ConfusionTranspose
功能说明
对输入数据进行数据排布及Reshape操作,具体功能如下:
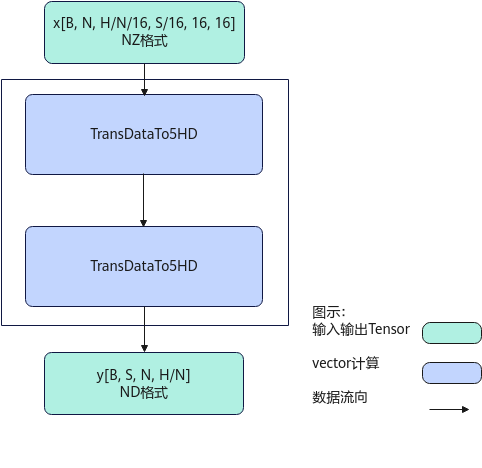
【场景1:NZ2ND,1、2轴互换】
输入Tensor { shape:[B, N, H/N/16, S/16, 16, 16], origin_shape:[B, N, S, H/N], format:"NZ", origin_format:"ND"}
输出Tensor { shape:[B, S, N, H/N], origin_shape:[B, S, N, H/N], format:"ND", origin_format:"ND"}
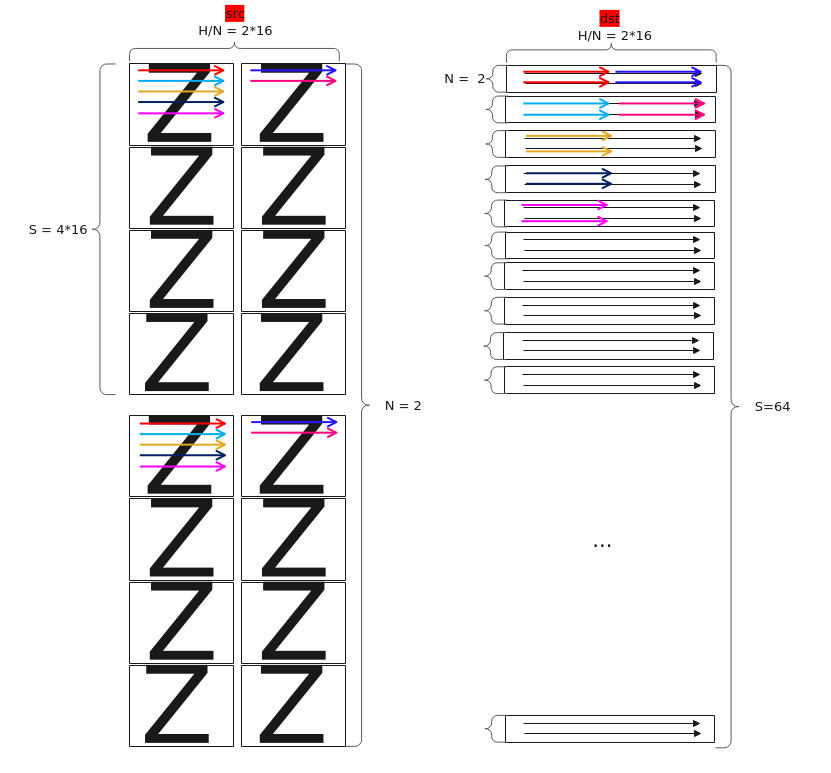
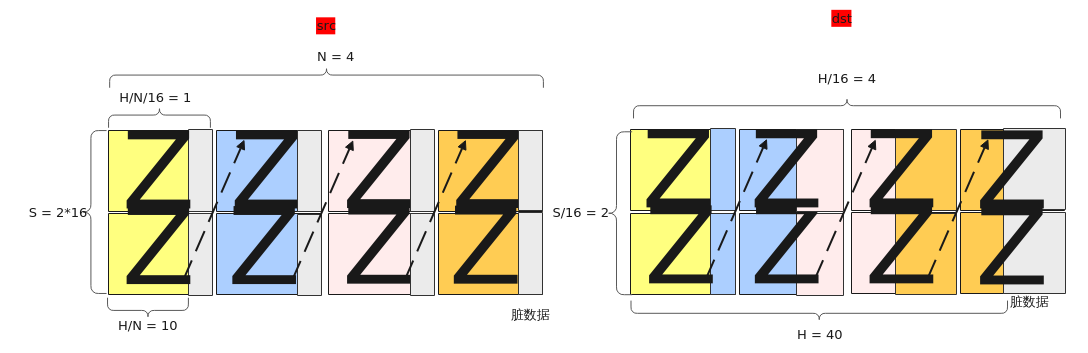
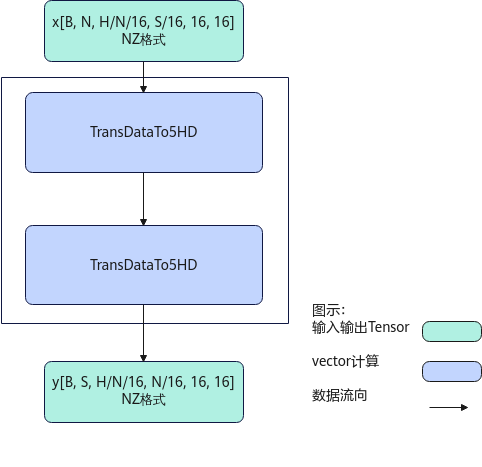
【场景2:NZ2NZ,1、2轴互换】
输入Tensor { shape:[B, N, H/N/16, S/16, 16, 16], origin_shape:[B, N, S, H/N], format:"NZ", origin_format:"ND"}
输出Tensor { shape:[B, S, H/N/16, N/16, 16, 16], origin_shape:[B, S, N, H/N], format:"NZ", origin_format:"ND"}
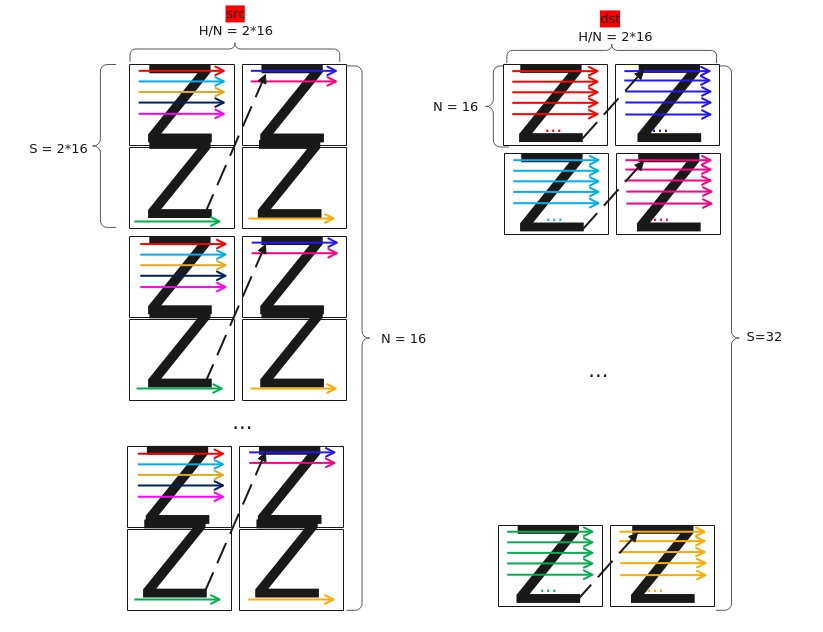
【场景3:NZ2NZ,尾轴切分】
输入Tensor { shape:[B, H / 16, S / 16, 16, 16], origin_shape:[B, S, H], format:"NZ", origin_format:"ND"}
输出Tensor { shape:[B, N, H/N/16, S / 16, 16, 16], origin_shape:[B, N, S, H/N], format:"NZ", origin_format:"ND"}
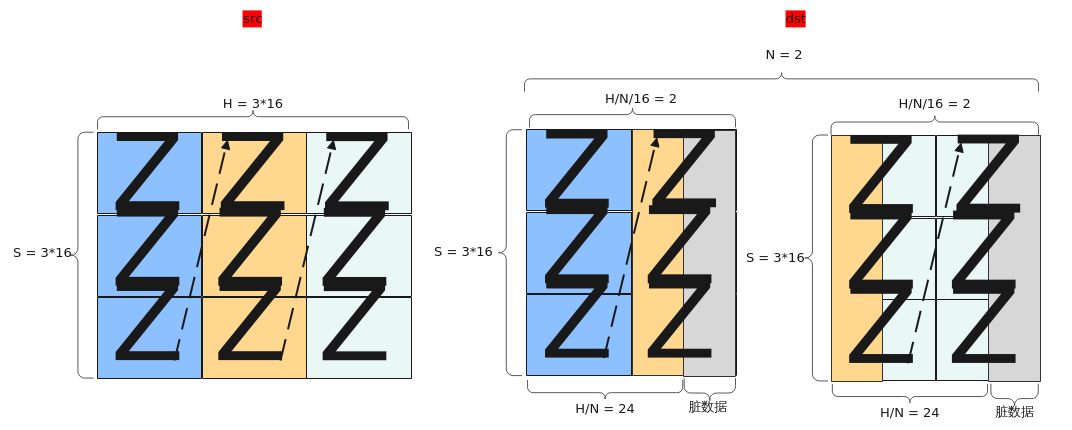
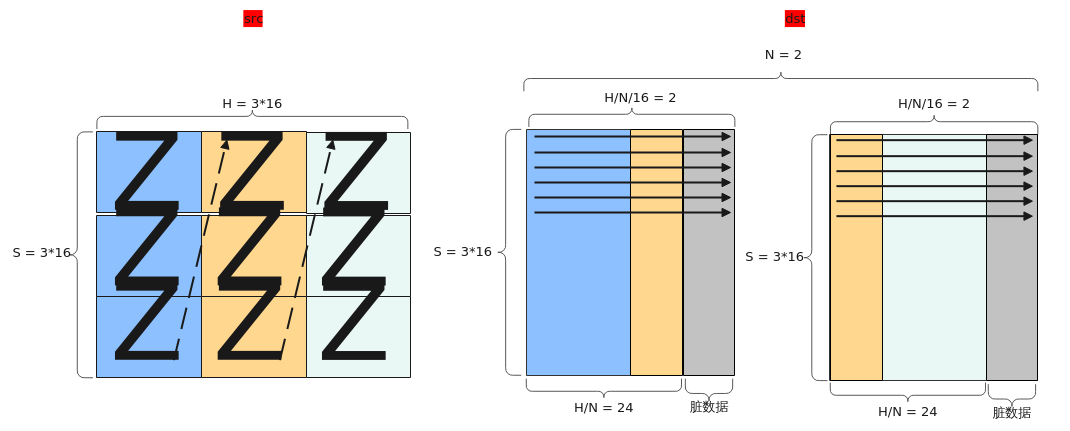
【场景4:NZ2ND,尾轴切分】
输入Tensor { shape:[B, H / 16, S / 16, 16, 16], origin_shape:[B, S, H], format:"NZ", origin_format:"ND"}
输出Tensor { shape:[B, N, S, H/N], origin_shape:[B, N, S, H/N], format:"ND", origin_format:"ND"}
