msprof(timeline数据总表)
支持的型号
Atlas 200/300/500 推理产品
Atlas 200/500 A2推理产品
Atlas 推理系列产品
Atlas 训练系列产品
Atlas A2训练系列产品/Atlas 800I A2推理产品
timeline数据总表文件为msprof*.json。
msprof*.json在“chrome://tracing”中展示如下。
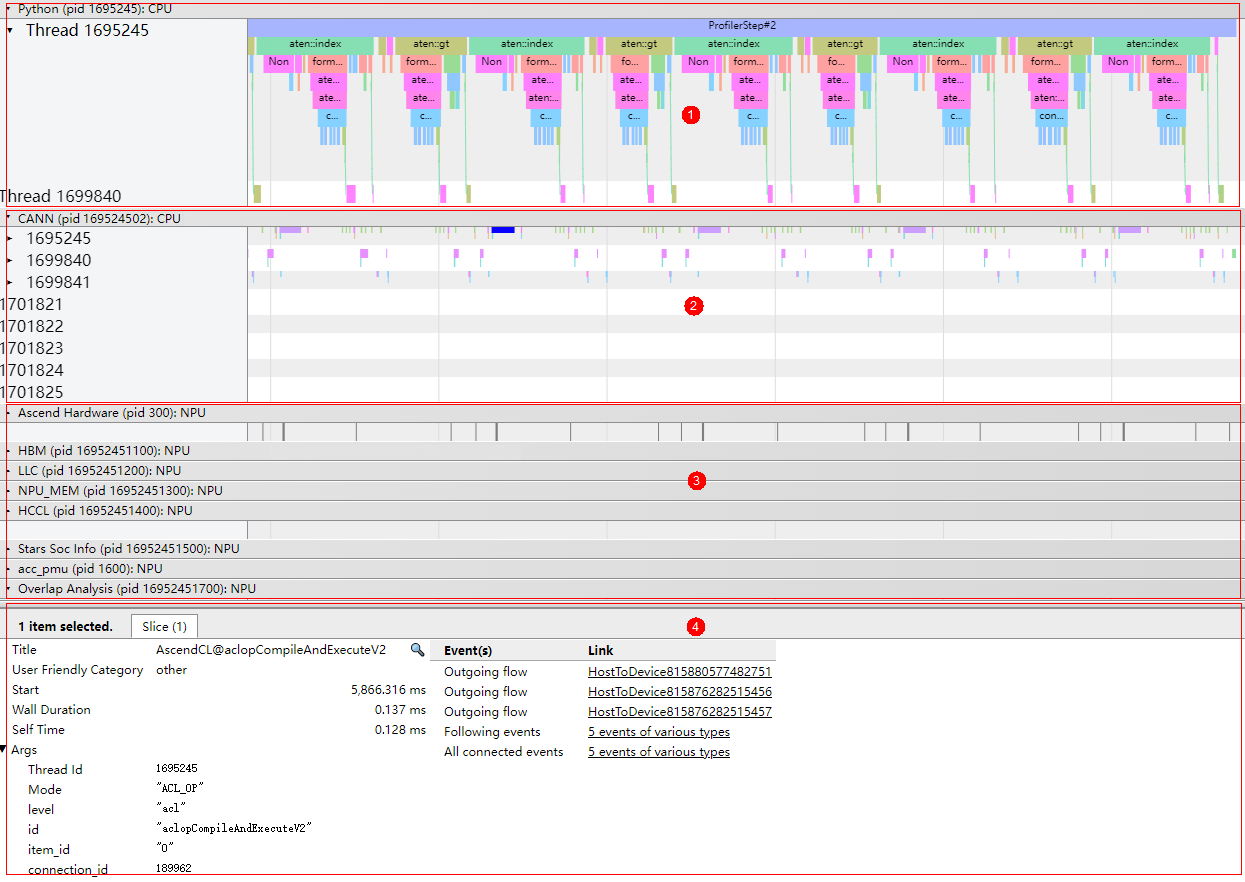
如图1所示,timeline汇总数据主要展示如下区域:
- 区域1:应用层数据,包含上层应用算子的耗时信息,需要使用msproftx采集或PyTorch场景采集。
- 区域2:CANN层数据,主要包含AscendCL、Runtime等组件以及Node(算子)的耗时数据。
- 区域3:底层NPU数据,主要包含Ascend Hardware下各个Stream任务流的耗时数据和迭代轨迹数据、HCCL和Overlap Analysis通信数据以及其他昇腾AI处理器系统数据。
- 区域4:展示timeline中各算子、接口的详细信息(单击各个timeline时展示)。

- timeline数据总表的数据在性能数据文件参考均有对应数据的详细介绍。
- 上图中各区域的数据与采集场景有关,例如非Ascend EP场景不生成host相关数据;区域1仅在msproftx或PyTorch场景采集时生成;HCCL和Overlap Analysis通信数据仅在多卡、多节点或集群等存在通信的场景可采集到数据等。请以采集数据实际情况为准。
- msprof*.json展示的数据是迭代内的数据,迭代外的数据不展示。
查看算子下发方向
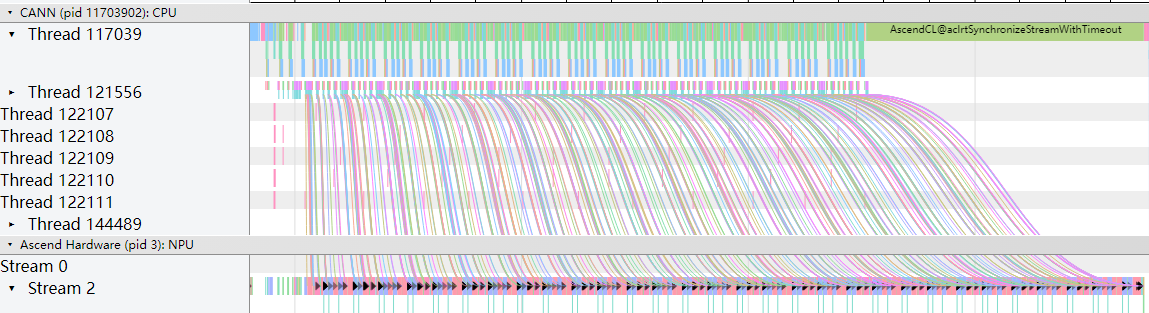
在tracing中查看.json文件时,开启“Flow events”下的选项后,应用层算子到NPU算子之间通过连线方式展示下发到执行的对应关系。如图2所示。
主要包括的对应关系有:
- async_npu:应用层算子 > Ascend Hardware的NPU算子的下发执行关系。
- MsTx:推理训练进程打点任务 > Ascend Hardware的NPU打点算子的下发执行关系。调用aclprofMarkEx接口打点时生成。
