Erf
功能说明
按元素做误差函数计算(也称为高斯误差函数,error function or Gauss error function)。计算公式如下,其中PAR表示矢量计算单元一个迭代能够处理的元素个数 :
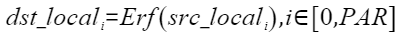
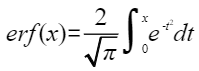
函数原型
- 通过sharedTmpBuffer入参传入临时空间
- 源操作数Tensor全部/部分参与计算
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void Erf(const LocalTensor<T>& dstTensor, const LocalTensor<T>& srcTensor,const LocalTensor<uint8_t>& sharedTmpBuffer, const uint32_t calCount)
- 源操作数Tensor全部参与计算
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void Erf(const LocalTensor<T>& dstTensor, const LocalTensor<T>& srcTensor,const LocalTensor<uint8_t>& sharedTmpBuffer)
- 源操作数Tensor全部/部分参与计算
- 接口框架申请临时空间
- 源操作数Tensor全部/部分参与计算
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void Erf(const LocalTensor<T> &dstTensor, const LocalTensor<T> &srcTensor, const uint32_t calCount)
- 源操作数Tensor全部参与计算
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void Erf(const LocalTensor<T>& dstTensor, const LocalTensor<T>& srcTensor)
- 源操作数Tensor全部/部分参与计算
- 通过sharedTmpBuffer入参传入,使用该tensor作为临时空间进行处理,接口框架不再申请。该方式开发者可以自行管理sharedTmpBuffer内存空间,并在接口调用完成后,复用该部分内存,内存不会反复申请释放,灵活性较高,内存利用率也较高。
- 接口框架申请临时空间,开发者无需申请,但是需要预留临时空间的大小。
通过sharedTmpBuffer传入的情况,开发者需要为tensor申请空间;接口框架申请的方式,开发者需要预留临时空间。临时空间大小BufferSize的获取方式如下:通过GetErfMaxMinTmpSize接口获取需要预留空间范围的大小。
参数说明
参数名 |
描述 |
|---|---|
T |
操作数的数据类型。 |
isReuseSource |
是否允许修改源操作数。该参数预留,传入默认值false即可。 |
参数名 |
输入/输出 |
描述 |
|---|---|---|
dstLocal |
输出 |
目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
srcLocal |
输入 |
源操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 源操作数的数据类型需要与目的操作数保持一致。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
sharedTmpBuffer |
输入 |
临时缓存。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 临时空间大小BufferSize的获取方式请参考7.11.31-Erf Tiling。 |
calCount |
输入 |
实际计算数据元素个数,且calCount∈(0, srcTensor.GetSize()]。 |
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
调用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | #include "kernel_operator.h" template <typename srcType> class KernelErf { public: __aicore__ inline KernelErf() {} __aicore__ inline void Init(GM_ADDR srcGm, GM_ADDR dstGm, uint32_t srcSize) { srcGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ srcType *>(srcGm), srcSize); dstGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ srcType *>(dstGm), srcSize); pipe.InitBuffer(inQueueX, 1, srcSize * sizeof(srcType)); pipe.InitBuffer(outQueue, 1, srcSize * sizeof(srcType)); } __aicore__ inline void Process(uint32_t offset, uint32_t calSize) { bufferSize = calSize; CopyIn(offset); Compute(); CopyOut(offset); } private: __aicore__ inline void CopyIn(uint32_t offset) { AscendC::LocalTensor<srcType> srcLocal = inQueueX.AllocTensor<srcType>(); AscendC::DataCopy(srcLocal, srcGlobal[offset], bufferSize); inQueueX.EnQue(srcLocal); } __aicore__ inline void Compute() { AscendC::LocalTensor<srcType> dstLocal = outQueue.AllocTensor<srcType>(); AscendC::LocalTensor<srcType> srcLocal = inQueueX.DeQue<srcType>(); for (int i = 0; i < 100; i++) { AscendC::Erf<srcType, false, true>(dstLocal, srcLocal); } outQueue.EnQue<srcType>(dstLocal); inQueueX.FreeTensor(srcLocal); } __aicore__ inline void CopyOut(uint32_t offset) { AscendC::LocalTensor<srcType> dstLocal = outQueue.DeQue<srcType>(); AscendC::DataCopy(dstGlobal[offset], dstLocal, bufferSize); outQueue.FreeTensor(dstLocal); } private: AscendC::GlobalTensor<srcType> srcGlobal; AscendC::GlobalTensor<srcType> dstGlobal; AscendC::TPipe pipe; AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueX; AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueue; uint32_t bufferSize = 0; }; template <typename dataType> __aicore__ void kernel_erf_operator(GM_ADDR srcGm, GM_ADDR dstGm, uint32_t srcSize) { KernelErf<dataType> op; op.Init(srcGm, dstGm, srcSize); op.Process(); } |
输入数据(srcLocal): [-9.609991 -1.8448765 9.609758 3.8447127 -1.1222854 9.229954 -1.9746934 -3.7733989 -4.9434195 0.8424659 0.2051153 -9.630209 9.585648 1.3517833 -7.195028 4.7777047] 输出数据(dstLocal): [-1. -0.9909206 1. 0.99999994 -0.88752156 1. -0.994772 -0.9999999 -1. 0.7665139 0.22824255 -1. 1. 0.9440866 -1. 1. ]