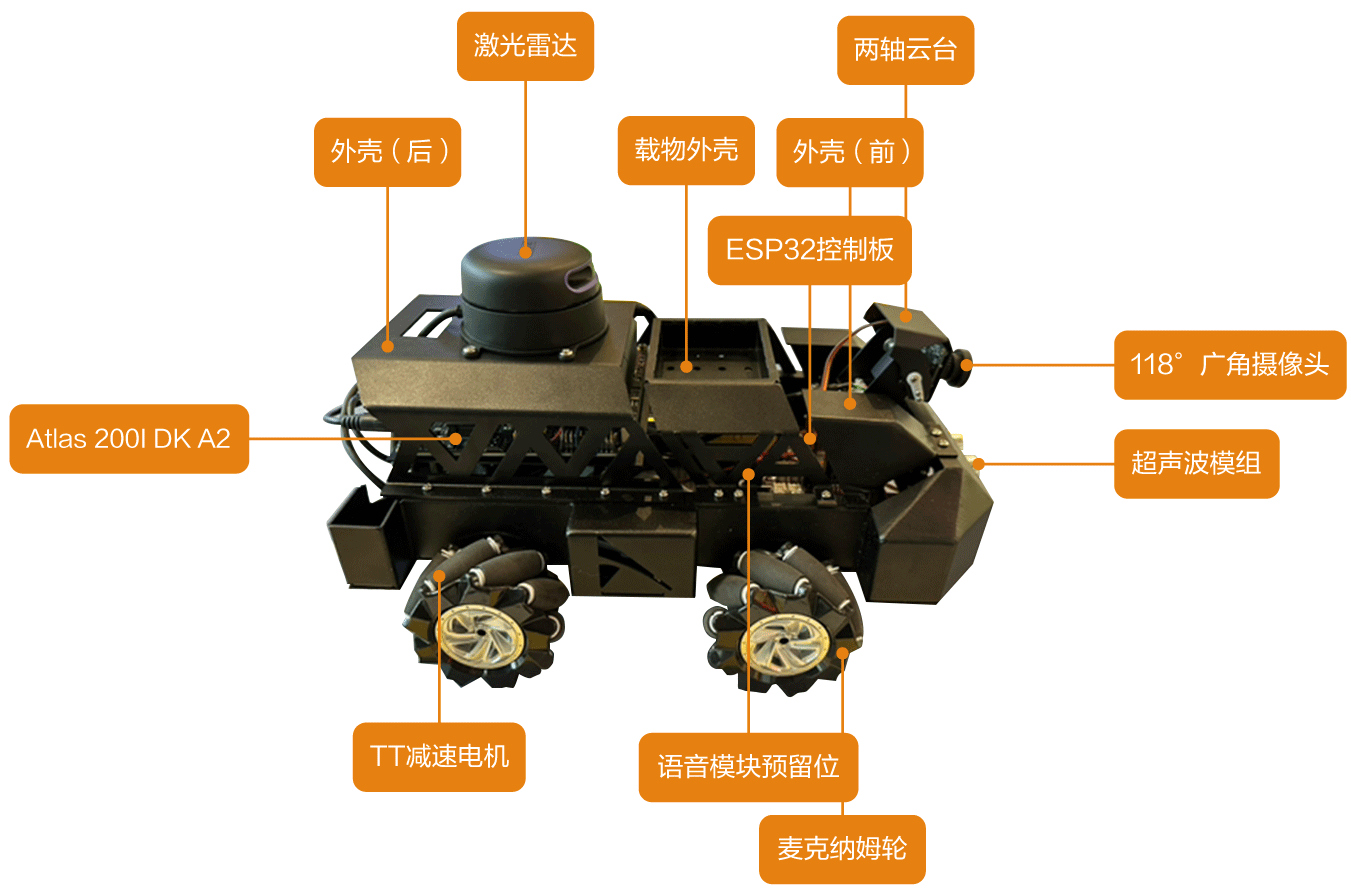
返回顶部 外观结构 小车的主要组成模块包括: 前中后外壳结构支撑模块。 TT减速电机与麦克纳姆轮的运动模块。 电源供电模块。 ESP32控制模块。 广角摄像头视觉感知模块。 激光雷达点云感知模块。 Atlas 200I DK A2开发者套件。 图1 小车外观结构图 图2 正面图 图3 俯视图 父主题: 样例介绍