DropOut
函数功能
提供根据MaskTensor对SrcTensor(源操作数,输入Tensor)进行过滤的功能,得到DstTensor(目的操作数、输出Tensor)。仅支持输入shape为ND格式。
该过滤功能包括两种模式,字节模式和比特模式。
- 字节模式
MaskTensor中存储的数值为布尔类型,每个布尔数值代表是否取用SrcTensor对应位置的数值:如果是,则选取SrcTensor中的数值存入DstTensor;否则,对DstTensor中的对应位置赋值为零。DstTensor,SrcTensor和MaskTensor的shape相同。示例如下:
SrcTensor=[1,2,3,4,5,6,7,8,9,10]
MaskTensor=[1,0,1,0,1,0,0,1,1,0](每个数的数据类型为uint8_t)
DstTensor=[1,0,3,0,5,0,0,8,9,0]
- 比特模式
MaskTensor的每个bit数值,代表是否取用SrcTensor对应位置的数值:如果是,则选取SrcTensor中的数值存入DstTensor;否则,对DstTensor中的对应位置赋值为零。SrcTensor和DstTensor的shape相同,假设均为[height , width],MaskTensor的shape为[height , (width / 8)]。示例如下:
SrcTensor=[1,2,3,4,5,6,7,8]
MaskTensor=[169](转换为二进制表示为1010 1001)
DstTensor=[1,0,3,0,5,0,0,8]
- 特殊情况1:当MaskTensor有效数据非连续存放时,MaskTensor的width轴,为了满足32B对齐,需要填充无效数值,SrcTensor的width轴,需满足32Byte对齐。示例如下:
SrcTensor=[1,2,3,4,5,6,7,8,11,12,13,14,15,16,17,18]
MaskTensor=[1,0,1,0,1,0,0,1,X,X,1,0,1,0,1,0,0,1,X,X](X为无效数值,假设数据已满足对齐要求,示例数值为二进制形式表示)
DstTensor=[1,0,3,0,5,0,0,8,11,0, 13, 0, 15, 0, 0,18]
- 特殊情况2:当MaskTensor有效数据连续存放,maskTensor_size不满足32B对齐时,需要在MaskTensor的尾部补齐32B对齐时,对应SrcTensor的尾部也需要补充无效数据,使得srcTensor_size满足32B对齐。示例如下:
SrcTensor=[1,2,3,4,5,6,7,8,11,12,13,14,15,16,17,18]
MaskTensor=[1,0,1,0,1,0,0,1, 1, 0, 1, 0, 1, 0, 0, 1,X,X,X,X](X为无效数值,假设数据已满足对齐要求,示例数值为二进制形式表示)
DstTensor= [1,0,3,0,5,0,0,8, 11, 0, 13, 0, 15, 0, 0, 18]
- 特殊情况1:当MaskTensor有效数据非连续存放时,MaskTensor的width轴,为了满足32B对齐,需要填充无效数值,SrcTensor的width轴,需满足32Byte对齐。示例如下:
实现原理
以float类型,ND格式,shape为[srcM, srcN]的SrcTensor,shape为[maskM, maskN]的MaskTensor,比特模式场景为例,描述Dropout高阶API内部算法框图,如下图所示。
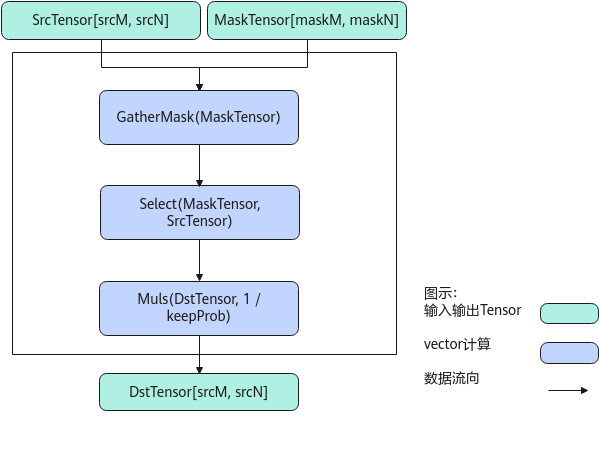
计算过程分为如下几步,均在Vector上进行:
- GatherMask步骤:对输入的MaskTensor做脏数据清理,使得MaskTensor中只保留有效数据;
- Select步骤:根据输入的MaskTensor对SrcTensor做数据选择,被选中的数据位置,保留原始数据,对舍弃的数据位置,设置为0;
- Muls步骤:将输出数据每个元素除以keepProb。
函数原型
1 2 |
template <typename T, bool isInitBitMode = false, uint32_t dropOutMode = 0> __aicore__ inline void DropOut(const LocalTensor<T>& dstLocal, const LocalTensor<T>& srcLocal, const LocalTensor<uint8_t>& maskLocal, const float keepProb, const DropOutShapeInfo& info) |
1 2 |
template <typename T, bool isInitBitMode = false, uint32_t dropOutMode = 0> __aicore__ inline void DropOut(const LocalTensor<T>& dstLocal, const LocalTensor<T>& srcLocal, const LocalTensor<uint8_t>& maskLocal, const LocalTensor<uint8_t>& sharedTmpBuffer, const float keepProb, const DropOutShapeInfo& info) |
