GroupNorm
功能说明
对一个特征进行标准化的一般公式如下所示:

其中 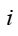 表示特征中的索引,
表示特征中的索引, 和
和 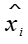 表示特征中每个值标准化前后的值,
表示特征中每个值标准化前后的值,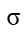 和
和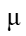 表示特征的均值和标准差,计算公式如下所示:
表示特征的均值和标准差,计算公式如下所示:
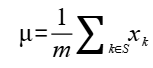
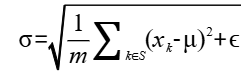
其中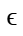 是一个很小的常数,
是一个很小的常数,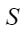 表示参与计算的数据的集合,
表示参与计算的数据的集合,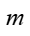 表示集合的大小。不同类型的特征标准化方法(BatchNorm、LayerNorm、InstanceNorm、GroupNorm等) 的主要区别在于参与计算的数据集合的选取上。不同Norm类算子参与计算的数据集合的选取方式如下:
表示集合的大小。不同类型的特征标准化方法(BatchNorm、LayerNorm、InstanceNorm、GroupNorm等) 的主要区别在于参与计算的数据集合的选取上。不同Norm类算子参与计算的数据集合的选取方式如下:
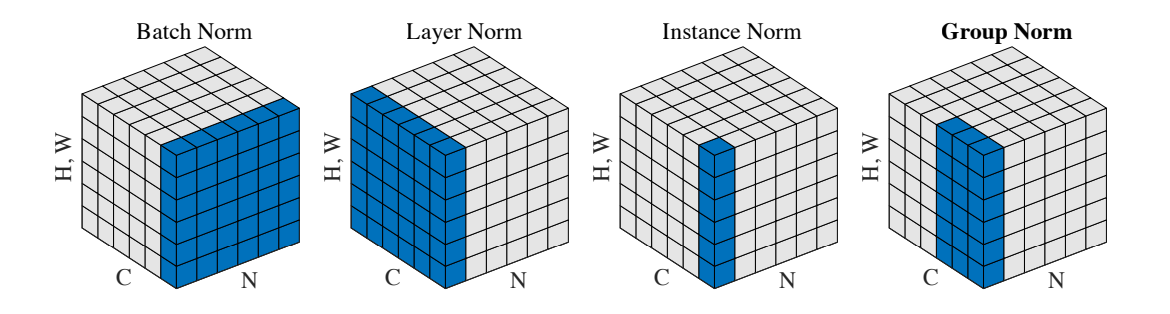
对于一个shape为[N, C, H, W]的输入,GroupNorm将每个[C, H, W]在C维度上分为groupNum组,然后对每一组进行标准化。最后对标准化后的特征进行缩放和平移。其中缩放参数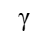 和平移参数
和平移参数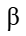 是可训练的。
是可训练的。
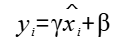
函数原型
- 接口框架申请临时空间
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void GroupNorm(const LocalTensor<T>& output, const LocalTensor<T>& outputMean, const LocalTensor<T>& outputVariance, const LocalTensor<T>& inputX, const LocalTensor<T>& gamma, const LocalTensor<T>& beta, const T epsilon, GroupNormTiling& tiling)
- 通过sharedTmpBuffer入参传入临时空间
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void GroupNorm(const LocalTensor<T>& output, const LocalTensor<T>& outputMean, const LocalTensor<T>& outputVariance, const LocalTensor<T>& inputX, const LocalTensor<T>& gamma, const LocalTensor<T>& beta, const LocalTensor<uint8_t>& sharedTmpBuffer, const T epsilon, GroupNormTiling& tiling)
参数说明
|
参数名 |
描述 |
|---|---|
|
T |
操作数的数据类型。 |
|
isReuseSource |
是否允许修改源操作数,默认值为false。如果开发者允许源操作数被改写,可以使能该参数,使能后能够节省部分内存空间。 设置为true,则本接口内部计算时复用inputX的内存空间,节省内存空间;设置为false,则本接口内部计算时不复用inputX的内存空间。 对于float数据类型的输入支持开启该参数,half数据类型的输入不支持开启该参数。 isReuseSource的使用样例请参考更多样例。 |
|
参数名 |
输入/输出 |
描述 |
|---|---|---|
|
output |
输出 |
目的操作数,对标准化后的输入进行缩放和平移计算的结果。shape为[N, C, H, W]。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 |
|
outputMean |
输出 |
目的操作数,均值。shape为[N, groupNum]。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 |
|
outputVariance |
输出 |
目的操作数,方差。shape为[N, groupNum]。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 |
|
inputX |
输入 |
源操作数。shape为[N, C, H, W]。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 |
|
gamm |
输入 |
源操作数,缩放参数。shape为[C]。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 |
|
beta |
输入 |
源操作数,平移参数。shape为[C]。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 |
|
sharedTmpBuffer |
输入 |
接口内部复杂计算时用于存储中间变量,由开发者提供。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 临时空间大小BufferSize的获取方式请参考GroupNorm Tiling。 |
|
epsilon |
输入 |
防除0的权重系数。数据类型需要与inputX/output保持一致。 |
|
tilling |
输入 |
输入数据的切分信息,Tiling信息的获取请参考GroupNorm Tiling。 |
返回值
无
支持的型号
注意事项
- 操作数地址偏移对齐要求请参见通用约束。
- 当前仅支持ND格式的输入,不支持其他格式。
调用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
