多核
在for_range的原型定义里,用户通过设置参数block_num来实现分核并行,简单代码示例如下:
with tik_instance.for_range( 0, 10, block_num=10) as i:
示例中,for_range循环中的表达式会被作用在10个执行实例上,最终10个执行实例会被分配到10个核上并行运行,每个核拿到一个执行实例和一个不同的Block ID。如果当前可用的核的数量小于10,则执行实例会在当前可用的核上分批调度执行;如果当前可用的核的数量大于等于10,则会根据实际情况调度执行,实际运行的核数可能小于等于10。
# 请根据实际昇腾AI处理器型号进行设置 soc_version="xxx" # 设置昇腾AI处理器的型号及目标核的类型 tbe.common.platform.set_current_compile_soc_info(soc_version) tbe.common.platform.get_soc_spec("CORE_NUM") # 使用该接口前需要先设置AI处理器类型
需要注意的是:
- 采用分核并行时,Global Memory对每个核均可见,因而位于Global Memory中的张量必须定义在for_range循环外;其它存放在Scalar Buffer或Unified Buffer中的张量,只对其所在的核可见,其张量定义必须放到多核循环内部。
- block_num默认取值为1,即不分核;而采用分核并行时,其取值上限为65535,用户需要保证block_num的值不超过此阈值。
为保证负载均衡,block_num一般尽量设置为实际核数量的倍数。假设AI处理器内含32个AI Core,假如一个张量的形状为(16, 2, 32, 32, 32),如果以张量的第一维度(最外层)进行分核,则只能绑定16个核。此时,可通过将张量的第一维度和第二维度合并,使得最外层的长度变成32,以此将任务均摊到32个AI Core上,使用尽可能多的核并行处理。需要注意的是,顾及后端内存自动分配机制限制,用户实施分核并行时必须从最外层开始做维度合并。
- 一个算子中只能调用一次for_range实现分核,即设置block_num >=2,不允许多次开启多核。
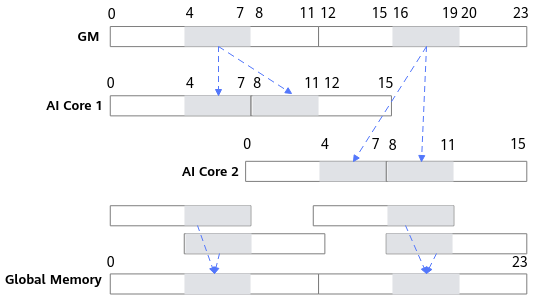
此外,分核并行特别需要注意非32 bytes对齐写入Global Memory的场景,此时存在多余的数据尾巴,导致不同AI Core往Global Memory写数据存在数据覆盖。如图1所示,一个长度为24的一维张量,数据类型为float32;利用两个AI Core进行分核并行处理并输出到Global Memory中。考虑到Unified Buffer的物理限制,数据搬运必须32 bytes对齐,则图中虚线框中数据会和正确数据一起被搬出到Global Memory,由此导致图中阴影处发生数据覆写、踩踏,最终影响计算结果的正确性。
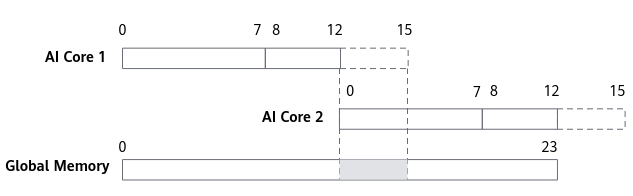
为保证输出结果的正确性,不足32 bytes的数据在搬入、搬出Unified Buffer时必须通过“地址回退”操作以防止数据踩踏。如图2所示,Global Memory中共24个float32类型的数据,数据首先一分为二,分别搬入到两个AI Core中,即AI Core 1处理数据GM[0]~GM[11],AI Core 2处理数据GM[12]~GM[23]。以AI Core 1为例,数据0~7首先从Global Memory搬运到Unified Buffer中的第一个block(32 bytes),第二次搬运不再从数据8开始,而是回退到数据4,使得搬运数据满足32bytes对齐的要求,即搬运数据4~11至第二个block,则Global Memory中数据4~7(灰色阴影)被重复搬运。当Vector完成数据计算后,Unified Buffer中两个block内的计算结果分两次搬入Global Memory,同样需要通过“地址回退”保证两个block中重复的数据重叠到Global Memory中的同一地址块中(灰色阴影)。由此,每个AI Core上不足32 bytes的数据均通过“地址回退”操作实现正确搬运,避免了数据踩踏的发生。