手工调优
执行训练后量化特性的精度如果不满足要求,可以尝试手动调整config.json文件中的参数,本节给出调整的原则,以及参数解释。
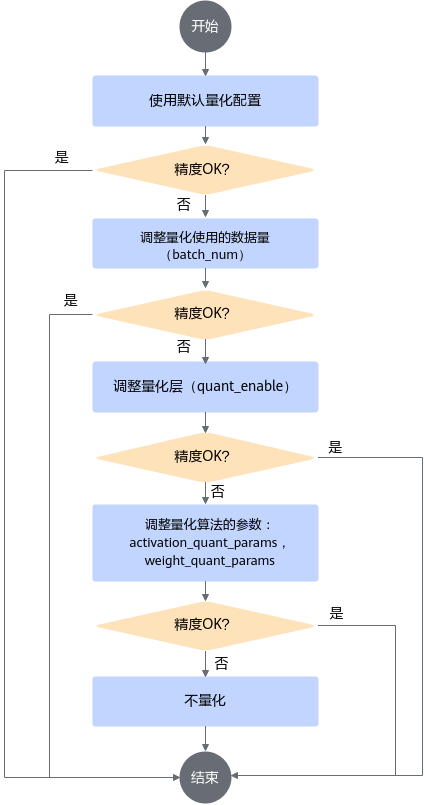
调优流程
通过create_quant_config接口生成的config.json文件中的默认配置(示例请参见量化配置文件)进行量化,若量化后的推理精度不满足要求,则可调整量化配置重复量化,直至精度满足要求。本节详细介绍手动调优流程,调整对象是训练后量化配置文件config.json中的参数,主要涉及3个阶段:
- 调整校准使用的数据量。
- 跳过量化某些层。
- 调整量化算法及参数。
具体步骤如下:
- 根据create_quant_config接口生成的默认配置进行量化。若精度满足要求,则调参结束,否则进行2。
- 手动修改batch_num,调整校准使用的数据量。
batch_num控制量化使用数据的batch数目,可根据batch大小以及量化需要使用的图片数量调整。通常情况下:
batch_num越大,量化过程中使用的数据样本越多,量化后精度损失越小;但过多的数据并不会带来精度的提升,反而会占用较多的内存,降低量化的速度,并可能引起内存、显存、线程资源不足等情况;因此,建议batch_num*batch_size为16或32(batch_size表示每个batch使用的图片数量)。
- 若按照2中的量化配置进行量化后,精度满足要求,则调参结束,否则进行4。
- 手动修改quant_enable,跳过量化某些层。
quant_enable可以指定该层是否量化,取值为true时量化该层,取值为false时不量化该层,将该层的配置删除也可跳过该层量化。
在整网精度不达标的时候需要识别出网络中的量化敏感层(量化后误差显著增大),然后取消对量化敏感层的量化动作,识别量化敏感层有两种方法:
- 依据网络模型结构,一般网络中首层、尾层以及参数量偏少的层,量化后精度会有较大的下降。
- 通过精度比对工具,逐层比对原始模型和量化后模型输出误差(例如以余弦相似度作为标准,需要相似度达到0.99以上),找到误差较大的层,优先对其进行回退。
- 若按照4中的量化配置进行量化后,精度满足要求,则调参结束,否则进行6。
- 手动修改activation_quant_params和weight_quant_params,调整量化算法及参数:
- 若按照6中的量化配置进行量化后,精度满足要求,则调参结束,否则表明量化对精度影响很大,不能进行量化,去除量化配置。
量化配置文件
通过create_quant_config接口生成的config.json部分内容样例如下(用户修改json文件时,请确保层名唯一):
- 均匀量化配置文件(数据量化使用IFMR数据量化算法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
{ "version":1, "batch_num":1, "activation_offset":true, "joint_quant":false, "do_fusion":true, "skip_fusion_layers":[], "tensor_quantize":[ { "layer_name": "MaxPool", "input_index": 0, "activation_quant_params":{ "num_bits":8, "act_algo":"hfmg", "num_of_bins":4096 "asymmetric":false } } ] "MobilenetV2/Conv/Conv2D":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":8, "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01 "act_algo":"ifmr" "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":true } }, "MobilenetV2/Logits/AvgPool":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":8, "max_percentile":0.999999, "min_percentile":0.999999, "search_range":[ 0.7, 1.3 ], "search_step":0.01 "act_algo":"ifmr" "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":false } } }
