非均匀量化
非均匀量化是指量化后的数据在某个数值空间中的分布是不均匀的。非均匀量化过程中,会根据待量化数据的概率分布来对均匀量化后的数据分布进一步进行根据目标压缩率(保留数值量/原始量化数值量)的聚类操作。相较于均匀量化,非均匀量化在进一步压缩数据信息量的基础上尽可能的保留高概率分布的数据信息,从而减小压缩后的数据信息丢失。

由于硬件约束,该版本不建议使用非均匀量化的功能,获取不到性能收益。
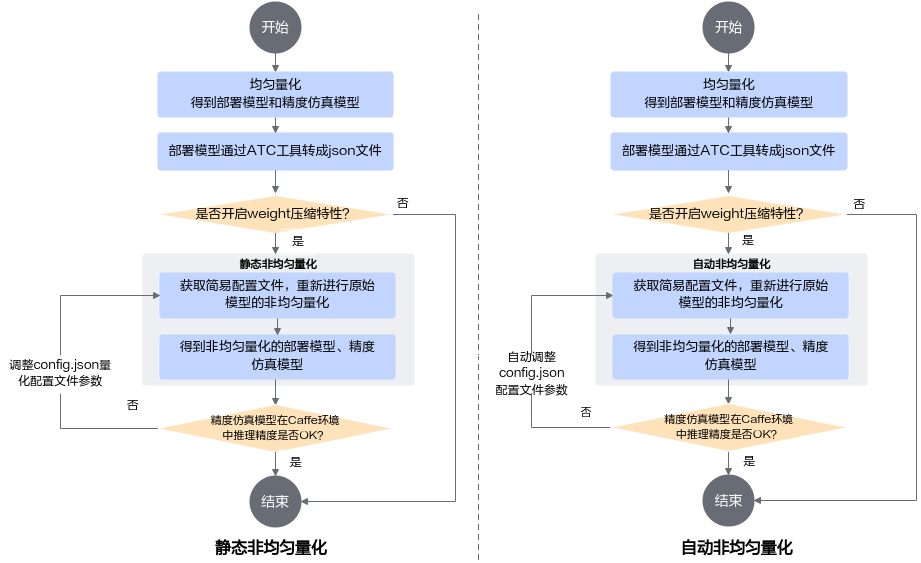
模型在昇腾AI处理器上推理时,可通过非均匀量化提高权重压缩率(需要与ATC工具配合,通过编译时使能权重压缩),降低权重传输开销,进一步提升推理性能。非均匀量化后,如果精度仿真模型在原始Caffe环境中推理精度不满足要求,可通过调整非均匀量化配置文件config.json中的参数来恢复模型精度,根据是否自动调整量化配置文件,非均匀量化又分为静态非均匀量化和自动非均匀量化。
- 静态非均匀量化:需要用户参见手工调优章节手动调整相应参数。详细量化过程请参见获取更多样例>resnet50>执行静态非均匀量化。
- 自动非均匀量化:由AMCT自动搜索出一个量化配置,在满足给出的精度损失要求前提下使得量化后的模型压缩率更高。该场景下用户需要基于给出的自动非均匀量化基类(AutoNuqEvaluatorBase)实现一个子类,需要实现eval_model(self, model_file, weights_file, batch_num)和is_satisfied(self, original_metric, new_metric) 两个方法:
- eval_model根据输入的模型和batch_num进行数据前处理、模型推理、数据后处理,得到模型的评估结果,要求返回的评估结果唯一,如分类网络的top1, 检测网络的mAP等,同时也可以是指标的加权结果。
- is_satisfied用于判断量化后的模型是否达到了精度损失的要求,如果达到了则返回True, 否则返回 False;如分类网络的top1用小数表示,则判断条件可以写作if (original_metric - new_metric) * 100 < 1, 表示精度的损失要小于1个百分点。
详细量化示例请参见获取更多样例>resnet50>执行自动非均匀量化。
非均匀量化支持量化的层以及约束如下:
|
量化方式 |
支持的层类型 |
约束 |
|---|---|---|
|
非均匀量化 |
Convolution:卷积层 |
dilation为1、group为1、filter维度为4 |
|
InnerProduct:全连接层 |
transpose属性为false,axis为1 |
接口调用流程
非均匀量化接口调用流程如图1所示。非均匀量化不支持多个GPU同时运行。
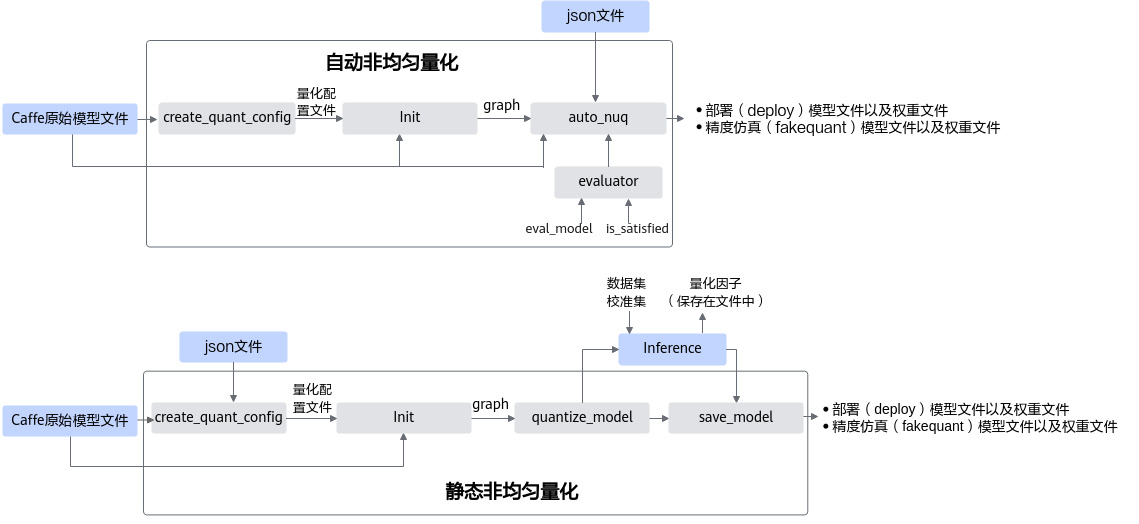
下面以自动非均匀量化为例介绍主要流程,静态非均匀量化流程请参见均匀量化。
- 用户首先构造Caffe的原始模型,然后使用create_quant_config生成量化配置文件。
- 根据Caffe模型和量化配置文件,调用init接口,初始化工具,配置量化因子存储文件,将模型解析为图结构graph。
- 根据原始模型文件、通过ATC工具转换的json文件(该文件携带了支持weight压缩特性层的信息,通过fe_weight_compress字段识别)调用auto_nuq进行自动非均匀量化,该过程中会调用由用户传入的evaluator实例进行精度测试,得到原始模型精度。
简要流程如图2所示。
调用示例
- 导入AMCT包。
1 2
import amct_caffe as amct from amct_caffe.auto_nuq import AutoNuqEvaluatorBase
