Data-Free模式(以squant_ptq接口为例)
本节将以模型静态shape、动态shape、图优化场景分别介绍量化配置步骤,指导用户调用Python API接口对模型进行Data-Free模式的识别和量化,并将量化后的模型保存为.onnx文件,量化后的模型可以在推理服务器上运行。
功能实现流程
用户需准备好onnx模型,调用squant_ptq接口生成量化配置脚本,运行脚本输出量化后的onnx模型,并自行转换后进行推理。
图1 squant_ptq接口功能实现流程
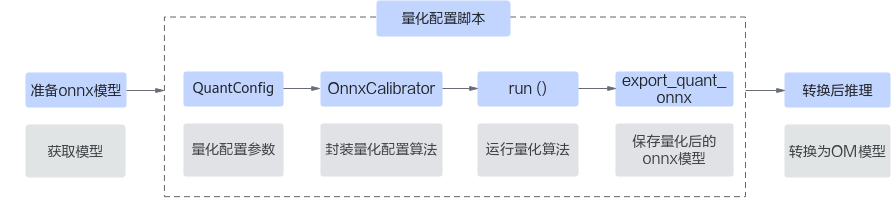
关键步骤说明如下:
- 用户准备onnx原始模型,使用QuantConfig配置量化参数,可基于如下场景进行配置。
- 静态/动态shape模型量化:用户基于量化要求进行配置,可以根据实际情况配置精度保持策略。动态shape场景下,需要手动开启is_dynamic_shape参数,并配置模型的input_shape。
- 图优化:针对静态shape模型,量化工具内置了多种图结构优化方法,支持对浮点模型和量化后模型进行图优化。使用graph_optimize_level参数开启并指定图优化级别,并支持通过shut_down_structures参数指定需关闭优化的图结构。同时,在图优化过程中需要将onnx模型转换为om模型,用户可以通过om_method参数指定转换工具。
- 根据onnx模型和调用OnnxCalibrator封装量化算法,可以根据模型量化情况配置精度保持策略。
- 初始化OnnxCalibrator后通过run ()函数执行量化。
- 调用export_quant_onnx保存量化后的模型。
- 模型转换。
前提条件
- 已参考环境准备,完成CANN开发环境的部署及Python环境变量配置。
- 训练后量化前须执行命令安装依赖。
如下命令如果使用非root用户安装,需要在安装命令后加上--user,例如:pip3 install onnx --user。
pip3 install numpy #需大于等于1.21.6版本且小于等于1.23.0版本 pip3 install onnx #需大于等于1.14.0版本 pip3 install onnxruntime #需大于等于1.14.1版本 pip3 install torch==1.11.0 #支持1.8.1和1.11.0,须为CPU版本的torch pip3 install onnx-simplifier #需大于等于0.3.10版本
静态shape模型量化步骤(以ResNet50为例)
- 用户需自行准备模型,本样例以ResNet50为例,参考对应README中“模型推理”章节,导出onnx文件。
- 新建模型的量化脚本resnet50_quant.py,编辑resnet50_quant.py文件,导入如下样例代码。
from modelslim.onnx.squant_ptq import OnnxCalibrator, QuantConfig # 导入squant_ptq量化接口 from modelslim import set_logger_level # 可选,导入日志配置接口 set_logger_level("info") # 可选,调整日志输出等级,配置为info时,启动量化任务后将打屏显示量化调优的日志信息 config = QuantConfig() # 使用QuantConfig接口,配置量化参数,并返回量化配置实例,当前示例使用默认配置 input_model_path = "./resnet50_official.onnx" # 配置待量化模型的输入路径,请根据实际路径配置 output_model_path = "./resnet50_official_quant.onnx" # 配置量化后模型的名称及输出路径,请根据实际路径配置 calib = OnnxCalibrator(input_model_path, config) # 使用OnnxCalibrator接口,输入待量化模型路径,量化配置数据,生成calib量化任务实例,其中calib_data为可选配置,可参考精度保持策略的方式三输入真实的数据 calib.run() # 执行量化 calib.export_quant_onnx(output_model_path) # 导出量化后模型 - 启动模型量化调优任务,并在指定的输出目录获取一个量化完成的模型。
python3 resnet50_quant.py
- 量化后的ONNX模型可参考README中“模型推理”章节,将ONNX模型转换为OM模型,并进行精度验证。若精度损失超过预期,可参考精度保持策略减少精度损失。
