自定义融合算子替换优化调优案例
问题背景
当前部分算子接口已经进行了NPU亲和优化,并提升了性能。将算子替换为高性能的NPU亲和自定义算子,可以优化性能。本调优案例以已经适配NPU的EfficientNet模型为例,介绍此性能调优方法。
总体思路
将已经进行了NPU亲和优化的算子替换为NPU自定义算子。NPU自定义算子信息可参考API列表中“{对应的PyTorch版本号}>PyTorch Adapter自定义API>torch_npu/torch_npu.contrib”章节。
瓶颈识别
- 打开模型脚本main.py。
cd examples/imagenet vi main.py
- 请参考Profiling数据采集及分析,在模型脚本main.py中添加使能profiling的代码。注意添加prof.export_chrome_trace('./***.json')代码导出chrome trace的json文件。
- 拉起模型训练,进行profiling,生成json文件。以下命令以单卡训练为例。
bash ./test/train_performance_1p.sh --data_path=/data/xxx/ # 请根据实际情况更改data_path
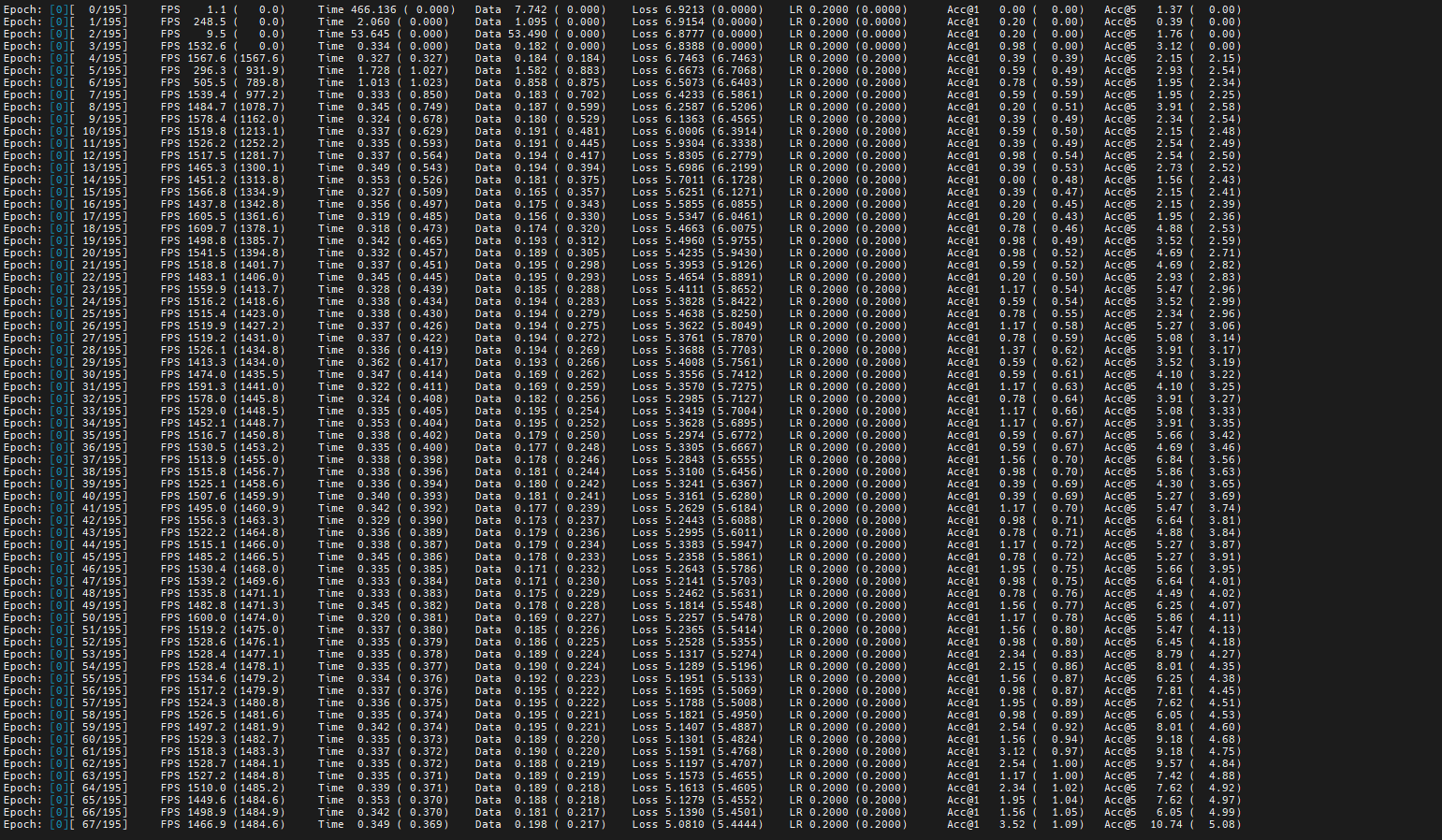
以训练一个epoch为例,耗时如下图。
- 在Chrome浏览器中输入“chrome://tracing”地址,将json文件拖到空白处打开,通过键盘上的快捷键(w:放大, s:缩小, a:左移, d:右移)进行查看。
可以发现在使用Swish函数时,引入了小算子,影响了性能。



性能调优
