多Device上执行模型不同导致应用程序出错
问题现象
分布式训练或推理场景,执行业务脚本时,出现进程卡死的情况。
搜索打屏日志关键字“The model has been compiled on the Ascend AI processor, current graph id is”,假设共8个Device,结果显示如下:
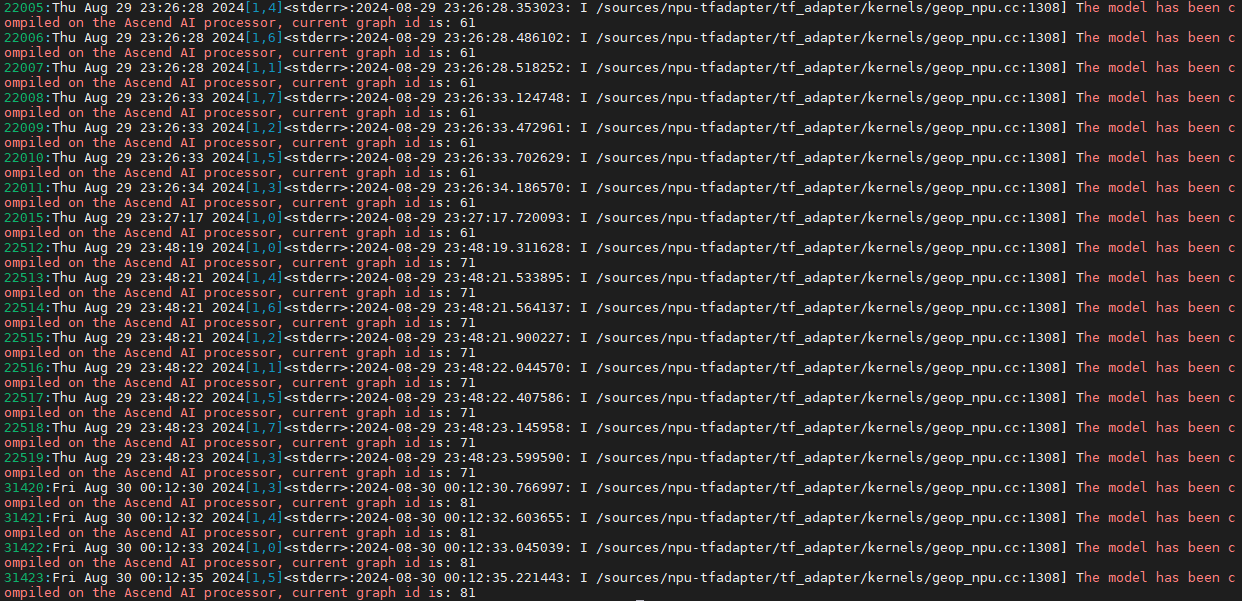
正常情况下,每个Device上都应该有相同的graph id,且个数相同。但由上述日志可以看出,ID为61、71的graph共有8个,为正常情况;而ID为81的graph仅有4个,多个Device上的graph存在差异。
原因分析
执行多Device任务时,由于Device上执行的模型不一致触发了部分Device上的模型重新编译,导致HCCL算子的ID信息不一致,通信功能异常而出现进程卡死。
TensorFlow网络触发模型重新编译的原理如下:
用户脚本调用session.run接口时,会查找或创建相应的图执行器,如果图发生变化,就无法从之前图编译的缓存中命中相应的执行器,TensorFlow就会重新创建执行器并重新编译图。重新编译图会造成HCCL算子的ID不一致,从而导致HCCL通信失败。
解决方法
开发者需要排查业务脚本,找出不同Device上的模型执行差异点并修改。
一般排查的方法主要有(仅为经验总结,排查方法不限于以下几点):
- 排查脚本中是否存在类似于“if (xxx % rank_id) == n”格式的相关逻辑,此逻辑可能会造成不同设备上执行的图结构不一致。
- 排查是否有出现部分Device打开tf.summary的情况,tf.summary会导致模型重新编译。
父主题: FAQ