动态shape模型量化步骤(以YoloV5m为例)
- 用户需自行准备模型。以YoloV5m为例,可参考对应README中“模型推理”章节,获取6.1版本YoloV5m模型的权重文件后,并配置模型推理方式为nms_script,导出动态shape的onnx文件,导出命令参考如下:
bash pth2onnx.sh --tag 6.1 --model yolov5m --nms_mode nms_script
- 新建模型的量化脚本yolov5m_quant.py,编辑yolov5m_quant.py文件,导入如下样例代码。
from modelslim.onnx.squant_ptq import OnnxCalibrator, QuantConfig # 导入squant_ptq量化接口 from modelslim import set_logger_level # 可选,导入日志配置接口 set_logger_level("info") # 可选,调整日志输出等级,配置为info时,启动量化任务后将打屏显示量化调优的日志信息 config = QuantConfig(is_dynamic_shape = True, input_shape = [[1,3,640,640]]) # 使用QuantConfig接口,配置量化参数,返回量化配置实例,其中is_dynamic_shape和input_shape参数在动态shape场景下必须配置,其余参数使用默认配置 input_model_path = "./yolov5m.onnx" # 配置待量化模型的输入路径,请根据实际路径配置 output_model_path = "./yolov5m_quant.onnx" # 配置量化后模型的名称及输出路径,请根据实际路径配置 calib = OnnxCalibrator(input_model_path, config) # 使用OnnxCalibrator接口,输入待量化模型路径,量化配置数据,生成calib量化任务实例,其中calib_data为可选配置,可参考精度保持策略的方式三输入真实的数据 calib.run() # 执行量化 calib.export_quant_onnx(output_model_path) # 导出量化后模型 - 启动模型量化调优任务,并在指定的输出目录获取一个量化完成的模型。
python3 yolov5m_quant.py
- 量化后的ONNX模型可参考README中“模型推理”章节,将ONNX模型转换为OM模型,并进行精度验证。若精度损失超过预期,可参考精度保持策略减少精度损失。
精度保持策略
为了进一步降低量化精度损失,Data-Free模式下集成了多种精度保持方式,具体如下:
- 方式一(推荐):如果量化精度不达标,可使用精度保持策略来恢复精度。工具内集成了多种精度保持策略,对权重的量化参数和取证方式进行优化,可在keep_acc参数中配置优化策略恢复精度。当sigma参数配置为0时,即开启activation min-max量化,不建议同时使用keep_acc参数配置的优化策略。keep_acc的配置示例如下:
config = QuantConfig(quant_mode=0, keep_acc={'admm': [False, 1000], 'easy_quant': [True, 1000], 'round_opt': False} ) - 方式二:为保证精度,模型分类层和输入层不推荐量化,可在disable_names中配置分类层和输入层名称。
- 方式三:若使用虚拟数据在Data-Free量化后的精度不达标,可以输入随机真实数据进行量化。比如输入其他数据集的一张图片或一条语句来当随机数据,由于真实数据的数据分布更优,精度也会有所提升。以输入一张真实图片为例,可参考如下代码对数据进行预处理,在量化步骤中作为calib_data传入。
def get_calib_data(): import cv2 import numpy as np img = cv2.imread('/xxx/cat.jpg') img_data = cv2.resize(img, (224, 224)) img_data = img_data[:, :, ::-1].transpose(2, 0, 1).astype(np.float32) img_data /= 255. img_data = np.expand_dims(img_data, axis=0) return [[img_data]]
父主题: 训练后量化(ONNX)