MrgSort
函数功能
将已经排好序的最多4条队列,合并排列成1条队列,结果按照score域由大到小排序。
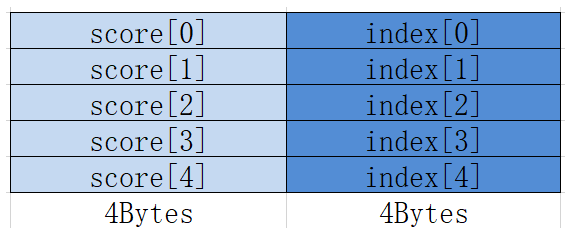
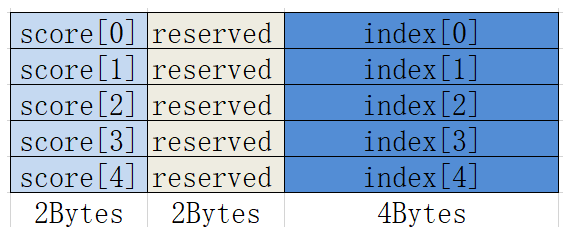
函数原型
1 2 | template <typename T> __aicore__ inline void MrgSort(const LocalTensor<T>& dstLocal, const MrgSortSrcList<T>& srcLocal, const MrgSort4Info& params) |
参数说明
参数名 |
描述 |
|---|---|
T |
Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas 200/500 A2推理产品,支持的数据类型为:half/float |
参数名称 |
输入/输出 |
含义 |
||
|---|---|---|---|---|
dstLocal |
输出 |
目的操作数,存储经过排序后的数据。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 |
||
srcLocal |
输入 |
源操作数,4个队列,并且每个队列都已经排好序,类型为MrgSortSrcList结构体,定义如下:
源操作数的数据类型与目的操作数保持一致。src1、src2、src3、src4类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 |
||
params |
输入 |
排序所需参数,类型为MrgSort4Info结构体,具体请参考表3。 |
参数名称 |
输入/输出 |
含义 |
|---|---|---|
elementLengths |
输入 |
四个源队列的长度(8Bytes结构的数目),类型为长度为4的uint16_t数据类型的数组,理论上每个元素取值范围[0, 4095],但不能超出UB的存储空间。 |
ifExhaustedSuspension |
输入 |
某条队列耗尽后,指令是否需要停止,类型为bool,默认false。 |
validBit |
输入 |
有效队列个数,取值如下:
|
repeatTimes |
输入 |
迭代次数,每一次源操作数和目的操作数跳过四个队列总长度。取值范围:repeatTimes∈[1,255]。 repeatTimes参数生效是有条件的,需要同时满足以下四个条件:
|
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas 200/500 A2推理产品
约束说明
- 当存在score[i]与score[j]相同时,如果i>j,则score[j]将首先被选出来,排在前面。
- 每次迭代内的数据会进行排序,不同迭代间的数据不会进行排序。
- 需要注意此函数排序的队列非region proposal结构。
- 操作数地址偏移对齐要求请参见通用约束。
调用示例
- 接口使用样例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// 对8个已排好序的队列进行合并排序,repeatTimes = 2,数据连续存放 // 每个队列包含32个(score,index)的8Bytes结构 // 最后输出对score域的256个数完成排序后的结果 AscendC::MrgSort4Info params; params.elementLengths[0] = 32; params.elementLengths[1] = 32; params.elementLengths[2] = 32; params.elementLengths[3] = 32; params.ifExhaustedSuspension = false; params.validBit = 0b1111; params.repeatTimes = 2; AscendC::MrgSortSrcList<float> srcList; srcList.src1 = workLocal[0]; srcList.src2 = workLocal[64]; // workLocal为float类型,每个队列占据256Bytes空间 srcList.src3 = workLocal[128]; srcList.src4 = workLocal[192]; AscendC::MrgSort<float>(dstLocal, srcList, params);
- 完整样例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92
#include "kernel_operator.h" class KernelMrgSort { public: __aicore__ inline KernelMrgSort() {} __aicore__ inline void Init(__gm__ uint8_t* src0Gm, __gm__ uint8_t* src1Gm, __gm__ uint8_t* dstGm) { srcGlobal0.SetGlobalBuffer((__gm__ float*)src0Gm); srcGlobal1.SetGlobalBuffer((__gm__ uint32_t*)src1Gm); dstGlobal.SetGlobalBuffer((__gm__ float*)dstGm); repeat = srcDataSize / 32; pipe.InitBuffer(inQueueSrc0, 1, srcDataSize * sizeof(float)); pipe.InitBuffer(inQueueSrc1, 1, srcDataSize * sizeof(uint32_t)); pipe.InitBuffer(workQueue, 1, dstDataSize * sizeof(float)); pipe.InitBuffer(outQueueDst, 1, dstDataSize * sizeof(float)); } __aicore__ inline void Process() { CopyIn(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { AscendC::LocalTensor<float> srcLocal0 = inQueueSrc0.AllocTensor<float>(); AscendC::DataCopy(srcLocal0, srcGlobal0, srcDataSize); inQueueSrc0.EnQue(srcLocal0); AscendC::LocalTensor<uint32_t> srcLocal1 = inQueueSrc1.AllocTensor<uint32_t>(); AscendC::DataCopy(srcLocal1, srcGlobal1, srcDataSize); inQueueSrc1.EnQue(srcLocal1); } __aicore__ inline void Compute() { AscendC::LocalTensor<float> srcLocal0 = inQueueSrc0.DeQue<float>(); AscendC::LocalTensor<uint32_t> srcLocal1 = inQueueSrc1.DeQue<uint32_t>(); AscendC::LocalTensor<float> workLocal = workQueue.AllocTensor<float>(); AscendC::LocalTensor<float> dstLocal = outQueueDst.AllocTensor<float>(); AscendC::Sort32<float>(workLocal, srcLocal0, srcLocal1, repeat); // 先构造4个排好序的队列 AscendC::MrgSort4Info params; params.elementLengths[0] = 32; params.elementLengths[1] = 32; params.elementLengths[2] = 32; params.elementLengths[3] = 32; params.ifExhaustedSuspension = false; params.validBit = 0b1111; params.repeatTimes = 1; AscendC::MrgSortSrcList<float> srcList; srcList.src1 = workLocal[0]; srcList.src2 = workLocal[32 * 1 * 2]; srcList.src3 = workLocal[32 * 2 * 2]; srcList.src4 = workLocal[32 * 3 * 2]; AscendC::MrgSort<float>(dstLocal, srcList, params); outQueueDst.EnQue<float>(dstLocal); inQueueSrc0.FreeTensor(srcLocal0); inQueueSrc1.FreeTensor(srcLocal1); workQueue.FreeTensor(workLocal); } __aicore__ inline void CopyOut() { AscendC::LocalTensor<float> dstLocal = outQueueDst.DeQue<float>(); AscendC::DataCopy(dstGlobal, dstLocal, dstDataSize); outQueueDst.FreeTensor(dstLocal); } private: AscendC::TPipe pipe; AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueSrc0; AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueSrc1; AscendC::TQue<AscendC::QuePosition::VECIN, 1> workQueue; AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueueDst; AscendC::GlobalTensor<float> srcGlobal0, dstGlobal; AscendC::GlobalTensor<uint32_t> srcGlobal1; int srcDataSize = 128; int dstDataSize = 256; int repeat = 0; }; extern "C" __global__ __aicore__ void vec_mrgsort_kernel(__gm__ uint8_t* src0Gm, __gm__ uint8_t* src1Gm, __gm__ uint8_t* dstGm) { KernelMrgSort op; op.Init(src0Gm, src1Gm, dstGm); op.Process(); }