- 根据给定的AutoNuqEvaluatorBase基类实现一个子类,需要实现能够得到模型精度的评估方法eval_model和判断当前的量化后模型是否精度达标的is_satisfied方法。
1 2 3 4 5
class AutoNuqEvaluator(AutoNuqEvaluatorBase): # Auto Nuq Evaluator def __init__(self, evaluate_batch_num): super().__init__(self) self.evaluate_batch_num = evaluate_batch_num
- 实现模型精度评估方法eval_model。
eval_model根据输入的模型和batch_num进行数据前处理、模型推理、数据后处理,得到模型的评估结果,要求返回的评估结果唯一,如分类网络的top1, 检测网络的mAP等,同时也可以是指标的加权结果。
1 2
def eval_model(self, model_file, weights_file, batch_num): return do_benchmark_test(QUANT_ARGS, model_file, weights_file, batch_num)
- 实现精度损失的评估方法is_satisfied。
is_satisfied用于判断量化后的模型是否达到了精度损失的要求,如果达到了则返回True, 否则返回 False;如分类网络的top1用小数表示,则判断条件可以写作if (original_metric - new_metric) *100 < 1, 表示精度的损失要小于1个百分点。
- original_metric代表原始未量化模型精度。
- new_metric代表量化后fake quant模型精度,根据精度损失是否满足阈值返回True或False。
1 2 3 4 5
def is_satisfied(self, original_metric, new_metric): # the loss of top1 acc need to be less than 1% if (original_metric - new_metric) * 100 < 1: return True return False
- 实现模型精度评估方法eval_model。
- 生成量化配置文件。
1 2 3 4 5 6 7 8 9 10 11 12
config_json_file = os.path.join(TMP, 'config.json') skip_layers = [] batch_num = 2 activation_offset = True # do weights calibration with non uniform quantize configure amct.create_quant_config( config_json_file, args.model_file, args.weights_file, skip_layers, batch_num, activation_offset, args.cfg_define) scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt') result_path = os.path.join(RESULT, 'ResNet50')
- 开始自动非均匀量化流程。
1 2 3 4 5 6 7 8
evaluator = AutoNuqEvaluator(args.iterations) amct.auto_nuq( args.model_file, args.weights_file, evaluator, config_json_file, scale_offset_record_file, result_path)
父主题: 手工量化