template <typename dataType, bool isReuseSource = false> __aicore__ inline void MainGroupnormTest(GM_ADDR inputXGm, GM_ADDR gammGm, GM_ADDR betaGm, GM_ADDR outputGm, uint32_t n, uint32_t c, uint32_t h, uint32_t w, uint32_t g) { dataType epsilon = 0.001; DataFormat dataFormat = DataFormat::ND; GlobalTensor<dataType> inputXGlobal; GlobalTensor<dataType> gammGlobal; GlobalTensor<dataType> betaGlobal; GlobalTensor<dataType> outputGlobal; uint32_t bshLength = n*c*h*w; uint32_t bsLength = g*n; inputXGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ dataType*>(inputXGm), bshLength); gammGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ dataType*>(gammGm), c); betaGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ dataType*>(betaGm), c); outputGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ dataType*>(outputGm), bshLength); TPipe pipe; TQue<QuePosition::VECIN, 1> inQueueX; TQue<QuePosition::VECIN, 1> inQueueGamma; TQue<QuePosition::VECIN, 1> inQueueBeta; TQue<QuePosition::VECOUT, 1> outQueue; TBuf<QuePosition::VECCALC> meanBuffer, varBuffer; uint32_t hwAlignSize = (sizeof(dataType) * h * w + ONE_BLK_SIZE - 1) / ONE_BLK_SIZE * ONE_BLK_SIZE / sizeof(dataType); pipe.InitBuffer(inQueueX, 1, sizeof(dataType) * n * c * hwAlignSize); pipe.InitBuffer(inQueueGamma, 1, (sizeof(dataType) * c + 31) / 32 * 32); pipe.InitBuffer(inQueueBeta, 1, (sizeof(dataType) * c + 31) / 32 * 32); pipe.InitBuffer(outQueue, 1, sizeof(dataType) * n * c * hwAlignSize); pipe.InitBuffer(meanBuffer, (sizeof(dataType) * g * n + 31) / 32 * 32); pipe.InitBuffer(varBuffer, (sizeof(dataType) * g * n + 31) / 32 * 32); LocalTensor<dataType> inputXLocal = inQueueX.AllocTensor<dataType>(); LocalTensor<dataType> gammaLocal = inQueueGamma.AllocTensor<dataType>(); LocalTensor<dataType> betaLocal = inQueueBeta.AllocTensor<dataType>(); LocalTensor<dataType> outputLocal = outQueue.AllocTensor<dataType>(); LocalTensor<dataType> meanLocal = meanBuffer.Get<dataType>(); LocalTensor<dataType> varianceLocal = varBuffer.Get<dataType>(); DataCopyParams copyParams{static_cast<uint16_t>(n*c), static_cast<uint16_t>(h*w*sizeof(dataType)), 0, 0}; DataCopyPadParams padParams{true, 0, static_cast<uint8_t>(hwAlignSize - h * w), 0}; DataCopyPad(inputXLocal, inputXGlobal, copyParams, padParams); DataCopyParams copyParamsGamma{1, static_cast<uint16_t>(c*sizeof(dataType)), 0, 0}; DataCopyPadParams padParamsGamma{false, 0, 0, 0}; DataCopyPad(gammaLocal, gammGlobal, copyParamsGamma, padParamsGamma); DataCopyPad(betaLocal, betaGlobal, copyParamsGamma, padParamsGamma); PipeBarrier<PIPE_ALL>(); uint32_t stackBufferSize = 0; { LocalTensor<float> stackBuffer; bool ans = PopStackBuffer<float, TPosition::LCM>(stackBuffer); stackBufferSize = stackBuffer.GetSize(); } GroupNormTiling groupNormTiling; uint32_t inputShape[4] = {n, c, h, w}; ShapeInfo shapeInfo{ (uint8_t)4, inputShape, (uint8_t)4, inputShape, dataFormat }; GetGroupNormNDTillingInfo(shapeInfo, stackBufferSize, sizeof(dataType), isReuseSource, g, groupNormTiling); GroupNorm<dataType, isReuseSource>(outputLocal, meanLocal, varianceLocal, inputXLocal, gammaLocal, betaLocal, (dataType)epsilon, groupNormTiling); PipeBarrier<PIPE_ALL>(); DataCopyPad(outputGlobal, outputLocal, copyParams); inQueueX.FreeTensor(inputXLocal); inQueueGamma.FreeTensor(gammaLocal); inQueueBeta.FreeTensor(betaLocal); outQueue.FreeTensor(outputLocal); PipeBarrier<PIPE_ALL>(); } |