算子基本概念
深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称OP)。在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully-connected Layer, FC layer)中的权值求和过程,是一个算子。
在数学领域,一个函数空间到函数空间上的映射O:X→Y,都称为算子。
广义的讲,对任何函数进行某一项操作都可以认为是一个算子,比如微分算子,不定积分算子等。
本章节介绍算子中常用的基本概念。
算子名称(Name)
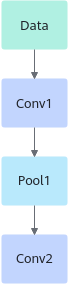
算子的名称,用于标志网络中的某个算子,同一网络中算子的名称需要保持唯一。如下图所示Conv1、Pool1、Conv2都是此网络中的算子名称,其中Conv1与Conv2算子的类型为Convolution,表示分别做一次卷积运算。
算子类型(Type)
网络中每一个算子根据算子类型进行算子实现的匹配,相同类型的算子的实现逻辑相同。在一个网络中同一类型的算子可能存在多个,例如上图中的Conv1算子与Conv2算子的类型都为Convolution。
张量(Tensor)
Tensor是算子计算数据的容器,TensorDesc(Tensor描述符)是对Tensor中数据的描述。TensorDesc数据结构包含如下属性如表1所示。
属性 |
定义 |
|---|---|
名称(name) |
用于对Tensor进行索引,不同Tensor的name需要保持唯一。 |
形状(shape) |
Tensor的形状,比如(10,)或者(1024, 1024)或者(2, 3, 4)等。详细介绍请参见形状(Shape)。 默认值:无 形式:(i1, i2,…in),其中i1到in均为正整数。 说明:
由于AI Core算子编译器限制,不支持传入shape中含0的tensor(空tensor),开发者在构造输入时需要避免传入空tensor。 |
数据类型(dtype) |
指定Tensor对象的数据类型。 默认值:无 取值范围:float16, float32, int8, int16, int32, uint8, uint16, bfloat16, bool等。 |
数据排布格式(format) |
数据的物理排布格式,定义了解读数据的维度。 详细请参见数据排布格式。 |
形状(Shape)
张量的形状,以(D0, D1, … ,Dn-1)的形式表示,D0到Dn是任意的正整数。
如形状(3,4)表示第一维有3个元素,第二维有4个元素,(3,4)表示一个3行4列的矩阵数组。
形状的第一个元素对应张量最外层中括号中的元素个数,形状的第二个元素对应张量中从左边开始数第二个中括号中的元素个数,依此类推。例如:
张量 |
形状 |
描述 |
|---|---|---|
1 |
(0,) |
0维张量,也是一个标量 |
[1,2,3] |
(3,) |
1维张量 |
[[1,2],[3,4]] |
(2, 2) |
2维张量 |
[[[1,2],[3,4]], [[5,6],[7,8]]] |
(2, 2, 2) |
3维张量 |
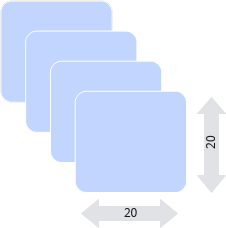
物理含义我们应该怎么理解呢?假设我们有这样一个shape=(4, 20, 20, 3)。
假设有一些照片,每个像素点都由红/绿/蓝3色组成,即shape里面3的含义,照片的宽和高都是20,也就是20*20=400个像素,总共有4张的照片,这就是shape=(4, 20, 20, 3)的物理含义。
如果体现在编程上,可以简单把shape理解为操作Tensor的各层循环,比如我们要对shape=(4, 20, 20, 3)的A tensor进行操作,循环语句如下:
produce A {
for (i, 0, 4) {
for (j, 0, 20) {
for (p, 0, 20) {
for (q, 0, 3) {
A[((((((i*20) + j)*20) + p)*3) + q)] = a_tensor[((((((i*20) + j)*20) + p)*3) + q)]
}
}
}
}
}
轴(axis)
轴是相对shape来说的,轴代表张量的shape的下标,比如张量a是一个5行6列的二维数组,即shape是(5,6),则axis=0表示是张量中的第一维,即行。axis=1表示是张量中的第二维,即列。
例如张量数据[[[1,2],[3,4]], [[5,6],[7,8]]],Shape为(2,2,2),则轴0代表第一个维度的数据即[[1,2],[3,4]]与[[5,6],[7,8]]这两个矩阵,轴1代表第二个维度的数据即[1,2]、[3,4]、[5,6]、[7,8]这四个数组,轴2代表第三个维度的数据即1,2,3,4,5,6,7,8这八个数。
轴axis可以为负数,此时表示是倒数第axis个维度。
N维Tensor的轴有:0 , 1, 2,……,N-1。

权重(weight)
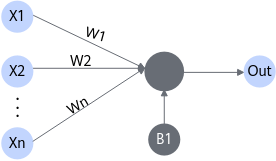
当输入数据进入计算单元时,会乘以一个权重。例如,如果一个算子有两个输入,则每个输入会分配一个关联权重,一般将认为较重要数据赋予较高的权重,不重要的数据赋予较小的权重,为零的权重则表示特定的特征是无需关注的。
如图4所示,假设输入数据为X1,与其相关联的权重为W1,那么在通过计算单元后,数据变为了X1*W1。

