TIK算子实现流程
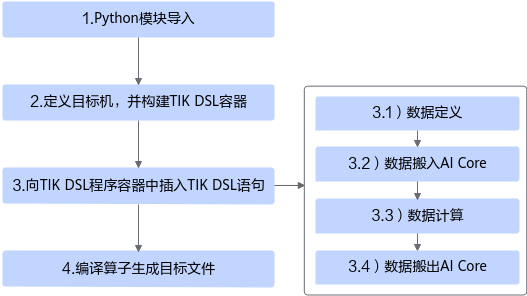
基于TIK API编写TIK算子Python程序的通用步骤,如下图所示。
图1 算子实现流程(AICore)

如果算子过大(比如算子某个作用域内变量嵌套层数过大的场景),占用空间超限,编译时可能会出现因系统资源不足导致的报错,可尝试通过命令 “ulimit -s”临时增大堆栈空间来解决,例如堆栈空间默认为8MB的情况下,通过ulimit -s 16384将其增大至16MB。
代码结构如下所示:
# 导入依赖的Python模块 from tbe import tik import tbe.common.platform as tbe_platform from tbe.common.utils import para_check import numpy as np # 算子定义入口函数,即为算子运行时调用的函数,定义可参见TIK入口函数 @para_check.check_input_type(dict, dict, dict, str) def operation_name(input_x, input_y, output_z, kernel_name): # 定义目标机,即设置昇腾AI处理器的版本,默认运行目标为AI Core # soc_version请配置为用户当前实际使用的昇腾AI处理器的型号 tbe_platform.set_current_compile_soc_info(soc_version) # 构建TIK DSL容器 tik_instance = tik.Tik(disable_debug=False) # 进行数据定义 data_x = tik_instance.Tensor("dtype", shape, name="data_x", scope=tik.scope_gm) ... ... data_x_ub = tik_instance.Tensor("dtype", shape, name="data_x_ub", scope=tik.scope_ubuf) # 将数据搬入指定的Core tik_instance.data_move(data_x_ub, data_x, ...) # 进行数据计算 tik_instance.vec_xxx(...) # 将数据搬出指定的Core tik_instance.data_move(data_x, data_x_ub, ...) # 将算子编译成目标文件,TIK编译函数定义可参见TIK编译函数 tik_instance.BuildCCE(kernel_name="simple_add",inputs=[data_A,data_B],outputs=[data_C]) # 返回TIK示例 return tik_instance
父主题: 算子代码实现(TBE TIK)