参数说明
|
参数名 |
描述 |
|---|---|
|
T |
操作数的数据类型。 |
|
isInitBitMode |
在比特模式下,是否需要在接口内部初始化(默认false)。 |
|
dropOutMode |
选择执行何种输入场景: 0:默认值,由接口根据输入shape推断运行模式,注意,推断不符合预期的场景,需设置对应模式 1:执行字节模式,且maskLocal含有脏数据 2:执行字节模式,且maskLocal不含有脏数据 3:执行比特模式,且maskLocal不含有脏数据 4:执行比特模式,且maskLocal含有脏数据 |
|
参数名称 |
输入/输出 |
含义 |
|---|---|---|
|
dstLocal |
输出 |
目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
|
srcLocal |
输入 |
源操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 srcLocal的数据类型需要与目的操作数保持一致。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
|
maskLocal |
输入 |
存放mask的Tensor。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint8_t Atlas推理系列产品AI Core,支持的数据类型为:uint8_t |
|
sharedTmpBuffer |
输入 |
共享缓冲区,用于存放API内部计算产生的临时数据。该方式开发者可以自行管理sharedTmpBuffer内存空间,并在接口调用完成后,复用该部分内存。Tensor的大小应符合对应tiling的要求,配合tiling一起使用。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint8_t Atlas推理系列产品AI Core,支持的数据类型为:uint8_t |
|
keepProb |
输入 |
权重系数,srcLocal中数据被保留的概率,过滤后的结果会除以权重系数,存放至dstLocal中。 keepProb∈(0,1) Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:float Atlas推理系列产品AI Core,支持的数据类型为:float |
|
info |
输入 |
DropOutShapeInfo类型,DropOutShapeInfo结构定义如下: struct DropOutShapeInfo {
__aicore__ DropOutShapeInfo(){};
uint32_t firstAxis = 0; // srcLocal/maskTensor的height轴元素个数
uint32_t srcLastAxis = 0; // srcLocal的width轴元素个数
uint32_t maskLastAxis = 0;// maskTensor的width轴元素个数(如有数据补齐场景,则为带有脏数据的长度,注意,所有模式的元素个数均为对应Tensor类型下的个数,如uint8类型Tensor对应Uint8类型元素个数)
}; |
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
约束说明
- srcTensor和dstTensor的Tensor空间可以复用。
- srcLocal和dstLocal地址对齐要求请见 :通用约束。
- 仅支持输入shape为ND格式。
- maskLocal含有脏数据的场景,要求info.maskLastAxis中有效数值的个数,应为2的整数倍。
- maskLocal含有脏数据的场景,maskLocal中的数据可能会被修改,脏数据可能会被舍弃。
调用示例
#include "kernel_operator.h"
template <typename srcType>
class KernelDropout {
public:
__aicore__ inline KernelDropout()
{}
__aicore__ inline void Init(GM_ADDR srcGm, GM_ADDR maskGm, GM_ADDR dstGm, uint32_t firstAxis, uint32_t srcLastAxis,
uint32_t maskLastAxis, uint32_t tmpBufferSize)
{
srcSize = firstAxis * srcLastAxis;
maskSize = firstAxis * maskLastAxis;
info.firstAxis = firstAxis;
info.srcLastAxis = srcLastAxis;
info.maskLastAxis = maskLastAxis;
srcGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ srcType *>(srcGm), srcSize);
maskGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ uint8_t *>(maskGm), maskSize);
dstGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ srcType *>(dstGm), srcSize);
pipe.InitBuffer(inQueueX, 1, srcSize * sizeof(srcType));
pipe.InitBuffer(inQueueY, 1, maskSize * sizeof(uint8_t));
pipe.InitBuffer(outQueue, 1, srcSize * sizeof(srcType));
pipe.InitBuffer(tmpQueue, 1, tmpBufferSize);
}
__aicore__ inline void Process()
{
CopyIn();
Compute();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
AscendC::LocalTensor<srcType> srcLocal = inQueueX.AllocTensor<srcType>();
AscendC::LocalTensor<uint8_t> maskLocal = inQueueY.AllocTensor<uint8_t>();
AscendC::DataCopy(srcLocal, srcGlobal, srcSize);
AscendC::DataCopy(maskLocal, maskGlobal, maskSize);
inQueueX.EnQue(srcLocal);
inQueueY.EnQue(maskLocal);
}
__aicore__ inline void Compute()
{
AscendC::LocalTensor<srcType> dstLocal = outQueue.AllocTensor<srcType>();
AscendC::LocalTensor<uint8_t> sharedTmpBuffer = tmpQueue.AllocTensor<uint8_t>();
AscendC::LocalTensor<srcType> srcLocal = inQueueX.DeQue<srcType>();
AscendC::LocalTensor<uint8_t> maskLocal = inQueueY.DeQue<uint8_t>();
AscendC::DropOut(dstLocal, srcLocal, maskLocal, sharedTmpBuffer, probValue, info);
outQueue.EnQue<srcType>(dstLocal);
inQueueX.FreeTensor(srcLocal);
inQueueY.FreeTensor(maskLocal);
tmpQueue.FreeTensor(sharedTmpBuffer);
}
__aicore__ inline void CopyOut()
{
AscendC::LocalTensor<srcType> dstLocal = outQueue.DeQue<srcType>();
AscendC::DataCopy(dstGlobal, dstLocal, srcSize);
outQueue.FreeTensor(dstLocal);
}
private:
AscendC::GlobalTensor<srcType> srcGlobal;
AscendC::GlobalTensor<uint8_t> maskGlobal;
AscendC::GlobalTensor<srcType> dstGlobal;
AscendC::TPipe pipe;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueX;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueY;
AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueue;
AscendC::TQue<AscendC::QuePosition::VECCALC, 1> tmpQueue;
uint32_t srcSize = 0;
uint32_t maskSize = 0;
float probValue = 0.8;
AscendC::DropOutShapeInfo info;
};
extern "C" __global__ __aicore__ void kernel_dropout_operator(
GM_ADDR srcGm, GM_ADDR maskGm, GM_ADDR dstGm, GM_ADDR tiling)
{
GET_TILING_DATA(tilingData, tiling);
KernelDropout<half> op;
op.Init(srcGm,
maskGm,
dstGm,
tilingData.firstAxis,
tilingData.srcLastAxis,
tilingData.maskLastAxis,
tilingData.tmpBufferSize);
op.Process();
}