【场景5:NZ2ND,尾轴合并】
输入Tensor { shape:[B, N, H/N/16, S/16, 16, 16], origin_shape:[B, N, S, H/N], format:"NZ", origin_format:"ND"}
输出Tensor { shape:[B, S, H], origin_shape:[B, S, H], format:"ND", origin_format:"ND"}
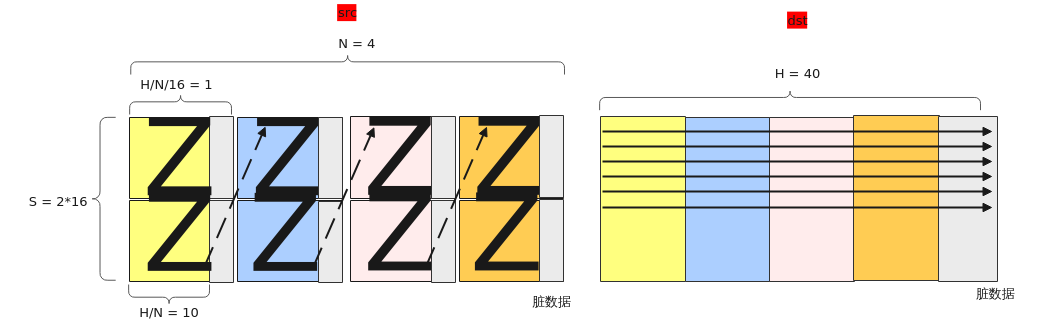
【场景6:NZ2NZ,尾轴合并】
输入Tensor { shape:[B, N, H/N/16, S/16, 16, 16], origin_shape:[B, N, S, H/N], format:"NZ", origin_format:"ND"}
输出Tensor { shape:[B, H/16, S/16, 16, 16], origin_shape:[B, S, H], format:"NZ", origin_format:"ND"}
【场景7:二维转置】
支持在UB上对二维Tensor进行转置,其中srcShape中的H、W均是16的整倍。

实现原理
对应ConfusionTranspose的7种功能场景,每种功能场景的算法框图如图所示。
计算过程分为如下几步:
先后沿H/N方向,N方向,B方向循环处理:
- 第1次TransDataTo5HD步骤:沿S方向转置S/16个连续的16*16的方形到temp中,在temp中每个方形与方形之间连续存储;
- 第2次TransDataTo5HD步骤:将temp中S/16个16*16的方形转置到dst中,在dst中是ND格式,来自同一个方形的连续2行数据在目的操作数上的地址偏移(H/N)*N个元素,沿H方向的每2个方形的同一行数据在目的操作数上的地址偏移16个元素。
计算过程分为如下几步:
先后沿H/N方向,N方向,B方向循环处理:
- 第1次TransDataTo5HD步骤:沿S方向分别取S/16个连续的16*16的方形到temp中,在temp中每个方形与方形之间连续存储;
- 第2次TransDataTo5HD步骤:将temp中S/16个16*16的方形转置到dst中,在dst中是NZ格式,来自同一个方形的连续2行数据在目的操作数上的地址偏移(H/N)*N个元素,沿H方向的每2个方形的同一行数据在目的操作数上的地址偏移N*16个元素。

计算过程分为如下几步:
先后沿H方,B方向循环处理:
- 第1次TransDataTo5HD步骤:每次转置S/16个连续的16*16的方形到temp1中;
