背景介绍
大模型推理的核心工作是优化模型推理,实现推理加速,其中模型推理最核心的部分是Transformer Block。
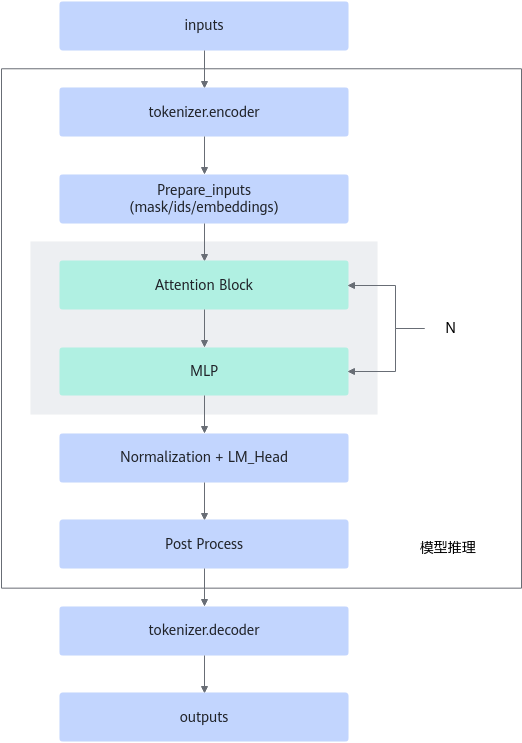
大模型整体的推理流程可以简单分为4个部分,主体流程见图2。
- 前处理:输入数据的前置准备过程,包括Input Embedding/postion_id/attention_mask等生成。
- Transformer Block:主体为Attention层和MLP层,单个模型中通常包含N个结构相同的Transfromer Block。
- LM_Head:一般为全连接层。
- 后处理:包括但不限于Sampling/Beam Search/Greedy Search。
对于常见的生成式任务,大模型的推理流程包括两个部分:全量推理(Encode)和增量推理(Decode)。其中,全量推理是全量输入生成的中间数据,增量推理则是新生成的token进行不断迭代的过程。对于Decoder-Only结构的模型,全量推理和增量推理的模型结构是一致的。
图1 大模型推理流程
Transformer Block部分为最主要的模型结构,其核心结构如图2所示,不同模型之间存在区别。
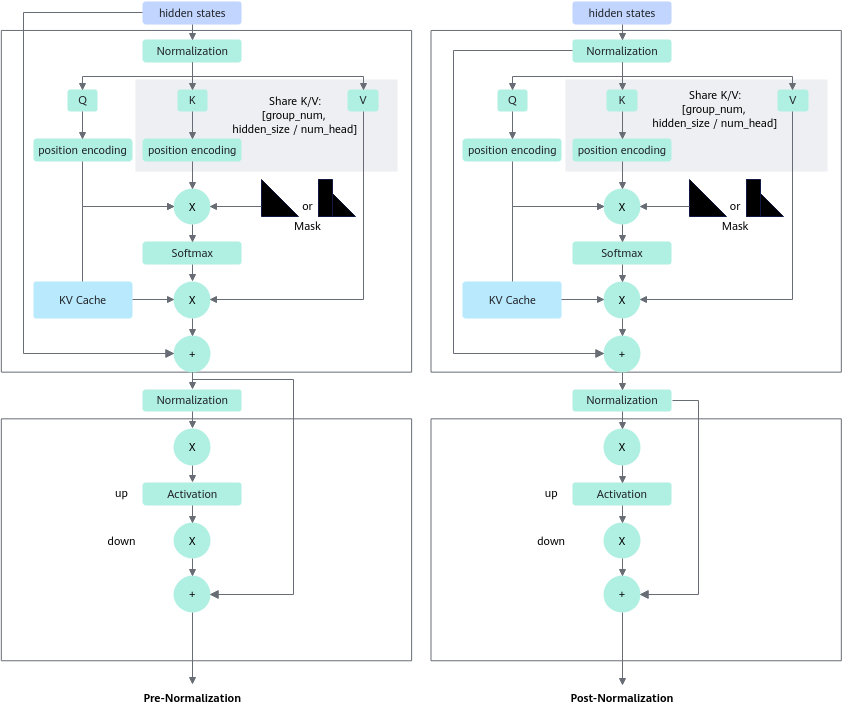
不同模型的配置存在差异,详细说明见表1。
模型名 |
Attention Mask |
Position Encoding |
Normalization |
Attention Type |
Activation |
|---|---|---|---|---|---|
GLM |
prefix |
RoPE |
Pre Deep Norm |
Multi Head Attention |
GELU |
ChatGLM |
prefix |
RoPE |
|
|
GELU SwinGlu |
LLaMA |
causal |
RoPE |
Pre RMS Norm |
|
SwinGlu |
Bloom |
causal |
ALiBi |
Pre Layer Norm |
Multi Head Attention |
GELU |
父主题: 大模型推理迁移