- async_task_queue:应用层Enqueue > Dequeue的入队列到出队列对应关系。
- HostToDevice:CANN层Node(算子) > AscendHardware的NPU算子的下发执行关系(Host到Device)。
- HostToDevice:CANN层Node(算子) > HCCL通信算子的下发执行关系(Host到Device)。
- fwdbwd:前向API > 反向API。
- 由于软件测量的昇腾AI处理器频率与真实频率有误差,以及host与device的时间同步误差,可能会出现下层算子因错位而无法连线的问题。
- 各层的对应关系是否呈现与对应采集场景是否采集该数据有关,请以实际情况为准。
通过单击连线两端的算子或接口,即可查看算子下发的方向。如图3所示。
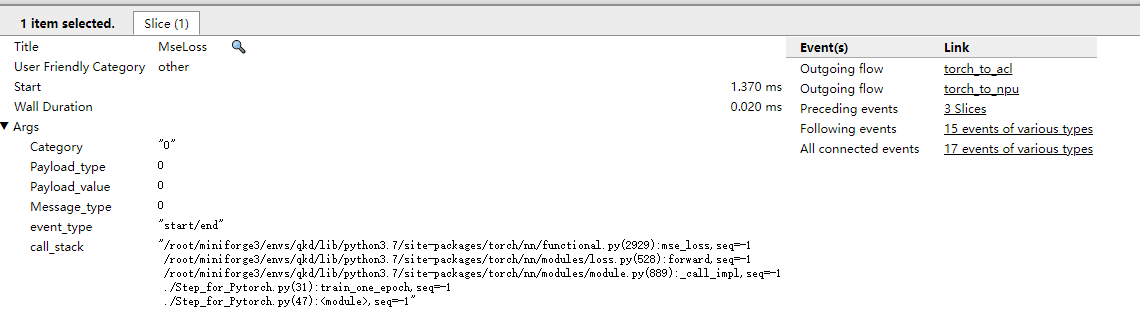
其中Event(s)列查看该算子或接口的出入方向,Link列查看映射关系两端的信息。
查看AI Core频率
支持的型号:
- Atlas 200/500 A2推理产品
- Atlas A2训练系列产品/Atlas 800I A2推理产品
msprof*.json下的“AI Core Freq”层级展示AI Core芯片在执行AI任务的过程中频率的变化情况,如图4所示。
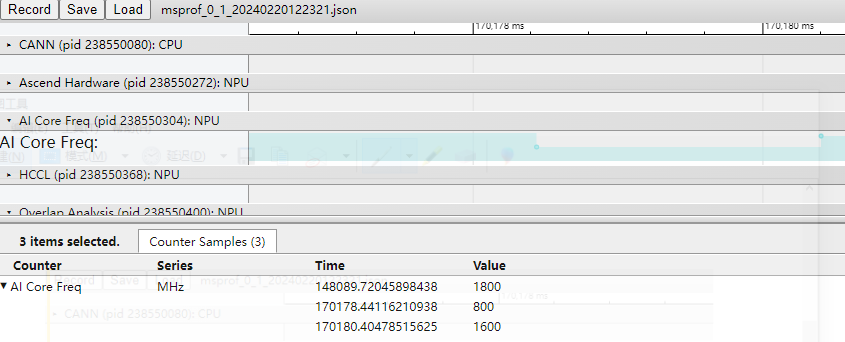
在148089.72045898438时刻下,AI Core处于高频状态,而在170178.44116210938时刻频率降低,那么在该时间段下AI任务的性能必然下降。AI Core芯片可能因温度升高,触发保护机制,降低频率;也可能因当前无AI任务运行,AI Core进入低功耗状态而降频。
在发生变频时,实际变频时间与软件监测到的时间存在0~1ms的延时,该延时可能导致变频前后统计出的算子执行时间与实际不符。
QoS数据分析
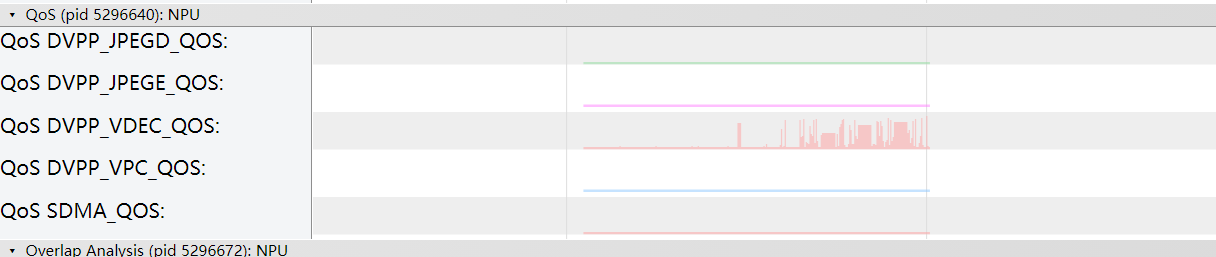
msprof*.json下的“QoS”层级展示设备QoS带宽信息。
支持的型号:
- Atlas A2训练系列产品/Atlas 800I A2推理产品
图中色块横坐标对应时间Time,单位ms,纵坐标对应带宽Value,单位MB/s。
未被定义的业务流或加速器的带宽数据会被统计在OTHERS内;对于用户定义的业务流或加速器的带宽数据,将会单独显示其带宽数据,如图6所示。