- DataCopy步骤:当H/N<=16时,每次搬运H/N*S个元素到temp2中;当H/N>16时,前H/N/16次搬运16*S个元素到temp2中,最后一次搬运H/N%16*S个元素到tmp2中;
- 第2次TransDataTo5HD步骤:将temp2中的16*S的方形转置到dst中,在dst中是NZ格式,来自同一个方形的连续2行数据在目的操作数上的地址偏移16个元素,沿H方向的每2个方形的同一行数据在目的操作数上的地址偏移S*16个元素。
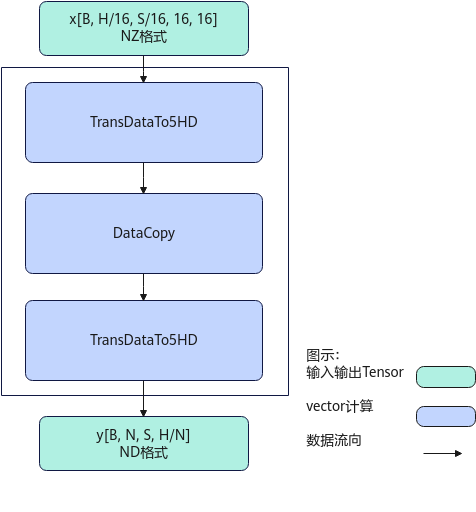
计算过程分为如下几步:
先后沿H方,B方向循环处理:
- 第1次TransDataTo5HD步骤:每次转置S/16个连续的16*16的方形到temp1中;
- DataCopy步骤:当H/N<=16时,每次搬运H/N*S个元素到temp2中;当H/N>16时,前H/N/16次搬运16*S个元素到temp2中,最后一次搬运H/N%16*S个元素到tmp2中;
- 第2次TransDataTo5HD步骤:将temp2中的数据转置到dst中,在dst中是ND格式,来自同一个方形的连续2行数据在目的操作数上的地址偏移(H/N+16-1)/16*16个元素,沿H方向的每2个方形的同一行数据在目的操作数上的地址偏移(H/N+16-1)/16*16*S个元素。
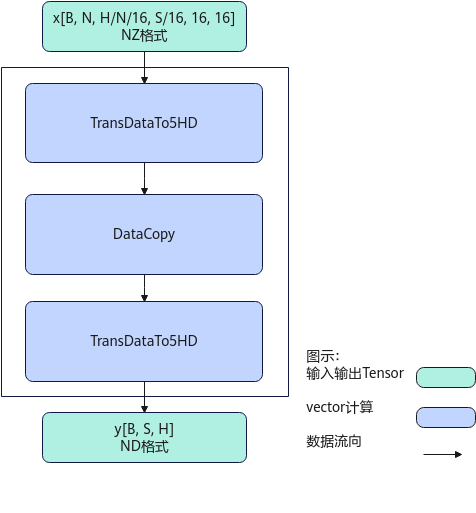
计算过程分为如下几步:
先后沿H方,B方向循环处理:
- 第1次TransDataTo5HD步骤:每次转置一个S*16的方形到temp1中;
- DataCopy步骤:当H/N<=16时,每次搬运H/N*S个元素到temp2中;当H/N>16时,前H/N/16次搬运16*S个元素到temp2中,最后一次搬运H/N%16*S个元素到tmp2中;
- 第2次TransDataTo5HD步骤:将temp2中的16*S的方形转置到dst中,在dst中是ND格式,来自同一个方形的连续2行数据在目的操作数上的地址偏移(H+16-1)/16*16个元素,沿H方向的每2个方形的同一行数据在目的操作数上的地址偏移H/N*S个元素。
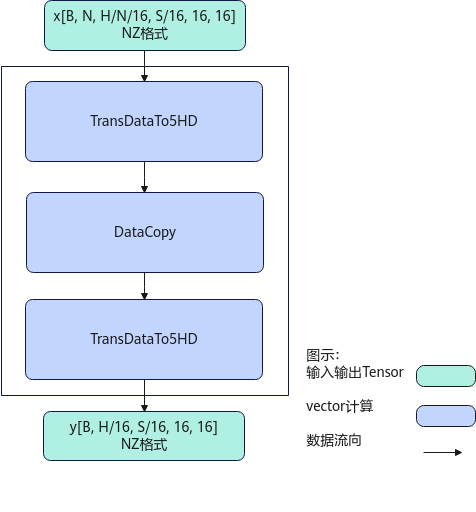
计算过程分为如下几步:
先后沿H方,B方向循环处理:
- 第1次TransDataTo5HD步骤:每次转置一个S*16的方形到temp1中;
- DataCopy步骤:当H/N<=16时,每次搬运H/N*S个元素到temp2中;当H/N>16时,前H/N/16次搬运16*S个元素到temp2中,最后一次搬运H/N%16*S个元素到tmp2中;
- 第2次TransDataTo5HD步骤:将temp2中的16*S的方形转置到dst中,在dst中是NZ格式,来自同一个方形的连续2行数据在目的操作数上的地址偏移16个元素,沿H方向的每2个方形的同一行数据在目的操作数上的地址偏移S*16个元素。