示例结果 输入数据(src0Gm): 128个float类型数据 [2.9447467 7.546607 5.083544 1.6373866 3.4730997 5.488915 6.2410192 6.5340915 9.534971 8.217815 7.922645 9.9135275 9.34575 8.0759535 6.40329 7.2240252 8.792965 4.9348564 7.726399 2.3075738 5.8587966 3.3077633 1.5605974 5.582237 9.38379 8.583278 3.2116296 7.5197206 1.3169404 9.355466 3.6663866 6.3373866 4.188842 1.1831555 6.3235407 7.0127134 1.9593428 9.316625 5.7821383 4.980949 4.4211564 1.0478534 9.626102 4.52559 5.151449 3.4274218 9.874416 8.040044 5.049376 3.8079789 9.16666 7.803004 9.288373 5.497965 2.2784562 8.752271 1.2586805 7.161625 5.807935 2.9983459 4.980592 1.1796398 8.89327 9.35524 5.0074706 2.108345 8.4992285 2.7219095 9.544726 4.4516068 6.940215 1.424632 5.473264 7.7971754 6.730119 3.3760135 1.3578739 8.965629 5.5441265 1.9234481 6.1590824 3.62707 8.257497 6.5762696 3.6241028 1.870233 8.303693 7.5986104 7.211784 9.259263 2.9631793 5.9183855 1.911052 8.445708 3.1592433 5.434683 5.2764387 2.013458 2.5766358 1.3793333 6.4866495 6.957988 8.711433 4.1000323 1.973415 1.5109203 6.830736 7.871973 6.130566 2.5669708 9.317494 4.4140983 8.086401 3.1740563 9.000416 6.2852535 2.170213 4.6842256 5.939913 1.3967329 9.959876 7.9772205 5.874416 4.4834223 3.6719642 8.462775 2.3629668 2.886413 ] 输入数据(src1Gm): [0,0,0,0,...,0] 输出数据(dstGm): [9.959876 0. 9.9135275 0. 9.874416 0. 9.626102 0. 9.544726 0. 9.534971 0. 9.38379 0. 9.355466 0. 9.35524 0. 9.34575 0. 9.317494 0. 9.316625 0. 9.288373 0. 9.259263 0. 9.16666 0. 9.000416 0. 8.965629 0. 8.89327 0. 8.792965 0. 8.752271 0. 8.711433 0. 8.583278 0. 8.4992285 0. 8.462775 0. 8.445708 0. 8.303693 0. 8.257497 0. 8.217815 0. 8.086401 0. 8.0759535 0. 8.040044 0. 7.9772205 0. 7.922645 0. 7.871973 0. 7.803004 0. 7.7971754 0. 7.726399 0. 7.5986104 0. 7.546607 0. 7.5197206 0. 7.2240252 0. 7.211784 0. 7.161625 0. 7.0127134 0. 6.957988 0. 6.940215 0. 6.830736 0. 6.730119 0. 6.5762696 0. 6.5340915 0. 6.4866495 0. 6.40329 0. 6.3373866 0. 6.3235407 0. 6.2852535 0. 6.2410192 0. 6.1590824 0. 6.130566 0. 5.939913 0. 5.9183855 0. 5.874416 0. 5.8587966 0. 5.807935 0. 5.7821383 0. 5.582237 0. 5.5441265 0. 5.497965 0. 5.488915 0. 5.473264 0. 5.434683 0. 5.2764387 0. 5.151449 0. 5.083544 0. 5.049376 0. 5.0074706 0. 4.980949 0. 4.980592 0. 4.9348564 0. 4.6842256 0. 4.52559 0. 4.4834223 0. 4.4516068 0. 4.4211564 0. 4.4140983 0. 4.188842 0. 4.1000323 0. 3.8079789 0. 3.6719642 0. 3.6663866 0. 3.62707 0. 3.6241028 0. 3.4730997 0. 3.4274218 0. 3.3760135 0. 3.3077633 0. 3.2116296 0. 3.1740563 0. 3.1592433 0. 2.9983459 0. 2.9631793 0. 2.9447467 0. 2.886413 0. 2.7219095 0. 2.5766358 0. 2.5669708 0. 2.3629668 0. 2.3075738 0. 2.2784562 0. 2.170213 0. 2.108345 0. 2.013458 0. 1.973415 0. 1.9593428 0. 1.9234481 0. 1.911052 0. 1.870233 0. 1.6373866 0. 1.5605974 0. 1.5109203 0. 1.424632 0. 1.3967329 0. 1.3793333 0. 1.3578739 0. 1.3169404 0. 1.2586805 0. 1.1831555 0. 1.1796398 0. 1.0478534 0. ]
父主题: 矢量计算