- 均匀量化配置文件(数据量化使用HFMG数据量化算法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
{ "version":1, "batch_num":2, "activation_offset":true, "joint_quant":false, "do_fusion":true, "skip_fusion_layers":[], "MobilenetV2/Conv_1/Conv2D":{ "quant_enable":true, "dmq_balancer_param":0.5, "activation_quant_params":{ "num_bits":8, "act_algo":"hfmg", "num_of_bins":4096 "asymmetric":false }, "weight_quant_params":{ "num_bits":8, "wts_algo":"arq_quantize", "channel_wise":true } } }
参数说明
配置文件中参数说明如下:
|
作用 |
控制量化配置文件版本号。 |
|---|---|
|
类型 |
int |
|
取值范围 |
1 |
|
参数说明 |
目前仅有一个版本号1。 |
|
推荐配置 |
1 |
|
可选或者必选 |
可选 |
|
作用 |
控制量化使用多少个batch的数据。 |
|---|---|
|
类型 |
int |
|
取值范围 |
大于0 |
|
参数说明 |
如果不配置,则使用默认值1,建议校准集图片数量不超过50张,根据batch的大小batch_size计算相应的batch_num数值。 batch_num*batch_size为量化使用的校准集图片数量。 其中batch_size为每个batch所用的图片数量。 |
|
推荐配置 |
1 |
|
必选或可选 |
可选 |
|
作用 |
控制数据量化是对称量化还是非对称量化。全局配置参数。 若配置文件中同时存在activation_offset和asymmetric参数,asymmetric参数优先级>activation_offset参数。 |
|---|---|
|
类型 |
bool |
|
取值范围 |
true或false |
|
参数说明 |
|
|
推荐配置 |
true |
|
必选或可选 |
可选 |
|
作用 |
是否进行Eltwise联合量化。 |
|---|---|
|
类型 |
bool |
|
取值范围 |
true或false |
|
参数说明 |
|
|
推荐配置 |
false |
|
必选或可选 |
可选 |
|
作用 |
是否开启融合功能。 |
|---|---|
|
类型 |
bool |
|
取值范围 |
true或false |
|
参数说明 |
当前支持融合的层以及融合规则请参见工具实现的融合功能。 |
|
推荐配置 |
true |
|
可选或必选 |
可选 |
|
作用 |
跳过可融合的层。 |
|---|---|
|
类型 |
string |
|
取值范围 |
可融合层的层名。 当前支持融合的层以及融合规则请参见工具实现的融合功能。 |
|
参数说明 |
不需要做融合的层。 |
|
推荐配置 |
- |
|
可选或必选 |
可选 |
|
作用 |
指定某个网络层的量化配置。 |
|---|---|
|
类型 |
object |
|
取值范围 |
- |
|
参数说明 |
参数内部包含如下参数:
|
|
推荐配置 |
- |
|
必选或可选 |
可选 |
|
作用 |
该层是否做量化。 |
|---|---|
|
类型 |
bool |
|
取值范围 |
true或false |
|
参数说明 |
|
|
推荐配置 |
true |
|
必选或可选 |
可选 |
|
作用 |
DMQ均衡算法中的迁移强度。 |
|---|---|
|
类型 |
float |
|
取值范围 |
[0.2, 0.8] |
|
参数说明 |
代表将activation数据上的量化难度迁移至weight权重的程度,数据分布的离群值越大迁移强度应设置较小。 |
|
推荐配置 |
0.5 |
|
必选或可选 |
可选 |
|
作用 |
该层数据量化的参数。 |
|---|---|
|
类型 |
object |
|
取值范围 |
- |
|
参数说明 |
activation_quant_params内部包含如下参数,IFMR算法相关参数与HFMG算法相关参数在同一层中不能同时出现:
