简介
图像/视频数据处理的典型使用场景
如果源图或视频的分辨率、格式等与模型的要求不一致时,我们可以将源图或视频处理成符合模型的要求。如下为典型场景的举例。
- 视频解码、缩放。
使用Yolov3模型实现目标检测的场景下,用户提供的输入视频为H264/H265编码格式、分辨率为1920*1080,但Yolov3模型要求的输入图片格式为RGB/YUV、分辨率为416*416,两者不一致,此时可对视频执行以下一系列处理。
图1 视频解码、缩放使用场景图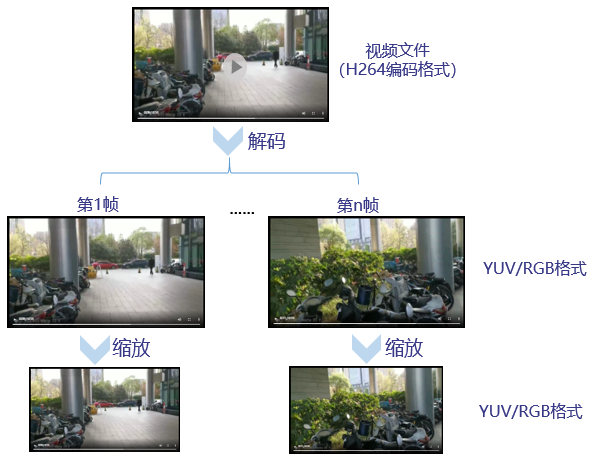
- 图片解码、缩放、格式转换。
使用Resnet50模型实现图片分类的场景下,用户提供的输入图片为JPEG编码格式、分辨率为1280*720,但Resnet50模型要求的输入图片格式为RGB、分辨率为224*224,两者不一致,此时可对图片执行以下一系列处理。
图2 图片解码、缩放、格式转换使用场景图
- 抠图、缩放、格式转换。
使用Resnet50模型实现图片分类的场景下,用户提供的输入图片格式为YUV420SP、分辨率为1280*720,但Resnet50模型要求的输入图片格式为RGB、分辨率为224*224,两者不一致,此时对图片执行以下一系列处理。
图3 抠图、缩放、格式转换使用场景图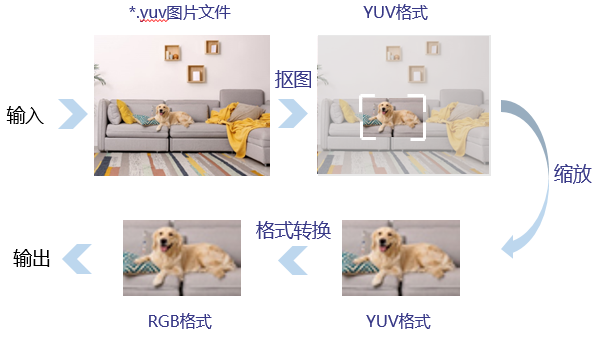
图像/视频数据处理的多种方式
昇腾CANN提供了下表中的两种处理图像/视频数据的方式,本章主要介绍基于DVPP的图像/视频数据处理。
AIPP、DVPP可以分开独立使用,也可以组合使用。组合使用场景下,一般先使用DVPP对图片/视频进行解码、抠图、缩放等基本处理,但由于DVPP硬件上的约束,DVPP处理后的图片格式、分辨率有可能不满足模型的要求,因此还需要再经过AIPP进一步做色域转换、抠图、填充等处理。
例如,在昇腾310 AI处理器和昇腾910 AI处理器上,由于DVPP仅支持输出YUV格式的图片,如果模型需要RGB格式的图片,则需要再经过AIPP做色域转换的处理。
处理图像/视频数据的方式 |
描述 |
|---|---|
AIPP(Artificial Intelligence Pre-Processing) |
AIPP(Artificial Intelligence Pre-Processing)人工智能预处理,在AI Core上完成数据预处理,主要功能包括改变图像尺寸(抠图、填充等)、色域转换(转换图像格式)、减均值/乘系数(改变图像像素)等。
AIPP区分为静态AIPP和动态AIPP。您只能选择静态AIPP或动态AIPP方式来处理图片,不能同时配置静态AIPP和动态AIPP两种方式。
|
DVPP(Digital Vision Pre-Processing) |
DVPP(Digital Vision Pre-Processor)是昇腾AI处理器内置的图像处理单元,通过pyACL媒体数据处理接口提供强大的媒体处理硬加速能力,主要功能包括缩放、抠图、格式转换、图片编解码、视频编解码等。 |
pyACL提供了哪些图像/视频数据处理的功能
- pyACL提供了基于DVPP硬件的媒体数据处理接口,功能如下表所示。本章主要介绍这部分接口的调用流程和示例代码。
表1 功能说明 功能
说明
VPC(Vision Preprocessing Core)
处理YUV、RGB等格式的图片,包括缩放、抠图、图像金字塔、色域转换等。
JPEGD(JPEG Decoder)
JPEG压缩格式-->YUV格式的图片解码。
JPEGE(JPEG Encoder)
YUV格式-->JPEG压缩格式的图片编码。
VDEC(Video Decoder)
H264/H265格式-->YUV/RGB格式的视频码流解码。
VENC(Video Encoder)
YUV420SP格式-->H264/H265格式的视频码流编码。
PNGD(PNG decoder)
PNG格式-->RGB格式的图片解码。
- pyACL还提供了动态AIPP参数的设置接口,请参见模型动态AIPP推理中的介绍。