偏差(bias)
偏差是除了权重之外,另一个被应用于输入数据的线性分量。它被加到权重与输入数据相乘的结果中,用于改变权重与输入相乘所得结果的范围。
如图5所示,假设输入数据为X1,与其相关联的权重为W1,偏差为B1,那么在通过计算单元后,数据变为了X1*W1+B1。
广播
TBE支持的广播规则:可以将一个数组的每一个维度扩展为一个固定的shape,需要被扩展的数组的每个维度的大小或者与目标shape相等,或者为1,广播会在元素个数为1的维度上进行。
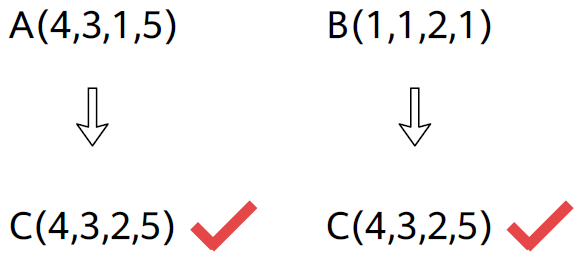
例如:原数组a的维度为(2, 1, 64),目标shape为(2, 128, 64),则通过广播可以将a的维度扩展为目标shape(2, 128, 64)。
TBE的计算接口加、减、乘、除等不支持自动广播,要求输入的两个Tensor的shape相同,所以操作前,我们需要先计算出目标shape,然后将每个输入Tensor广播到目标shape再进行计算。
例如,Tensor A的shape为(4, 3, 1, 5),Tensor B的shape为(1, 1, 2, 1),执行Tensor A + Tensor B ,具体计算过程如下:


降维-Reduction
Reduction是将多维数组的指定轴及之后的数据做降维操作。降维有很多种算子,例如TensorFlow中的Sum、Min、Max、All、Mean等,Caffe中的Reduction算子,此处以Caffe中的Reduction算子为例进行讲解。
- Reduction的属性
- ReductionOp:常见算子支持的操作类型,包含四种类型。
表3 Reduction算子操作类型 算子类型
说明
SUM
对被reduce的所有轴求和。
ASUM
对被reduce的所有轴求绝对值后求和。
SUMSQ
对被reduce的所有轴求平方后再求和。
MEAN
对被reduce的所有轴求均值。
- axis:Reduction需要指定一个轴,会对此轴及其之后的轴进行reduce操作,取值范围为:[-N,N-1]。
- coeff:标量,对结果缩放,如果值为1,则不进行缩放。
- ReductionOp:常见算子支持的操作类型,包含四种类型。
下面通过示例了解降维操作。
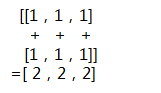
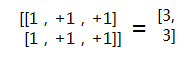
转换算子
转换算子是一种特殊的算子,用于转换Tensor的Data Type与Format等信息,使得图中上下游节点能够被正常处理。
图经过一系列处理后,如下沉、优化、融合等,节点中的Tensor信息可能发生了变化,所以需要插入转换算子使图能够继续被正常处理。在网络拓扑图进行编译时,FE会自动插入转换算子,无需用户手工进行上下游算子间的格式转换。
- Format格式转换
Tensorflow网络中Conv2D、MatMul算子使用的变量format为HWCN,其他算子使用变量format为NCHW或NHWC。
AI Core模块中Conv2D、MatMul算子使用变量format为FZ,其他算子使用变量format为NC1HWC0。
AI CPU模块中的TF Ops使用的format与Tensorflow网络一致。
网络运行时,不同的算子在不同的模块执行,涉及到Format的转换如下:
图7 Format转换示例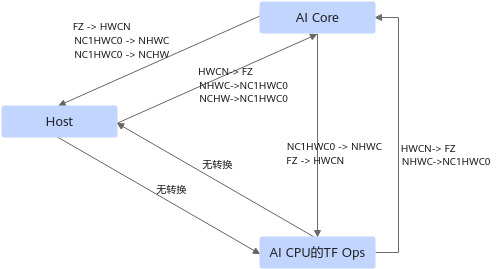
- 数据类型转换
有些昇腾AI处理器的算子仅支持FP16类型的数据,当输入变量的数据类型为FP32时,需要在变量与算子间添加数据类型转换算子。
为优化变量更新,训练网络中新增一个变量算子,其数据类型为FP16,使用方式如下:
图8 DataType转换示例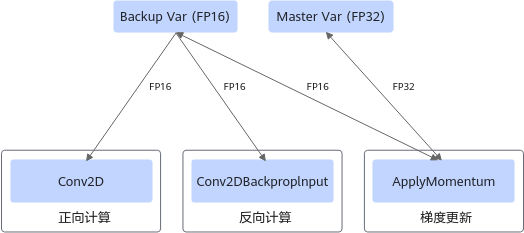
正向与反向计算时,直接使用FP16变量参与计算。
梯度更新时,将FP32与FP16变量同时参与计算,其中FP32数据作为基准数据。