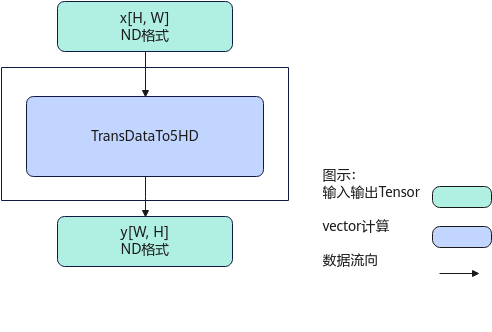
计算过程分为如下几步:
- 调用TransDataTo5HD,通过设置不同的源操作数地址序列和目的操作数地址序列,将[H, W]转置为[W, H],在src和dst中均是ND格式。
函数原型
由于该接口的内部实现中涉及复杂的计算,需要额外的临时空间来存储计算过程中的中间变量。临时空间大小BufferSize的获取方法:通过ConfusionTranspose Tiling中提供的GetConfusionTransposeMaxMinTmpSize接口获取所需最大和最小临时空间大小,最小空间可以保证功能正确,最大空间用于提升性能。
临时空间支持接口框架申请和开发者通过sharedTmpBuffer入参传入两种方式,因此ConfusionTranspose接口的函数原型有两种:
- 通过sharedTmpBuffer入参传入临时空间
1 2
template <typename T> __aicore__ inline void ConfusionTranspose(const LocalTensor<T>& dstTensor, const LocalTensor<T>& srcTensor, const LocalTensor<uint8_t> &sharedTmpBuffer, TransposeType transposeType, ConfusionTransposeTiling& tiling)
该方式下开发者需自行申请并管理临时内存空间并管理,并在接口调用完成后,复用该部分内存,内存不会反复申请释放,灵活性较高,内存利用率也较高。
- 接口框架申请临时空间
1 2
template <typename T> __aicore__ inline void ConfusionTranspose(const LocalTensor<T>& dstTensor, const LocalTensor<T>& srcTensor, TransposeType transposeType, ConfusionTransposeTiling& tiling)
该方式下开发者无需申请,但是需要预留临时空间的大小。
参数说明
|
接口 |
功能 |
|---|---|
|
T |
操作数的数据类型。 |
|
参数名 |
输入/输出 |
描述 |
|---|---|---|
|
dstTensor |
输出 |
目的操作数,类型为LocalTensor,LocalTensor数据结构的定义请参考LocalTensor。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:int16_t/uint16_t/half/int32_t/uint32_t/float Atlas推理系列产品AI Core,支持的数据类型为:int16_t/uint16_t/half/int32_t/uint32_t/float |