字段名 |
字段含义 |
|---|---|
QoS OTHERS |
默认情况下QoS带宽信息。 |
QoS {name} |
被定义的业务流或加速器QoS带宽信息,如图6中DVPP_JPEGD、DVPP_JPEGE等。 |
计算及通信算子融合MC²
存在计算和通信算子融合的场景。
MC²:Matrix Computation & Communication,是CANN中一系列计算通信融合算子的统称,把原本串行的两个通信、计算算子融合到一起,内部通过Tiling切分成多轮通信计算,轮次间形成流水并行,从而掩盖通信耗时,提升整体执行性能。
具体算子一般以原计算通信算子名称按照依赖关系排列命名。比如AllgatherMatmul融合算子代表通信算子Allgather和计算算子Matmul融合,matmul依赖allgather输出。
通信轮次commTurn:即融合算子Tiling切分的份数。一般值为总数据量/单次通信量。
MC²实现中,内部分别在计算流、通信流上加载两个算子,两个算子内部实现协同完成流水并行执行:
- 计算流对应算子名称为融合算子名称,比如AllgatherMatmul。
- 通信流对应算子名称为融合算子名称+Aicpu,比如AllgathernMatmulAicpu。
通信算子根据融合算子Tiling切分执行多个通信轮次,每轮的基本流程是,根据计算算子下发的通信参数,执行集合通信算法,编排好具体任务,下发给硬件执行,并等待执行完成,通知计算侧执行结果。
- 通信API场景暂不支持融合MC²,通信API场景包括:低bit通信MatmulAllReduce算子以及自定义的使用通信API的MC²算子。
- Timeline的HCCL部分仅呈现Level0级别的数据。
MC²性能数据结果示例如下:

图7展示了MatmulAllReduceAddRmsNormAicpu融合算子,内部各阶段分别为:
字段名 |
字段含义 |
|---|---|
WaitNotify |
等待计算算子下发通信参数。 |
KfcAlgExe |
通信算子内部执行集合通信算法,编排执行任务耗时。 |
SendTask |
任务下发耗时。 |
WaitActive |
等待激活耗时。 |
Active |
正式激活任务执行。 |
WaitExeEnd |
等待硬件任务执行完成耗时。 |