昇腾PyTorch目前以支持NPU自定义算子torch_npu.npu_silu(),可以替换原模型代码中的Swish函数,提升性能。
- 进入模型脚本utils.py。
cd efficientnet_pytorch vi utils.py
- 在该脚本开头添加库代码。
import torch_npu
- 找到当前Swish函数的调用代码,代码如下。
# A memory-efficient implementation of Swish function class SwishImplementation(torch.autograd.Function): @staticmethod def forward(ctx, i): result = i * torch.sigmoid(i) ctx.save_for_backward(i) return result @staticmethod def backward(ctx, grad_output): i = ctx.saved_tensors[0] sigmoid_i = torch.sigmoid(i) return grad_output * (sigmoid_i * (1 + i * (1 - sigmoid_i))) class MemoryEfficientSwish(nn.Module): def forward(self, x): return SwishImplementation.apply(x)检视代码,可以发现模型代码是在MemoryEfficientSwish函数中调用SwishImplementation函数来使用Swish,且Silu是Swish的一种特例。
Swish函数公式为
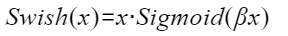
SiLU函数公式为
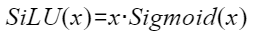
因此将class MemoryEfficientSwish中的调用方式修改为torch_npu.npu_silu()即可。
修改后代码如下:
class MemoryEfficientSwish(nn.Module): def forward(self, x): return torch_npu.npu_silu(x) - 拉起模型训练,进行profiling,生成json文件。以下命令以单卡训练为例。
bash ./test/train_performance_1p.sh --data_path=/data/xxx/ # 请根据实际情况更改data_path
以训练一个epoch为例,耗时如下图。
图5 详细耗时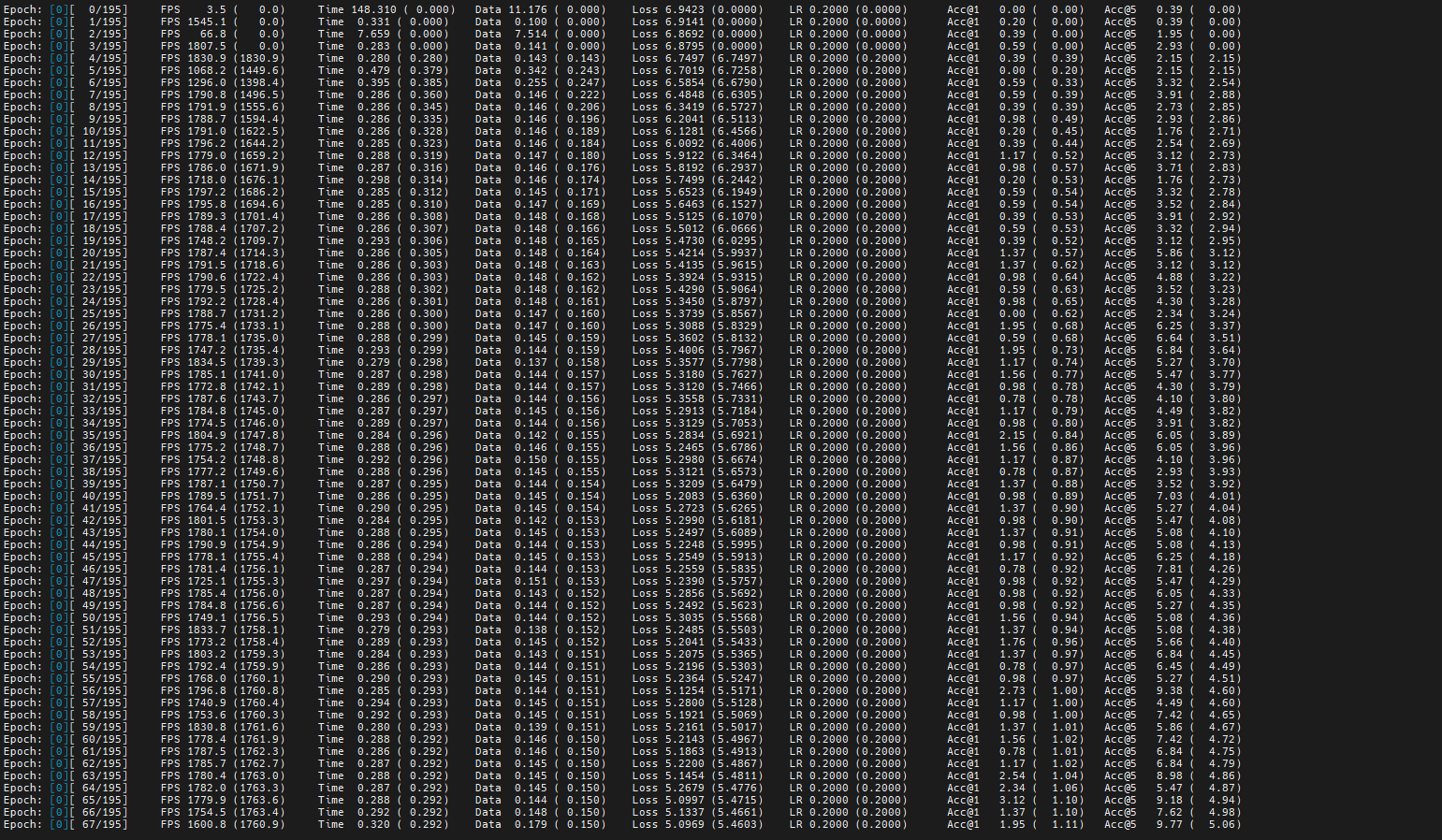 图6 训练一个epoch耗时
图6 训练一个epoch耗时
对比图1与图2中调优前的性能数据,可以发现TIME列耗时减少且每秒处理的图片数从1502.6提升到1767.2,模型性能提升。
- 在Chrome浏览器中输入“chrome://tracing”地址,将json文件拖到空白处打开,通过键盘上的快捷键(w:放大, s:缩小, a:左移, d:右移)进行查看。图7 npu_silu函数下的算子
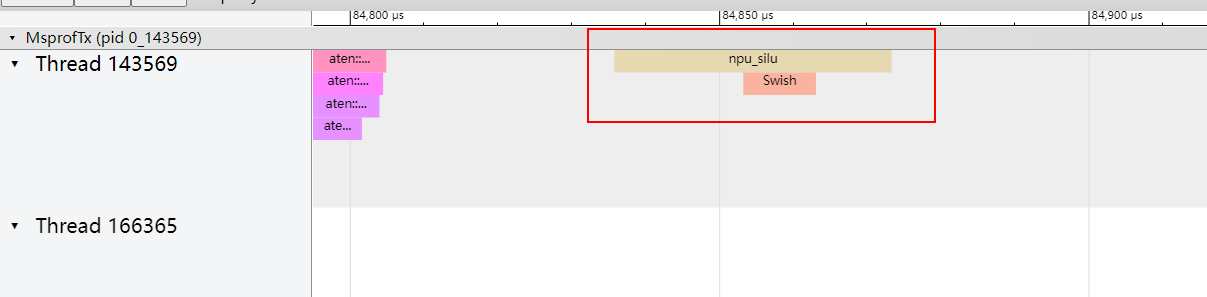 图8 npu_silu函数性能信息
图8 npu_silu函数性能信息
父主题: 进阶调优