|
srcTensor |
输入 |
源操作数,类型为LocalTensor,LocalTensor数据结构的定义请参考LocalTensor。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:int16_t/uint16_t/half/int32_t/uint32_t/float Atlas推理系列产品AI Core,支持的数据类型为:int16_t/uint16_t/half/int32_t/uint32_t/float |
|
sharedTmpBuffer |
输入 |
共享缓冲区,用于存放API内部计算产生的临时数据。该方式开发者可以自行管理sharedTmpBuffer内存空间,并在接口调用完成后,复用该部分内存,内存不会反复申请释放,灵活性较高,内存利用率也较高。共享缓冲区大小的获取方式请参考ConfusionTranspose Tiling。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint8_t Atlas推理系列产品AI Core,支持的数据类型为:uint8_t |
|
transposeType |
输入 |
数据排布及reshape的类型,类型为TransposeType枚举类。 enum class TransposeType : uint8_t {
TRANSPOSE_TYPE_NONE, // default value
TRANSPOSE_NZ2ND_0213, // 场景1:NZ2ND,1、2轴互换
TRANSPOSE_NZ2NZ_0213, // 场景2:NZ2NZ,1、2轴互换
TRANSPOSE_NZ2NZ_012_WITH_N, // 场景3:NZ2NZ,尾轴切分
TRANSPOSE_NZ2ND_012_WITH_N, // 场景4:NZ2ND,尾轴切分
TRANSPOSE_NZ2ND_012_WITHOUT_N, // 场景5:NZ2ND,尾轴合并
TRANSPOSE_NZ2NZ_012_WITHOUT_N, // 场景6:NZ2NZ,尾轴合并
TRANSPOSE_ND2ND_ONLY, // 场景7:二维转置
TRANSPOSE_ND_UB_GM, // 当前不支持
TRANSPOSE_GRAD_ND_UB_GM, // 当前不支持
TRANSPOSE_ND2ND_B16, // 当前不支持
TRANSPOSE_NCHW2NHWC, // 当前不支持
TRANSPOSE_NHWC2NCHW // 当前不支持