|
|
推荐配置 |
- |
|
必选或可选 |
可选 |
|
作用 |
该层权重量化的参数。 |
|---|---|
|
类型 |
object |
|
取值范围 |
- |
|
参数说明 |
|
|
推荐配置 |
- |
|
必选或可选 |
可选 |
|
作用 |
量化位宽。 |
|---|---|
|
类型 |
int |
|
取值范围 |
8或16 |
|
参数说明 |
当前仅支持配置为8,表示采用INT8量化位宽。 |
|
推荐配置 |
- |
|
必选或可选 |
必选 |
|
作用 |
数据量化算法。 |
|---|---|
|
类型 |
string |
|
取值范围 |
ifmr或者hfmg |
|
参数说明 |
IFMR数据量化算法:ifmr HFMG数据量化算法:hfmg |
|
推荐配置 |
- |
|
必选或可选 |
可选 |
|
作用 |
控制数据量化是对称量化还是非对称量化。用于控制逐层量化算法的选择。 若配置文件中同时存在activation_offset和asymmetric参数,asymmetric参数优先级>activation_offset参数。 |
|---|---|
|
类型 |
bool |
|
取值范围 |
true或false |
|
参数说明 |
|
|
推荐配置 |
true |
|
必选或可选 |
可选 |
|
作用 |
IFMR数据量化算法中,最大值搜索位置参数。 |
|---|---|
|
类型 |
float |
|
取值范围 |
(0.5,1] |
|
参数说明 |
在从大到小排序的一组数中,决定取第多少大的数,比如有100个数,1.0表示取第100-100*1.0=0,对应的就是第一个大的数。 对待量化的数据做截断处理时,该值越大,说明截断的上边界越接近待量化数据的最大值。 |
|
推荐配置 |
0.999999 |
|
必选或可选 |
可选 |
|
作用 |
IFMR数据量化算法中,最小值搜索位置参数。 |
|---|---|
|
类型 |
float |
|
取值范围 |
(0.5,1] |
|
参数说明 |
在从小到大排序的一组数中,决定取第多少小的数,比如有100个数,1.0表示取第100-100*1.0=0,对应的就是第一个小的数。 对待量化的数据做截断处理时,该值越大,说明截断的下边界越接近待量化数据的最小值。 |
|
推荐配置 |
0.999999 |
|
必选或可选 |
可选 |
|
作用 |
IFMR数据量化算法中,控制量化因子的搜索范围[search_range_start, search_range_end]。 |
|---|---|
|
类型 |
list,列表中两个元素类型为float。 |
|
取值范围 |
0<search_range_start<search_range_end |
|
参数说明 |
控制截断的上边界的浮动范围。
|
|
推荐配置 |
[0.7,1.3] |
|
必选或可选 |
可选 |
|
作用 |
IFMR数据量化算法中,控制量化因子的搜索步长。 |
|---|---|
|
类型 |
float |
|
取值范围 |
(0, (search_range_end-search_range_start)] |
|
参数说明 |
控制截断的上边界的浮动范围步长,值越小,浮动步长越小。 |
|
推荐配置 |
0.01 |
|
必选或可选 |
可选 |
|
作用 |
HFMG数据量化算法用于调整直方图的bin(直方图中的一个最小单位直方图形)数目。 |
|---|---|
|
类型 |
unsigned int |
|
取值范围 |
{1024, 2048, 4096, 8192} |
|
参数说明 |
num_of_bins数值越大,直方图拟合原始数据分布的能力越强,可能获得更佳的量化效果,但训练后量化过程的耗时也会更长。 |
|
推荐配置 |
4096 |
|
必选或可选 |
HFMG算法量化场景下,该参数可选。 |
|
作用 |
权重量化算法。 |
|---|---|
|
类型 |
string |
|
取值范围 |
arq_quantize |
|
参数说明 |
均匀量化取值:arq_quantize |
|
推荐配置 |
- |
|
必选或可选 |
可选 |
|
作用 |
ARQ权重量化算法中,是否对每个channel采用不同的量化因子。 |
|---|---|
|
类型 |
bool |
|
取值范围 |
true或false |
|
参数说明 |
|
|
推荐配置 |
true |
|
必选或可选 |
可选 |