}; |
|
tiling |
输入 |
计算所需tiling信息,Tiling信息的获取请参考ConfusionTranspose Tiling。 |
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
注意事项
- 操作数地址偏移对齐要求请参见通用约束。
调用示例
本样例为场景1(NZ2ND,1、2轴互换)样例:
输入Tensor { shape:[B, N, H/N/16, S/16, 16, 16], origin_shape:[B, N, S, H/N], format:"NZ", origin_format:"ND"}
输出Tensor { shape:[B, S, N, H/N], ori_shape:[B, S, N, H/N], format:"ND", origin_format:"ND"}
B=1,N=2, S=64, H/N=32,输入数据类型均为half。
#include "kernel_operator.h"
template <typename T>
class KernelConfusionTranspose {
public:
__aicore__ inline KernelConfusionTranspose(){}
__aicore__ inline void Init(__gm__ uint8_t *srcGm, __gm__ uint8_t *dstGm, const ConfusionTransposeTiling &tiling)
{
srcGlobal.SetGlobalBuffer((__gm__ T *)srcGm, B * N * S * hnDiv);
dstGlobal.SetGlobalBuffer((__gm__ T *)dstGm, B * N * S * hnDiv);
pipe.InitBuffer(inQueueSrcVecIn, 1, B * N * S * hnDiv * sizeof(T));
pipe.InitBuffer(inQueueSrcVecOut, 1, B * N * S * hnDiv * sizeof(T));
this->tiling = tiling;
}
__aicore__ inline void Process()
{
CopyIn();
Compute();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
AscendC::LocalTensor<T> srcLocal = inQueueSrcVecIn.AllocTensor<T>();
AscendC::DataCopy(srcLocal, srcGlobal, B * N * S * hnDiv);
inQueueSrcVecIn.EnQue(srcLocal);
}
__aicore__ inline void Compute()
{
AscendC::LocalTensor<T> srcLocal = inQueueSrcVecIn.DeQue<T>();
AscendC::LocalTensor<T> dstLocal = inQueueSrcVecOut.AllocTensor<T>();
AscendC::ConfusionTranspose(dstLocal, srcLocal, AscendC::TransposeType::TRANSPOSE_NZ2ND_0213, this->tiling);
inQueueSrcVecOut.EnQue<T>(dstLocal);
inQueueSrcVecIn.FreeTensor(srcLocal);
}
__aicore__ inline void CopyOut()
{
AscendC::LocalTensor<T> dstLocal = inQueueSrcVecOut.DeQue<T>();
AscendC::DataCopy(dstGlobal, dstLocal, B * N * S * hnDiv);
inQueueSrcVecOut.FreeTensor(dstLocal);
}
private:
AscendC::TPipe pipe;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueSrcVecIn;
AscendC::TQue<AscendC::QuePosition::VECOUT, 1> inQueueSrcVecOut;
AscendC::GlobalTensor<T> srcGlobal;
AscendC::GlobalTensor<T> dstGlobal;
uint32_t B = 1;
uint32_t N = 2;
uint32_t S = 64;
uint32_t hnDiv = 32;
ConfusionTransposeTiling tiling;
};
extern "C" __global__ __aicore__ void confusion_transpose_custom(
GM_ADDR src_gm, GM_ADDR dst_gm, GM_ADDR workspace, GM_ADDR tiling)
{
GET_TILING_DATA(tilingData, tiling);
KernelConfusionTranspose<half> op;
op.Init(src_gm, dst_gm, tilingData.confusionTransposeTilingData);
op.Process();
}